diff --git a/.github/workflows/basic-tests-linux-uv.yml b/.github/workflows/basic-tests-linux-uv.yml
index 35864a8..ab651f0 100644
--- a/.github/workflows/basic-tests-linux-uv.yml
+++ b/.github/workflows/basic-tests-linux-uv.yml
@@ -71,4 +71,5 @@ jobs:
shell: bash
run: |
source .venv/bin/activate
+ uv pip install transformers
pytest pkg/llms_from_scratch/tests/
diff --git a/.github/workflows/check-links.yml b/.github/workflows/check-links.yml
index b35e7f1..a5b57e9 100644
--- a/.github/workflows/check-links.yml
+++ b/.github/workflows/check-links.yml
@@ -24,8 +24,6 @@ jobs:
run: |
curl -LsSf https://astral.sh/uv/install.sh | sh
uv add pytest-ruff pytest-check-links
- # Current version of retry doesn't work well if there are broken non-URL links
- # pip install pytest pytest-check-links pytest-retry
- name: Check links
run: |
@@ -40,5 +38,3 @@ jobs:
--check-links-ignore "https://arxiv.org/*" \
--check-links-ignore "https://ai.stanford.edu/~amaas/data/sentiment/" \
--check-links-ignore "https://x.com/*"
- # pytest --check-links ./ --check-links-ignore "https://platform.openai.com/*" --check-links-ignore "https://arena.lmsys.org" --retries 2 --retry-delay 5
-
diff --git a/ch05/07_gpt_to_llama/README.md b/ch05/07_gpt_to_llama/README.md
index fda7ab7..b158c17 100644
--- a/ch05/07_gpt_to_llama/README.md
+++ b/ch05/07_gpt_to_llama/README.md
@@ -8,4 +8,188 @@ This folder contains code for converting the GPT implementation from chapter 4 a
