mirror of
https://github.com/rasbt/LLMs-from-scratch.git
synced 2025-12-18 10:42:08 +00:00
Add chatpgpt-like user interface (#360)
* Add chatpgpt-like user interface * fixes
This commit is contained in:
parent
53d61d8d94
commit
1bc560fb13
5
.gitignore
vendored
5
.gitignore
vendored
@ -33,6 +33,7 @@ ch05/02_alternative_weight_loading/checkpoints
|
|||||||
ch05/01_main-chapter-code/model.pth
|
ch05/01_main-chapter-code/model.pth
|
||||||
ch05/01_main-chapter-code/model_and_optimizer.pth
|
ch05/01_main-chapter-code/model_and_optimizer.pth
|
||||||
ch05/03_bonus_pretraining_on_gutenberg/model_checkpoints
|
ch05/03_bonus_pretraining_on_gutenberg/model_checkpoints
|
||||||
|
ch05/06_user_interface/gpt2
|
||||||
|
|
||||||
ch06/01_main-chapter-code/gpt2
|
ch06/01_main-chapter-code/gpt2
|
||||||
ch06/02_bonus_additional-experiments/gpt2
|
ch06/02_bonus_additional-experiments/gpt2
|
||||||
@ -88,6 +89,10 @@ ch07/02_dataset-utilities/instruction-examples-modified.json
|
|||||||
ch07/04_preference-tuning-with-dpo/gpt2-medium355M-sft.pth
|
ch07/04_preference-tuning-with-dpo/gpt2-medium355M-sft.pth
|
||||||
ch07/04_preference-tuning-with-dpo/loss-plot.pdf
|
ch07/04_preference-tuning-with-dpo/loss-plot.pdf
|
||||||
|
|
||||||
|
# Other
|
||||||
|
ch05/06_user_interface/chainlit.md
|
||||||
|
ch05/06_user_interface/.chainlit
|
||||||
|
|
||||||
# Temporary OS-related files
|
# Temporary OS-related files
|
||||||
.DS_Store
|
.DS_Store
|
||||||
|
|
||||||
|
|||||||
@ -116,6 +116,7 @@ Several folders contain optional materials as a bonus for interested readers:
|
|||||||
- [Pretraining GPT on the Project Gutenberg Dataset](ch05/03_bonus_pretraining_on_gutenberg)
|
- [Pretraining GPT on the Project Gutenberg Dataset](ch05/03_bonus_pretraining_on_gutenberg)
|
||||||
- [Adding Bells and Whistles to the Training Loop](ch05/04_learning_rate_schedulers)
|
- [Adding Bells and Whistles to the Training Loop](ch05/04_learning_rate_schedulers)
|
||||||
- [Optimizing Hyperparameters for Pretraining](ch05/05_bonus_hparam_tuning)
|
- [Optimizing Hyperparameters for Pretraining](ch05/05_bonus_hparam_tuning)
|
||||||
|
- [Building a User Interface to Interact With the Pretrained LLM](ch05/06_user_interface)
|
||||||
- **Chapter 6:**
|
- **Chapter 6:**
|
||||||
- [Additional experiments finetuning different layers and using larger models](ch06/02_bonus_additional-experiments)
|
- [Additional experiments finetuning different layers and using larger models](ch06/02_bonus_additional-experiments)
|
||||||
- [Finetuning different models on 50k IMDB movie review dataset](ch06/03_bonus_imdb-classification)
|
- [Finetuning different models on 50k IMDB movie review dataset](ch06/03_bonus_imdb-classification)
|
||||||
|
|||||||
@ -2504,7 +2504,7 @@
|
|||||||
"name": "python",
|
"name": "python",
|
||||||
"nbconvert_exporter": "python",
|
"nbconvert_exporter": "python",
|
||||||
"pygments_lexer": "ipython3",
|
"pygments_lexer": "ipython3",
|
||||||
"version": "3.12.2"
|
"version": "3.10.6"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"nbformat": 4,
|
"nbformat": 4,
|
||||||
|
|||||||
48
ch05/06_user_interface/README.md
Normal file
48
ch05/06_user_interface/README.md
Normal file
@ -0,0 +1,48 @@
|
|||||||
|
# Building a User Interface to Interact With the Pretrained LLM
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
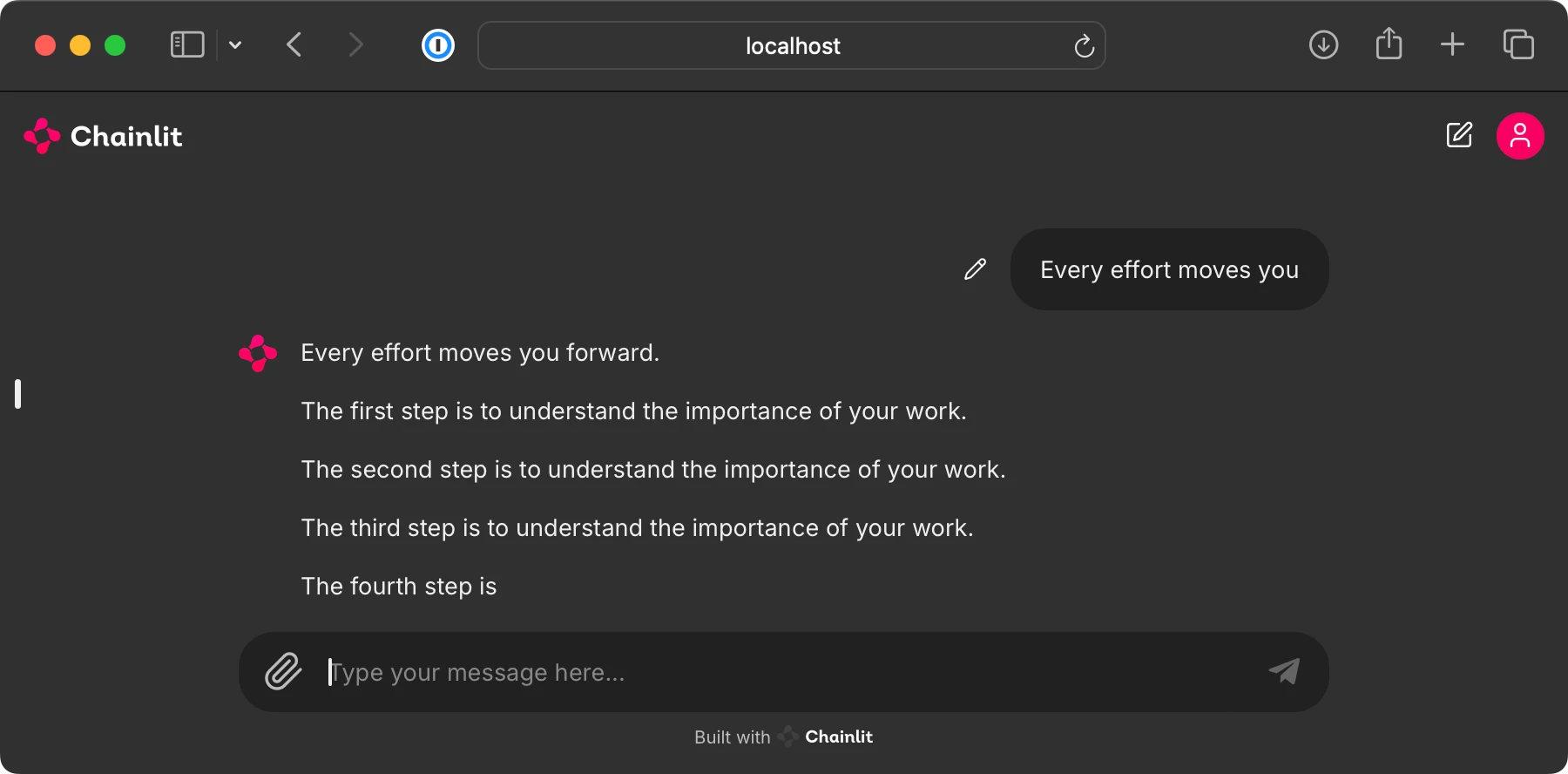
This bonus folder contains code for running a ChatGPT-like user interface to interact with the pretrained LLMs from chapter 5, as shown below.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
To implement this user interface, we use the open-source [Chainlit Python package](https://github.com/Chainlit/chainlit).
|
||||||
|
|
||||||
|
|
||||||
|
## Step 1: Install dependencies
|
||||||
|
|
||||||
|
First, we install the `chainlit` package via
|
||||||
|
|
||||||
|
```python
|
||||||
|
pip install chainlit
|
||||||
|
```
|
||||||
|
|
||||||
|
(Alternatively, execute `pip install -r requirements-extra.txt`.)
|
||||||
|
|
||||||
|
|
||||||
|
## Step 2: Run `app` code
|
||||||
|
|
||||||
|
This folder contains 2 files:
|
||||||
|
|
||||||
|
1. [`app_orig.py`](app_orig.py): This file loads and uses the original GPT-2 weights from OpenAI.
|
||||||
|
2. [`app_own.py`](app_own.py): This file loads and uses the GPT-2 weights we generated in chapter 5. This requires that you execute the [`../01_main-chapter-code/ch05.ipynb`] file first.
|
||||||
|
|
||||||
|
(Open and inspect these files to learn more.)
|
||||||
|
|
||||||
|
Run one of the following commands from the terminal to start the UI server:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
chainlit run app_orig.py
|
||||||
|
```
|
||||||
|
|
||||||
|
or
|
||||||
|
|
||||||
|
```bash
|
||||||
|
chainlit run app_own.py
|
||||||
|
```
|
||||||
|
|
||||||
|
Running one of the commands above should open a new browser tab where you can interact with the model. If the browser tab does not open automatically, inspect the terminal command and copy the local address into your browser address bar (usually, the address is `http://localhost:8000`).
|
||||||
83
ch05/06_user_interface/app_orig.py
Normal file
83
ch05/06_user_interface/app_orig.py
Normal file
@ -0,0 +1,83 @@
|
|||||||
|
# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
|
||||||
|
# Source for "Build a Large Language Model From Scratch"
|
||||||
|
# - https://www.manning.com/books/build-a-large-language-model-from-scratch
|
||||||
|
# Code: https://github.com/rasbt/LLMs-from-scratch
|
||||||
|
|
||||||
|
import tiktoken
|
||||||
|
import torch
|
||||||
|
import chainlit
|
||||||
|
|
||||||
|
from previous_chapters import (
|
||||||
|
download_and_load_gpt2,
|
||||||
|
generate,
|
||||||
|
GPTModel,
|
||||||
|
load_weights_into_gpt,
|
||||||
|
text_to_token_ids,
|
||||||
|
token_ids_to_text,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def get_model_and_tokenizer():
|
||||||
|
"""
|
||||||
|
Code to loads a GPT-2 model with pretrained weights from OpenAI.