- [converting-llama2-to-llama3.ipynb](converting-llama2-to-llama3.ipynb): contains code to convert the Llama 2 model to Llama 3, Llama 3.1, and Llama 3.2
- [standalone-llama32.ipynb](standalone-llama32.ipynb): a standalone notebook implementing Llama 3.2
-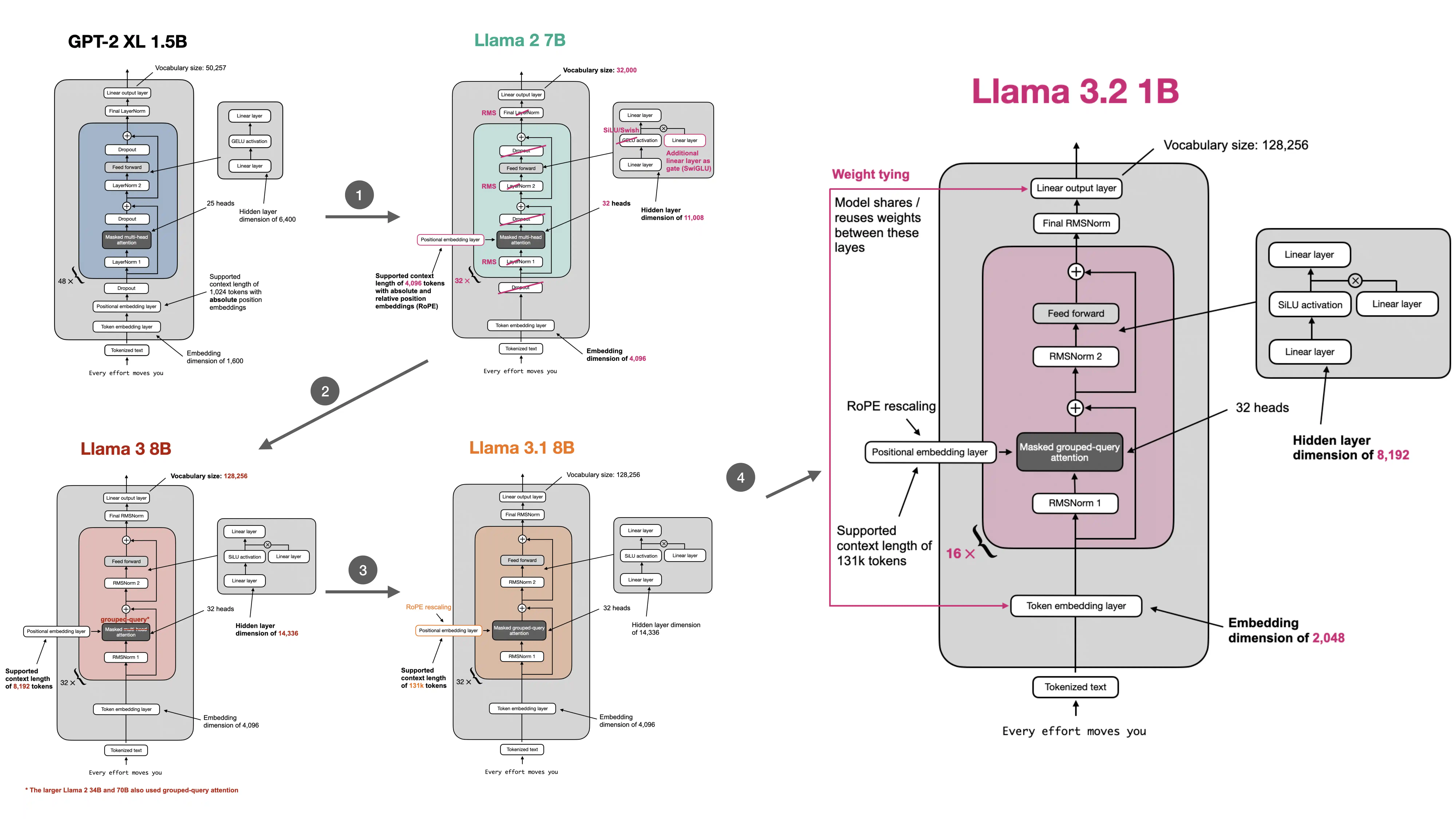 \ No newline at end of file
+
+
+
+
+### Using Llama 3.2 via the `llms-from-scratch` package
+
+For an easy way to use the Llama 3.2 1B and 3B models, you can also use the `llms-from-scratch` PyPI package based on the source code in this repository at [pkg/llms_from_scratch](../../pkg/llms_from_scratch).
+
+
+##### 1) Installation
+
+```bash
+pip install llms_from_scratch blobfile
+```
+
+##### 2) Model and text generation settings
+
+Specify which model to use:
+
+```python
+MODEL_FILE = "llama3.2-1B-instruct.pth"
+# MODEL_FILE = "llama3.2-1B-base.pth"
+# MODEL_FILE = "llama3.2-3B-instruct.pth"
+# MODEL_FILE = "llama3.2-3B-base.pth"
+```
+
+Basic text generation settings that can be defined by the user. Note that the recommended 8192-token context size requires approximately 3 GB of VRAM for the text generation example.
+
+```python
+MODEL_CONTEXT_LENGTH = 8192 # Supports up to 131_072
+
+# Text generation settings
+if "instruct" in MODEL_FILE:
+ PROMPT = "What do llamas eat?"
+else:
+ PROMPT = "Llamas eat"
+
+MAX_NEW_TOKENS = 150
+TEMPERATURE = 0.
+TOP_K = 1
+```
+
+
+##### 3) Weight download and loading
+
+This automatically downloads the weight file based on the model choice above:
+
+```python
+import os
+import urllib.request
+
+url = f"https://huggingface.co/rasbt/llama-3.2-from-scratch/resolve/main/{MODEL_FILE}"
+
+if not os.path.exists(MODEL_FILE):
+ urllib.request.urlretrieve(url, MODEL_FILE)
+ print(f"Downloaded to {MODEL_FILE}")
+```
+
+The model weights are then loaded as follows:
+
+```python
+import torch
+from llms_from_scratch.llama3 import Llama3Model
+
+if "1B" in MODEL_FILE:
+ from llms_from_scratch.llama3 import LLAMA32_CONFIG_1B as LLAMA32_CONFIG
+elif "3B" in MODEL_FILE:
+ from llms_from_scratch.llama3 import LLAMA32_CONFIG_3B as LLAMA32_CONFIG
+else:
+ raise ValueError("Incorrect model file name")
+
+LLAMA32_CONFIG["context_length"] = MODEL_CONTEXT_LENGTH
+
+model = Llama3Model(LLAMA32_CONFIG)
+model.load_state_dict(torch.load(MODEL_FILE, weights_only=True))
+
+device = (
+ torch.device("cuda") if torch.cuda.is_available() else
+ torch.device("mps") if torch.backends.mps.is_available() else
+ torch.device("cpu")
+)
+model.to(device)
+```
+
+
+##### 4) Initialize tokenizer
+
+The following code downloads and initializes the tokenizer:
+
+```python
+from llms_from_scratch.llama3 import Llama3Tokenizer, ChatFormat, clean_text
+
+TOKENIZER_FILE = "tokenizer.model"
+
+url = f"https://huggingface.co/rasbt/llama-3.2-from-scratch/resolve/main/{TOKENIZER_FILE}"
+
+if not os.path.exists(TOKENIZER_FILE):
+ urllib.request.urlretrieve(url, TOKENIZER_FILE)
+ print(f"Downloaded to {TOKENIZER_FILE}")
+
+tokenizer = Llama3Tokenizer("tokenizer.model")
+
+if "instruct" in MODEL_FILE:
+ tokenizer = ChatFormat(tokenizer)
+```
+
+
+##### 5) Generating text
+
+Lastly, we can generate text via the following code:
+
+```python
+import time
+
+from llms_from_scratch.ch05 import (
+ generate,
+ text_to_token_ids,
+ token_ids_to_text
+)
+
+torch.manual_seed(123)
+
+start = time.time()
+
+token_ids = generate(
+ model=model,
+ idx=text_to_token_ids(PROMPT, tokenizer).to(device),
+ max_new_tokens=MAX_NEW_TOKENS,
+ context_size=LLAMA32_CONFIG["context_length"],
+ top_k=TOP_K,
+ temperature=TEMPERATURE
+)
+
+print(f"Time: {time.time() - start:.2f} sec")
+
+if torch.cuda.is_available():
+ max_mem_bytes = torch.cuda.max_memory_allocated()
+ max_mem_gb = max_mem_bytes / (1024 ** 3)
+ print(f"Max memory allocated: {max_mem_gb:.2f} GB")
+
+output_text = token_ids_to_text(token_ids, tokenizer)
+
+if "instruct" in MODEL_FILE:
+ output_text = clean_text(output_text)
+
+print("\n\nOutput text:\n\n", output_text)
+```
+
+When using the Llama 3.2 1B Instruct model, the output should look similar to the one shown below:
+
+```
+Time: 4.12 sec
+Max memory allocated: 2.91 GB
+
+
+Output text:
+
+ Llamas are herbivores, which means they primarily eat plants. Their diet consists mainly of:
+
+1. Grasses: Llamas love to graze on various types of grasses, including tall grasses and grassy meadows.
+2. Hay: Llamas also eat hay, which is a dry, compressed form of grass or other plants.
+3. Alfalfa: Alfalfa is a legume that is commonly used as a hay substitute in llama feed.
+4. Other plants: Llamas will also eat other plants, such as clover, dandelions, and wild grasses.