|
||||||
|
The code is similar to chapter 5.
|
||||||
|
The model will be downloaded automatically if it doesn't exist in the current folder, yet.
|
||||||
|
"""
|
||||||
|
|
||||||
|
CHOOSE_MODEL = "gpt2-small (124M)" # Optionally replace with another model from the model_configs dir below
|
||||||
|
|
||||||
|
BASE_CONFIG = {
|
||||||
|
"vocab_size": 50257, # Vocabulary size
|
||||||
|
"context_length": 1024, # Context length
|
||||||
|
"drop_rate": 0.0, # Dropout rate
|
||||||
|
"qkv_bias": True # Query-key-value bias
|
||||||
|
}
|
||||||
|
|
||||||
|
model_configs = {
|
||||||
|
"gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
|
||||||
|
"gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
|
||||||
|
"gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
|
||||||
|
"gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
|
||||||
|
}
|
||||||
|
|
||||||
|
model_size = CHOOSE_MODEL.split(" ")[-1].lstrip("(").rstrip(")")
|
||||||
|
|
||||||
|
BASE_CONFIG.update(model_configs[CHOOSE_MODEL])
|
||||||
|
|
||||||
|
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||||
|
|
||||||
|
settings, params = download_and_load_gpt2(model_size=model_size, models_dir="gpt2")
|
||||||
|
|
||||||
|
gpt = GPTModel(BASE_CONFIG)
|
||||||
|
load_weights_into_gpt(gpt, params)
|
||||||
|
gpt.to(device)
|
||||||
|
gpt.eval()
|
||||||
|
|
||||||
|
tokenizer = tiktoken.get_encoding("gpt2")
|
||||||
|
|
||||||
|
return tokenizer, gpt, BASE_CONFIG
|
||||||
|
|
||||||
|
|
||||||
|
# Obtain the necessary tokenizer and model files for the chainlit function below
|
||||||
|
tokenizer, model, model_config = get_model_and_tokenizer()
|
||||||
|
|
||||||
|
|
||||||
|
@chainlit.on_message
|
||||||
|
async def main(message: chainlit.Message):
|
||||||
|
"""
|
||||||
|
The main Chainlit function.
|
||||||
|
"""
|
||||||
|
token_ids = generate(
|
||||||
|
model=model,
|
||||||
|
idx=text_to_token_ids(message.content, tokenizer), # The user text is provided via as `message.content`
|
||||||
|
max_new_tokens=50,
|
||||||
|
context_size=model_config["context_length"],
|
||||||
|
top_k=1,
|
||||||
|
temperature=0.0
|
||||||
|
)
|
||||||
|
|
||||||
|
text = token_ids_to_text(token_ids, tokenizer)
|
||||||
|
|
||||||
|
await chainlit.Message(
|
||||||
|
content=f"{text}", # This returns the model response to the interface
|
||||||
|
).send()
|
||||||
76
ch05/06_user_interface/app_own.py
Normal file
76
ch05/06_user_interface/app_own.py
Normal file
@ -0,0 +1,76 @@
|
|||||||
|
# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
|
||||||
|
# Source for "Build a Large Language Model From Scratch"
|
||||||
|
# - https://www.manning.com/books/build-a-large-language-model-from-scratch
|
||||||
|
# Code: https://github.com/rasbt/LLMs-from-scratch
|
||||||
|
|
||||||
|
from pathlib import Path
|
||||||
|
import sys
|
||||||
|
|
||||||
|
import tiktoken
|
||||||
|
import torch
|
||||||
|
import chainlit
|
||||||
|
|
||||||
|
from previous_chapters import (
|
||||||
|
generate,
|
||||||
|
GPTModel,
|
||||||
|
text_to_token_ids,
|
||||||
|
token_ids_to_text,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def get_model_and_tokenizer():
|
||||||
|
"""
|
||||||
|
Code to loads a GPT-2 model with pretrained weights generated in chapter 5.
|
||||||
|
This requires that you run the code in chapter 5 first, which generates the necessary model.pth file.
|
||||||
|
"""
|
||||||
|
|
||||||
|
GPT_CONFIG_124M = {
|
||||||
|
"vocab_size": 50257, # Vocabulary size
|
||||||
|
"context_length": 256, # Shortened context length (orig: 1024)
|
||||||
|
"emb_dim": 768, # Embedding dimension
|
||||||
|
"n_heads": 12, # Number of attention heads
|
||||||
|
"n_layers": 12, # Number of layers
|
||||||
|
"drop_rate": 0.1, # Dropout rate
|
||||||
|
"qkv_bias": False # Query-key-value bias
|
||||||
|
}
|
||||||
|
|
||||||
|
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||||
|
|
||||||
|
tokenizer = tiktoken.get_encoding("gpt2")
|
||||||
|
|
||||||
|
model_path = Path("..") / "01_main-chapter-code" / "model.pth"
|
||||||
|
if not model_path.exists():
|
||||||
|
print(f"Could not find the {model_path} file. Please run the chapter 5 code (ch05.ipynb) to generate the model.pth file.")