+
+It's worth noting that the specific diet of llamas can vary depending on factors such as the breed,
+```
+
+
+**Pro tip**
+
+For up to a 4× speed-up, replace
+
+```python
+model.to(device)
+```
+
+with
+
+```python
+model = torch.compile(model)
+model.to(device)
+```
+
+Note: the speed-up takes effect after the first `generate` call.
+
diff --git a/pkg/llms_from_scratch/README.md b/pkg/llms_from_scratch/README.md
index 355d967..7b2bddd 100644
--- a/pkg/llms_from_scratch/README.md
+++ b/pkg/llms_from_scratch/README.md
@@ -109,5 +109,13 @@ from llms_from_scratch.ch07 import (
from llms_from_scratch.appendix_a import NeuralNetwork, ToyDataset
from llms_from_scratch.appendix_d import find_highest_gradient, train_model
+
+from llms_from_scratch.llama3 import (
+ Llama3Model,
+ Llama3Tokenizer,
+ ChatFormat,
+ clean_text
+)
```
+(For the `llms_from_scratch.llama3` usage information, please see [this bonus section](../../ch05/07_gpt_to_llama/README.md).
diff --git a/pkg/llms_from_scratch/llama3.py b/pkg/llms_from_scratch/llama3.py
new file mode 100644
index 0000000..203b996
--- /dev/null
+++ b/pkg/llms_from_scratch/llama3.py
@@ -0,0 +1,377 @@
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+
+import os
+from pathlib import Path
+
+import torch
+import torch.nn as nn
+
+import tiktoken
+from tiktoken.load import load_tiktoken_bpe
+
+
+LLAMA32_CONFIG_1B = {
+ "vocab_size": 128_256, # Vocabulary size
+ "context_length": 8192, # Maximum context length to use (reduced to save memory)
+ "orig_context_length": 131_072, # Context length that was used to train the model
+ "emb_dim": 2048, # Embedding dimension
+ "n_heads": 32, # Number of attention heads
+ "n_layers": 16, # Number of layers
+ "hidden_dim": 8192, # Size of the intermediate dimension in FeedForward
+ "n_kv_groups": 8, # Key-Value groups for grouped-query attention
+ "rope_base": 500_000.0, # The base in RoPE's "theta"
+ "dtype": torch.bfloat16, # Lower-precision dtype to reduce memory usage
+ "rope_freq": { # RoPE frequency scaling
+ "factor": 32.0,
+ "low_freq_factor": 1.0,
+ "high_freq_factor": 4.0,
+ "original_context_length": 8192,
+ }
+}
+
+LLAMA32_CONFIG_3B = {
+ "vocab_size": 128_256, # Vocabulary size
+ "context_length": 8192, # Maximum context length to use (reduced to save memory)
+ "orig_context_length": 131_072, # Context length that was used to train the model
+ "emb_dim": 3072, # Embedding dimension
+ "n_heads": 24, # Number of attention heads
+ "n_layers": 28, # Number of layers
+ "hidden_dim": 8192, # Size of the intermediate dimension in FeedForward
+ "n_kv_groups": 8, # Key-Value groups for grouped-query attention
+ "rope_base": 500_000.0, # The base in RoPE's "theta"
+ "dtype": torch.bfloat16, # Lower-precision dtype to reduce memory usage
+ "rope_freq": { # RoPE frequency scaling
+ "factor": 32.0,
+ "low_freq_factor": 1.0,
+ "high_freq_factor": 4.0,
+ "original_context_length": 8192,
+ }
+}
+
+
+class Llama3Model(nn.Module):
+ def __init__(self, cfg):
+ super().__init__()
+
+ # Main model parameters
+ self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"], dtype=cfg["dtype"])
+
+ self.trf_blocks = nn.ModuleList( # ModuleList since Sequential can only accept one input, and we need `x, mask, cos, sin`
+ [TransformerBlock(cfg) for _ in range(cfg["n_layers"])]
+ )
+
+ self.final_norm = nn.RMSNorm(cfg["emb_dim"], eps=1e-5, dtype=cfg["dtype"])
+ self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False, dtype=cfg["dtype"])
+
+ # Reusuable utilities
+ self.register_buffer("mask", torch.triu(torch.ones(cfg["context_length"], cfg["context_length"]), diagonal=1).bool())
+
+ if cfg["orig_context_length"] != cfg["context_length"]:
+ cfg["rope_base"] = rescale_theta(
+ cfg["rope_base"],
+ cfg["orig_context_length"],
+ cfg["context_length"]
+ )
+ cos, sin = compute_rope_params(
+ head_dim=cfg["emb_dim"] // cfg["n_heads"],
+ theta_base=cfg["rope_base"],
+ context_length=cfg["context_length"],
+ freq_config=cfg["rope_freq"]
+ )
+ self.register_buffer("cos", cos, persistent=False)
+ self.register_buffer("sin", sin, persistent=False)
+ self.cfg = cfg
+
+ def forward(self, in_idx):
+ # Forward pass
+ tok_embeds = self.tok_emb(in_idx)
+ x = tok_embeds
+
+ for block in self.trf_blocks:
+ x = block(x, self.mask, self.cos, self.sin)
+ x = self.final_norm(x)
+ logits = self.out_head(x.to(self.cfg["dtype"]))
+ return logits
+
+
+class TransformerBlock(nn.Module):
+ def __init__(self, cfg):
+ super().__init__()
+ self.att = GroupedQueryAttention(
+ d_in=cfg["emb_dim"],
+ d_out=cfg["emb_dim"],
+ num_heads=cfg["n_heads"],
+ num_kv_groups=cfg["n_kv_groups"],
+ dtype=cfg["dtype"]
+ )
+ self.ff = FeedForward(cfg)
+ self.norm1 = nn.RMSNorm(cfg["emb_dim"], eps=1e-5, dtype=cfg["dtype"])
+ self.norm2 = nn.RMSNorm(cfg["emb_dim"], eps=1e-5, dtype=cfg["dtype"])
+
+ def forward(self, x, mask, cos, sin):
+ # Shortcut connection for attention block
+ shortcut = x
+ x = self.norm1(x)
+ x = self.att(x, mask, cos, sin) # Shape [batch_size, num_tokens, emb_size]
+ x = x + shortcut # Add the original input back
+
+ # Shortcut connection for feed-forward block
+ shortcut = x
+ x = self.norm2(x)
+ x = self.ff(x)
+ x = x + shortcut # Add the original input back
+
+ return x
+
+
+class FeedForward(nn.Module):
+ def __init__(self, cfg):
+ super().__init__()
+ self.fc1 = nn.Linear(cfg["emb_dim"], cfg["hidden_dim"], dtype=cfg["dtype"], bias=False)
+ self.fc2 = nn.Linear(cfg["emb_dim"], cfg["hidden_dim"], dtype=cfg["dtype"], bias=False)
+ self.fc3 = nn.Linear(cfg["hidden_dim"], cfg["emb_dim"], dtype=cfg["dtype"], bias=False)
+
+ def forward(self, x):
+ x_fc1 = self.fc1(x)
+ x_fc2 = self.fc2(x)
+ x = nn.functional.silu(x_fc1) * x_fc2
+ return self.fc3(x)
+
+
+class GroupedQueryAttention(nn.Module):
+ def __init__(
+ self, d_in, d_out, num_heads,
+ num_kv_groups,
+ dtype=None
+ ):
+ super().__init__()
+ assert d_out % num_heads == 0, "d_out must be divisible by num_heads"
+ assert num_heads % num_kv_groups == 0, "num_heads must be divisible by num_kv_groups"
+
+ self.d_out = d_out
+ self.num_heads = num_heads
+ self.head_dim = d_out // num_heads
+
+ self.W_key = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)
+ self.W_value = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)
+ self.num_kv_groups = num_kv_groups
+ self.group_size = num_heads // num_kv_groups
+
+ self.W_query = nn.Linear(d_in, d_out, bias=False, dtype=dtype)
+ self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype)
+
+ def forward(self, x, mask, cos, sin):
+ b, num_tokens, d_in = x.shape
+
+ queries = self.W_query(x) # Shape: (b, num_tokens, d_out)
+ keys = self.W_key(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)