|
||||||
|
sys.exit()
|
||||||
|
|
||||||
|
checkpoint = torch.load("model.pth", weights_only=True)
|
||||||
|
model = GPTModel(GPT_CONFIG_124M)
|
||||||
|
model.load_state_dict(checkpoint)
|
||||||
|
model.to(device)
|
||||||
|
|
||||||
|
return tokenizer, model, GPT_CONFIG_124M
|
||||||
|
|
||||||
|
|
||||||
|
# Obtain the necessary tokenizer and model files for the chainlit function below
|
||||||
|
tokenizer, model, model_config = get_model_and_tokenizer()
|
||||||
|
|
||||||
|
|
||||||
|
@chainlit.on_message
|
||||||
|
async def main(message: chainlit.Message):
|
||||||
|
"""
|
||||||
|
The main Chainlit function.
|
||||||
|
"""
|
||||||
|
token_ids = generate(
|
||||||
|
model=model,
|
||||||
|
idx=text_to_token_ids(message.content, tokenizer), # The user text is provided via as `message.content`
|
||||||
|
max_new_tokens=50,
|
||||||
|
context_size=model_config["context_length"],
|
||||||
|
top_k=1,
|
||||||
|
temperature=0.0
|
||||||
|
)
|
||||||
|
|
||||||
|
text = token_ids_to_text(token_ids, tokenizer)
|
||||||
|
|
||||||
|
await chainlit.Message(
|
||||||
|
content=f"{text}", # This returns the model response to the interface
|
||||||
|
).send()
|
||||||
454
ch05/06_user_interface/previous_chapters.py
Normal file
454
ch05/06_user_interface/previous_chapters.py
Normal file
@ -0,0 +1,454 @@
|
|||||||
|
# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
|
||||||
|
# Source for "Build a Large Language Model From Scratch"
|
||||||
|
# - https://www.manning.com/books/build-a-large-language-model-from-scratch
|
||||||
|
# Code: https://github.com/rasbt/LLMs-from-scratch
|
||||||
|
#
|
||||||
|
# This file collects all the relevant code that we covered thus far
|
||||||
|
# throughout Chapters 2-5.
|
||||||
|
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
import urllib
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import tensorflow as tf
|
||||||
|
import tiktoken
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
from torch.utils.data import Dataset, DataLoader
|
||||||
|
from tqdm import tqdm
|
||||||
|
|
||||||
|
|
||||||
|
#####################################
|
||||||
|
# Chapter 2
|
||||||
|
#####################################
|
||||||
|
|
||||||
|
|
||||||
|
class GPTDatasetV1(Dataset):
|
||||||
|
def __init__(self, txt, tokenizer, max_length, stride):
|
||||||
|
self.input_ids = []
|
||||||
|
self.target_ids = []
|
||||||
|
|
||||||
|
# Tokenize the entire text
|
||||||
|
token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"})
|
||||||
|
|
||||||
|
# Use a sliding window to chunk the book into overlapping sequences of max_length
|
||||||
|
for i in range(0, len(token_ids) - max_length, stride):
|
||||||
|
input_chunk = token_ids[i:i + max_length]
|
||||||
|
target_chunk = token_ids[i + 1: i + max_length + 1]
|
||||||
|
self.input_ids.append(torch.tensor(input_chunk))
|
||||||
|
self.target_ids.append(torch.tensor(target_chunk))
|
||||||
|
|
||||||
|
def __len__(self):
|
||||||
|
return len(self.input_ids)
|
||||||
|
|
||||||
|
def __getitem__(self, idx):
|
||||||
|
return self.input_ids[idx], self.target_ids[idx]
|
||||||
|
|
||||||
|
|
||||||
|
def create_dataloader_v1(txt, batch_size=4, max_length=256,
|
||||||
|
stride=128, shuffle=True, drop_last=True, num_workers=0):
|
||||||
|
# Initialize the tokenizer
|
||||||
|
tokenizer = tiktoken.get_encoding("gpt2")
|
||||||
|
|
||||||
|
# Create dataset
|
||||||
|
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
|
||||||
|
|
||||||
|
# Create dataloader
|
||||||
|
dataloader = DataLoader(
|
||||||
|
dataset, batch_size=batch_size, shuffle=shuffle, drop_last=drop_last, num_workers=num_workers)
|
||||||
|
|
||||||
|
return dataloader
|
||||||
|
|
||||||
|
|
||||||
|
#####################################
|
||||||
|
# Chapter 3
|
||||||
|
#####################################
|
||||||
|
class MultiHeadAttention(nn.Module):
|
||||||
|
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
|
||||||
|
super().__init__()
|
||||||
|
assert d_out % num_heads == 0, "d_out must be divisible by n_heads"
|
||||||
|
|
||||||
|
self.d_out = d_out
|
||||||
|
self.num_heads = num_heads
|
||||||
|
self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim
|
||||||
|
|
||||||
|
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
|
||||||
|
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
|
||||||
|
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
|
||||||
|
self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs
|
||||||
|
self.dropout = nn.Dropout(dropout)
|
||||||
|
self.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1))
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
b, num_tokens, d_in = x.shape
|
||||||
|
|
||||||
|
keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
|
||||||
|
queries = self.W_query(x)
|
||||||
|
values = self.W_value(x)
|
||||||
|
|
||||||
|
# We implicitly split the matrix by adding a `num_heads` dimension
|
||||||
|
# Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)
|
||||||
|
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
|
||||||
|
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
|
||||||
|
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
|
||||||
|
|
||||||
|
# Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)
|
||||||
|
keys = keys.transpose(1, 2)
|
||||||
|
queries = queries.transpose(1, 2)
|
||||||
|
values = values.transpose(1, 2)
|
||||||
|
|
||||||
|
# Compute scaled dot-product attention (aka self-attention) with a causal mask
|
||||||
|
attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
|
||||||
|
|
||||||
|
# Original mask truncated to the number of tokens and converted to boolean
|
||||||
|
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
|
||||||
|
|
||||||
|
# Use the mask to fill attention scores
|
||||||
|
attn_scores.masked_fill_(mask_bool, -torch.inf)
|
||||||
|
|
||||||
|
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
|
||||||
|
attn_weights = self.dropout(attn_weights)
|
||||||
|
|
||||||
|
# Shape: (b, num_tokens, num_heads, head_dim)
|
||||||
|
context_vec = (attn_weights @ values).transpose(1, 2)
|
||||||
|
|
||||||
|
# Combine heads, where self.d_out = self.num_heads * self.head_dim
|
||||||
|
context_vec = context_vec.reshape(b, num_tokens, self.d_out)
|
||||||
|
context_vec = self.out_proj(context_vec) # optional projection
|
||||||
|
|
||||||
|
return context_vec
|
||||||
|
|
||||||
|
|
||||||
|
#####################################
|
||||||
|
# Chapter 4
|
||||||
|
#####################################
|
||||||
|
class LayerNorm(nn.Module):
|
||||||
|
def __init__(self, emb_dim):
|
||||||
|
super().__init__()
|
||||||
|
self.eps = 1e-5
|
||||||
|
self.scale = nn.Parameter(torch.ones(emb_dim))
|
||||||
|
self.shift = nn.Parameter(torch.zeros(emb_dim))
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
mean = x.mean(dim=-1, keepdim=True)
|
||||||
|
var = x.var(dim=-1, keepdim=True, unbiased=False)
|
||||||
|
norm_x = (x - mean) / torch.sqrt(var + self.eps)
|
||||||
|
return self.scale * norm_x + self.shift
|
||||||
|
|
||||||
|
|
||||||
|
class GELU(nn.Module):
|
||||||
|
def __init__(self):
|
||||||
|
super().__init__()
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
return 0.5 * x * (1 + torch.tanh(
|
||||||
|
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
|
||||||
|
(x + 0.044715 * torch.pow(x, 3))
|
||||||
|
))
|
||||||
|
|
||||||
|
|
||||||
|
class FeedForward(nn.Module):
|
||||||
|
def __init__(self, cfg):
|
||||||
|
super().__init__()
|
||||||
|
self.layers = nn.Sequential(
|
||||||
|
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
|
||||||
|
GELU(),
|
||||||
|
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
|
||||||
|
)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
return self.layers(x)
|
||||||
|
|
||||||
|
|
||||||
|
class TransformerBlock(nn.Module):
|
||||||
|
def __init__(self, cfg):
|
||||||
|
super().__init__()
|
||||||
|
self.att = MultiHeadAttention(
|
||||||
|
d_in=cfg["emb_dim"],
|
||||||
|
d_out=cfg["emb_dim"],
|
||||||
|
context_length=cfg["context_length"],
|
||||||
|
num_heads=cfg["n_heads"],
|
||||||
|
dropout=cfg["drop_rate"],
|
||||||
|
qkv_bias=cfg["qkv_bias"])
|
||||||
|
self.ff = FeedForward(cfg)
|
||||||
|
self.norm1 = LayerNorm(cfg["emb_dim"])
|
||||||
|
self.norm2 = LayerNorm(cfg["emb_dim"])
|
||||||
|
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
# Shortcut connection for attention block
|
||||||
|
shortcut = x
|
||||||
|
x = self.norm1(x)
|
||||||
|
x = self.att(x) # Shape [batch_size, num_tokens, emb_size]
|
||||||
|
x = self.drop_shortcut(x)
|
||||||
|
x = x + shortcut # Add the original input back
|
||||||
|
|
||||||
|
# Shortcut connection for feed-forward block
|