+ values = self.W_value(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)
+
+ # Reshape queries, keys, and values
+ queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
+ keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim)
+ values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim)
+
+ # Transpose keys, values, and queries
+ keys = keys.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)
+ values = values.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)
+ queries = queries.transpose(1, 2) # Shape: (b, num_query_groups, num_tokens, head_dim)
+
+ # Apply RoPE
+ keys = apply_rope(keys, cos, sin)
+ queries = apply_rope(queries, cos, sin)
+
+ # Expand keys and values to match the number of heads
+ # Shape: (b, num_heads, num_tokens, head_dim)
+ keys = keys.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)
+ values = values.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)
+ # For example, before repeat_interleave along dim=1 (query groups):
+ # [K1, K2]
+ # After repeat_interleave (each query group is repeated group_size times):
+ # [K1, K1, K2, K2]
+ # If we used regular repeat instead of repeat_interleave, we'd get:
+ # [K1, K2, K1, K2]
+
+ # Compute scaled dot-product attention (aka self-attention) with a causal mask
+ # Shape: (b, num_heads, num_tokens, num_tokens)
+ attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
+
+ # Use the mask to fill attention scores
+ attn_scores = attn_scores.masked_fill(mask[:num_tokens, :num_tokens], -torch.inf)
+
+ attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
+ assert keys.shape[-1] == self.head_dim
+
+ # Shape: (b, num_tokens, num_heads, head_dim)
+ context_vec = (attn_weights @ values).transpose(1, 2)
+
+ # Combine heads, where self.d_out = self.num_heads * self.head_dim
+ context_vec = context_vec.reshape(b, num_tokens, self.d_out)
+ context_vec = self.out_proj(context_vec) # optional projection
+
+ return context_vec
+
+
+def compute_rope_params(head_dim, theta_base=10_000, context_length=4096, freq_config=None, dtype=torch.float32):
+ assert head_dim % 2 == 0, "Embedding dimension must be even"
+
+ # Compute the inverse frequencies
+ inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim, 2, dtype=dtype)[: (head_dim // 2)].float() / head_dim))
+
+ # Frequency adjustments
+ if freq_config is not None:
+ low_freq_wavelen = freq_config["original_context_length"] / freq_config["low_freq_factor"]
+ high_freq_wavelen = freq_config["original_context_length"] / freq_config["high_freq_factor"]
+
+ wavelen = 2 * torch.pi / inv_freq
+
+ inv_freq_llama = torch.where(
+ wavelen > low_freq_wavelen, inv_freq / freq_config["factor"], inv_freq
+ )
+
+ smooth_factor = (freq_config["original_context_length"] / wavelen - freq_config["low_freq_factor"]) / (
+ freq_config["high_freq_factor"] - freq_config["low_freq_factor"]
+ )
+
+ smoothed_inv_freq = (
+ (1 - smooth_factor) * (inv_freq / freq_config["factor"]) + smooth_factor * inv_freq
+ )
+
+ is_medium_freq = (wavelen <= low_freq_wavelen) & (wavelen >= high_freq_wavelen)
+ inv_freq_llama = torch.where(is_medium_freq, smoothed_inv_freq, inv_freq_llama)
+ inv_freq = inv_freq_llama
+
+ # Generate position indices
+ positions = torch.arange(context_length, dtype=dtype)
+
+ # Compute the angles
+ angles = positions[:, None] * inv_freq[None, :] # Shape: (context_length, head_dim // 2)