||||||
|
shortcut = x
|
||||||
|
x = self.norm2(x)
|
||||||
|
x = self.ff(x)
|
||||||
|
x = self.drop_shortcut(x)
|
||||||
|
x = x + shortcut # Add the original input back
|
||||||
|
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
class GPTModel(nn.Module):
|
||||||
|
def __init__(self, cfg):
|
||||||
|
super().__init__()
|
||||||
|
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
|
||||||
|
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
|
||||||
|
self.drop_emb = nn.Dropout(cfg["drop_rate"])
|
||||||
|
|
||||||
|
self.trf_blocks = nn.Sequential(
|
||||||
|
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
|
||||||
|
|
||||||
|
self.final_norm = LayerNorm(cfg["emb_dim"])
|
||||||
|
self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False)
|
||||||
|
|
||||||
|
def forward(self, in_idx):
|
||||||
|
batch_size, seq_len = in_idx.shape
|
||||||
|
tok_embeds = self.tok_emb(in_idx)
|
||||||
|
pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
|
||||||
|
x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]
|
||||||
|
x = self.drop_emb(x)
|
||||||
|
x = self.trf_blocks(x)
|
||||||
|
x = self.final_norm(x)
|
||||||
|
logits = self.out_head(x)
|
||||||
|
return logits
|
||||||
|
|
||||||
|
|
||||||
|
def generate_text_simple(model, idx, max_new_tokens, context_size):
|
||||||
|
# idx is (B, T) array of indices in the current context
|
||||||
|
for _ in range(max_new_tokens):
|
||||||
|
|
||||||
|
# Crop current context if it exceeds the supported context size
|
||||||
|
# E.g., if LLM supports only 5 tokens, and the context size is 10
|
||||||
|
# then only the last 5 tokens are used as context
|
||||||
|
idx_cond = idx[:, -context_size:]
|
||||||
|
|
||||||
|
# Get the predictions
|
||||||
|
with torch.no_grad():
|
||||||
|
logits = model(idx_cond)
|
||||||
|
|
||||||
|
# Focus only on the last time step
|
||||||
|
# (batch, n_token, vocab_size) becomes (batch, vocab_size)
|
||||||
|
logits = logits[:, -1, :]
|
||||||
|
|
||||||
|
# Get the idx of the vocab entry with the highest logits value
|
||||||
|
idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch, 1)
|
||||||
|
|
||||||
|
# Append sampled index to the running sequence
|
||||||
|
idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)
|
||||||
|
|
||||||
|
return idx
|
||||||
|
|
||||||
|
|
||||||
|
#####################################
|
||||||
|
# Chapter 5
|
||||||
|
#####################################
|
||||||
|
def text_to_token_ids(text, tokenizer):
|
||||||
|
encoded = tokenizer.encode(text)
|
||||||
|
encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension
|
||||||
|
return encoded_tensor
|
||||||
|
|
||||||
|
|
||||||
|
def token_ids_to_text(token_ids, tokenizer):
|
||||||
|
flat = token_ids.squeeze(0) # remove batch dimension
|
||||||
|
return tokenizer.decode(flat.tolist())
|
||||||
|
|
||||||
|
|
||||||
|
def download_and_load_gpt2(model_size, models_dir):
|
||||||
|
# Validate model size
|
||||||
|
allowed_sizes = ("124M", "355M", "774M", "1558M")
|
||||||
|
if model_size not in allowed_sizes:
|
||||||
|
raise ValueError(f"Model size not in {allowed_sizes}")
|
||||||
|
|
||||||
|
# Define paths
|
||||||
|
model_dir = os.path.join(models_dir, model_size)
|
||||||
|
base_url = "https://openaipublic.blob.core.windows.net/gpt-2/models"
|
||||||
|
filenames = [
|
||||||
|
"checkpoint", "encoder.json", "hparams.json",
|
||||||
|
"model.ckpt.data-00000-of-00001", "model.ckpt.index",
|
||||||
|
"model.ckpt.meta", "vocab.bpe"
|
||||||
|
]
|
||||||
|
|
||||||
|
# Download files
|
||||||
|
os.makedirs(model_dir, exist_ok=True)
|
||||||
|
for filename in filenames:
|
||||||
|
file_url = os.path.join(base_url, model_size, filename)
|
||||||
|
file_path = os.path.join(model_dir, filename)
|
||||||
|
download_file(file_url, file_path)
|
||||||
|
|
||||||
|
# Load settings and params
|
||||||
|
tf_ckpt_path = tf.train.latest_checkpoint(model_dir)
|
||||||
|
settings = json.load(open(os.path.join(model_dir, "hparams.json")))
|
||||||
|
params = load_gpt2_params_from_tf_ckpt(tf_ckpt_path, settings)
|
||||||
|
|
||||||
|
return settings, params
|
||||||
|
|
||||||
|
|
||||||
|
def download_file(url, destination):
|
||||||
|
# Send a GET request to download the file
|
||||||
|
with urllib.request.urlopen(url) as response:
|
||||||
|
# Get the total file size from headers, defaulting to 0 if not present
|
||||||
|
file_size = int(response.headers.get("Content-Length", 0))
|
||||||
|
|
||||||
|
# Check if file exists and has the same size
|
||||||
|
if os.path.exists(destination):
|
||||||
|
file_size_local = os.path.getsize(destination)
|
||||||
|
if file_size == file_size_local:
|
||||||
|
print(f"File already exists and is up-to-date: {destination}")
|
||||||
|
return
|
||||||
|
|
||||||
|
# Define the block size for reading the file
|
||||||
|
block_size = 1024 # 1 Kilobyte
|
||||||
|
|
||||||
|
# Initialize the progress bar with total file size
|
||||||
|
progress_bar_description = os.path.basename(url) # Extract filename from URL
|
||||||
|
with tqdm(total=file_size, unit="iB", unit_scale=True, desc=progress_bar_description) as progress_bar:
|
||||||
|
# Open the destination file in binary write mode
|
||||||
|
with open(destination, "wb") as file:
|
||||||
|
# Read the file in chunks and write to destination
|
||||||
|
while True:
|
||||||
|
chunk = response.read(block_size)
|
||||||
|
if not chunk:
|
||||||
|
break
|
||||||
|
file.write(chunk)
|
||||||
|
progress_bar.update(len(chunk)) # Update progress bar
|
||||||
|
|
||||||
|
|
||||||
|
def load_gpt2_params_from_tf_ckpt(ckpt_path, settings):
|
||||||
|
# Initialize parameters dictionary with empty blocks for each layer
|
||||||
|
params = {"blocks": [{} for _ in range(settings["n_layer"])]}
|
||||||
|
|
||||||
|
# Iterate over each variable in the checkpoint
|
||||||
|
for name, _ in tf.train.list_variables(ckpt_path):
|
||||||
|
# Load the variable and remove singleton dimensions
|
||||||
|
variable_array = np.squeeze(tf.train.load_variable(ckpt_path, name))
|
||||||
|
|
||||||
|
# Process the variable name to extract relevant parts
|
||||||
|
variable_name_parts = name.split("/")[1:] # Skip the 'model/' prefix
|
||||||
|
|
||||||
|
# Identify the target dictionary for the variable
|
||||||
|
target_dict = params
|
||||||
|
if variable_name_parts[0].startswith("h"):
|
||||||
|
layer_number = int(variable_name_parts[0][1:])
|
||||||
|
target_dict = params["blocks"][layer_number]
|
||||||
|
|
||||||
|
# Recursively access or create nested dictionaries
|
||||||
|
for key in variable_name_parts[1:-1]:
|
||||||
|
target_dict = target_dict.setdefault(key, {})
|
||||||
|
|
||||||
|
# Assign the variable array to the last key
|
||||||
|
last_key = variable_name_parts[-1]
|
||||||
|
target_dict[last_key] = variable_array
|
||||||
|
|
||||||
|
return params
|
||||||
|
|
||||||
|
|
||||||
|
def assign(left, right):
|
||||||
|
if left.shape != right.shape:
|
||||||
|
raise ValueError(f"Shape mismatch. Left: {left.shape}, Right: {right.shape}")
|
||||||
|
return torch.nn.Parameter(torch.tensor(right))
|
||||||
|
|
||||||
|
|
||||||
|
def load_weights_into_gpt(gpt, params):
|
||||||
|
gpt.pos_emb.weight = assign(gpt.pos_emb.weight, params['wpe'])
|
||||||
|
gpt.tok_emb.weight = assign(gpt.tok_emb.weight, params['wte'])
|
||||||
|
|
||||||
|
for b in range(len(params["blocks"])):
|
||||||
|
q_w, k_w, v_w = np.split(
|
||||||
|
(params["blocks"][b]["attn"]["c_attn"])["w"], 3, axis=-1)
|
||||||
|
gpt.trf_blocks[b].att.W_query.weight = assign(
|
||||||
|
gpt.trf_blocks[b].att.W_query.weight, q_w.T)
|
||||||
|
gpt.trf_blocks[b].att.W_key.weight = assign(
|
||||||
|
gpt.trf_blocks[b].att.W_key.weight, k_w.T)
|
||||||
|
gpt.trf_blocks[b].att.W_value.weight = assign(
|
||||||
|
gpt.trf_blocks[b].att.W_value.weight, v_w.T)
|
||||||
|
|
||||||
|
q_b, k_b, v_b = np.split(
|
||||||
|
(params["blocks"][b]["attn"]["c_attn"])["b"], 3, axis=-1)
|
||||||
|
gpt.trf_blocks[b].att.W_query.bias = assign(
|
||||||
|
gpt.trf_blocks[b].att.W_query.bias, q_b)
|
||||||
|
gpt.trf_blocks[b].att.W_key.bias = assign(
|
||||||
|
gpt.trf_blocks[b].att.W_key.bias, k_b)
|
||||||
|
gpt.trf_blocks[b].att.W_value.bias = assign(
|
||||||
|
gpt.trf_blocks[b].att.W_value.bias, v_b)
|
||||||
|
|
||||||
|
gpt.trf_blocks[b].att.out_proj.weight = assign(
|
||||||
|
gpt.trf_blocks[b].att.out_proj.weight,
|
||||||
|
params["blocks"][b]["attn"]["c_proj"]["w"].T)
|
||||||
|
gpt.trf_blocks[b].att.out_proj.bias = assign(
|
||||||
|
gpt.trf_blocks[b].att.out_proj.bias,
|
||||||
|
params["blocks"][b]["attn"]["c_proj"]["b"])
|
||||||
|
|
||||||
|
gpt.trf_blocks[b].ff.layers[0].weight = assign(
|
||||||
|
gpt.trf_blocks[b].ff.layers[0].weight,
|
||||||
|
params["blocks"][b]["mlp"]["c_fc"]["w"].T)
|
||||||
|
gpt.trf_blocks[b].ff.layers[0].bias = assign(
|
||||||
|
gpt.trf_blocks[b].ff.layers[0].bias,
|
||||||
|
params["blocks"][b]["mlp"]["c_fc"]["b"])
|
||||||
|
gpt.trf_blocks[b].ff.layers[2].weight = assign(
|
||||||
|
gpt.trf_blocks[b].ff.layers[2].weight,
|
||||||
|
params["blocks"][b]["mlp"]["c_proj"]["w"].T)
|
||||||
|
gpt.trf_blocks[b].ff.layers[2].bias = assign(
|
||||||
|
gpt.trf_blocks[b].ff.layers[2].bias,
|
||||||
|
params["blocks"][b]["mlp"]["c_proj"]["b"])
|
||||||
|
|
||||||
|
gpt.trf_blocks[b].norm1.scale = assign(
|
||||||
|
gpt.trf_blocks[b].norm1.scale,
|
||||||
|
params["blocks"][b]["ln_1"]["g"])
|
||||||
|
gpt.trf_blocks[b].norm1.shift = assign(
|
||||||
|
gpt.trf_blocks[b].norm1.shift,
|
||||||
|
params["blocks"][b]["ln_1"]["b"])
|
||||||
|
gpt.trf_blocks[b].norm2.scale = assign(
|
||||||
|
gpt.trf_blocks[b].norm2.scale,
|
||||||
|
params["blocks"][b]["ln_2"]["g"])
|
||||||
|
gpt.trf_blocks[b].norm2.shift = assign(
|
||||||
|
gpt.trf_blocks[b].norm2.shift,
|
||||||
|
params["blocks"][b]["ln_2"]["b"])
|
||||||
|
|
||||||
|
gpt.final_norm.scale = assign(gpt.final_norm.scale, params["g"])
|
||||||
|
gpt.final_norm.shift = assign(gpt.final_norm.shift, params["b"])
|
||||||
|
gpt.out_head.weight = assign(gpt.out_head.weight, params["wte"])
|
||||||
|
|
||||||
|
|
||||||
|
def generate(model, idx, max_new_tokens, context_size, temperature=0.0, top_k=None, eos_id=None):
|
||||||
|
|
||||||
|
# For-loop is the same as before: Get logits, and only focus on last time step
|
||||||
|
for _ in range(max_new_tokens):
|
||||||
|
idx_cond = idx[:, -context_size:]
|
||||||
|
with torch.no_grad():
|
||||||
|
logits = model(idx_cond)
|
||||||
|
logits = logits[:, -1, :]
|
||||||
|
|
||||||
|
# New: Filter logits with top_k sampling
|
||||||
|
if top_k is not None:
|
||||||
|
# Keep only top_k values
|
||||||
|
top_logits, _ = torch.topk(logits, top_k)
|
||||||
|
min_val = top_logits[:, -1]
|
||||||
|
logits = torch.where(logits < min_val, torch.tensor(float('-inf')).to(logits.device), logits)
|
||||||
|
|
||||||
|
# New: Apply temperature scaling
|
||||||
|
if temperature > 0.0:
|
||||||
|
logits = logits / temperature
|
||||||
|
|
||||||
|
# Apply softmax to get probabilities
|
||||||
|
probs = torch.softmax(logits, dim=-1) # (batch_size, context_len)
|
||||||
|
|
||||||
|
# Sample from the distribution
|
||||||
|
idx_next = torch.multinomial(probs, num_samples=1) # (batch_size, 1)
|
||||||
|
|
||||||
|
# Otherwise same as before: get idx of the vocab entry with the highest logits value
|
||||||
|
else:
|
||||||
|
idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch_size, 1)
|
||||||
|
|
||||||
|
if idx_next == eos_id: # Stop generating early if end-of-sequence token is encountered and eos_id is specified
|
||||||
|
break
|
||||||
|
|
||||||
|
# Same as before: append sampled index to the running sequence
|
||||||
|
idx = torch.cat((idx, idx_next), dim=1) # (batch_size, num_tokens+1)
|
||||||
|
|
||||||
|
return idx
|
||||||
1
ch05/06_user_interface/requirements-extra.txt
Normal file
1
ch05/06_user_interface/requirements-extra.txt
Normal file
@ -0,0 +1 @@
|
|||||||
|
chainlit>=1.2.0
|
||||||
@ -10,4 +10,4 @@
|
|||||||
- [03_bonus_pretraining_on_gutenberg](03_bonus_pretraining_on_gutenberg) contains code to pretrain the LLM longer on the whole corpus of books from Project Gutenberg
|
- [03_bonus_pretraining_on_gutenberg](03_bonus_pretraining_on_gutenberg) contains code to pretrain the LLM longer on the whole corpus of books from Project Gutenberg
|
||||||
- [04_learning_rate_schedulers](04_learning_rate_schedulers) contains code implementing a more sophisticated training function including learning rate schedulers and gradient clipping
|
- [04_learning_rate_schedulers](04_learning_rate_schedulers) contains code implementing a more sophisticated training function including learning rate schedulers and gradient clipping
|
||||||
- [05_bonus_hparam_tuning](05_bonus_hparam_tuning) contains an optional hyperparameter tuning script
|
- [05_bonus_hparam_tuning](05_bonus_hparam_tuning) contains an optional hyperparameter tuning script
|
||||||
|
- [06_user_interface](06_user_interface) implements an interactive user interface to interact with the pretrained LLM
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user