+
+ # Expand angles to match the head_dim
+ angles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)
+
+ # Precompute sine and cosine
+ cos = torch.cos(angles)
+ sin = torch.sin(angles)
+
+ return cos, sin
+
+
+def apply_rope(x, cos, sin):
+ # x: (batch_size, num_heads, seq_len, head_dim)
+ batch_size, num_heads, seq_len, head_dim = x.shape
+ assert head_dim % 2 == 0, "Head dimension must be even"
+
+ # Split x into first half and second half
+ x1 = x[..., : head_dim // 2] # First half
+ x2 = x[..., head_dim // 2:] # Second half
+
+ # Adjust sin and cos shapes
+ cos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)
+ sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)
+
+ # Apply the rotary transformation
+ rotated = torch.cat((-x2, x1), dim=-1)
+ x_rotated = (x * cos) + (rotated * sin)
+
+ # It's ok to use lower-precision after applying cos and sin rotation
+ return x_rotated.to(dtype=x.dtype)
+
+
+def rescale_theta(theta_old, context_length_old, context_length_new):
+ scaling_factor = context_length_new / context_length_old
+ theta_new = theta_old * scaling_factor
+ return theta_new
+
+
+##########################################
+# Tokenizer
+##########################################
+
+
+class Llama3Tokenizer:
+ def __init__(self, model_path):
+ assert os.path.isfile(model_path), f"Model file {model_path} not found"
+ mergeable_ranks = load_tiktoken_bpe(model_path)
+
+ self.special_tokens = {
+ "<|begin_of_text|>": 128000,
+ "<|end_of_text|>": 128001,
+ "<|start_header_id|>": 128006,
+ "<|end_header_id|>": 128007,
+ "<|eot_id|>": 128009,
+ }
+ self.special_tokens.update({
+ f"<|reserved_{i}|>": 128002 + i for i in range(256) if (128002 + i) not in self.special_tokens.values()
+ })
+
+ self.model = tiktoken.Encoding(
+ name=Path(model_path).name,
+ pat_str=r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+",
+ mergeable_ranks=mergeable_ranks,
+ special_tokens=self.special_tokens
+ )
+
+ def encode(self, text, bos=False, eos=False, allowed_special=set(), disallowed_special=()):
+ if bos:
+ tokens = [self.special_tokens["<|begin_of_text|>"]]
+ else:
+ tokens = []
+
+ tokens += self.model.encode(text, allowed_special=allowed_special, disallowed_special=disallowed_special)
+
+ if eos:
+ tokens.append(self.special_tokens["<|end_of_text|>"])
+ return tokens
+
+ def decode(self, tokens):
+ return self.model.decode(tokens)
+
+
+class ChatFormat:
+ def __init__(self, tokenizer):
+ self.tokenizer = tokenizer
+
+ def encode_header(self, message):
+ tokens = []
+ tokens.append(self.tokenizer.special_tokens["<|start_header_id|>"])
+ tokens.extend(self.tokenizer.encode(message["role"], bos=False, eos=False))
+ tokens.append(self.tokenizer.special_tokens["<|end_header_id|>"])
+ tokens.extend(self.tokenizer.encode("\n\n", bos=False, eos=False))
+ return tokens
+
+ def encode(self, text, allowed_special=None):
+ message = {
+ "role": "user",
+ "content": text
+ }
+
+ tokens = self.encode_header(message)
+ tokens.extend(
+ self.tokenizer.encode(
+ message["content"].strip(),
+ bos=False,
+ eos=False,
+ allowed_special=allowed_special
+ )
+ )
+ tokens.append(self.tokenizer.special_tokens["<|eot_id|>"])
+ return tokens
+
+ def decode(self, token_ids):
+ return self.tokenizer.decode(token_ids)
+
+
+def clean_text(text, header_end="assistant<|end_header_id|>\n\n"):
+ # Find the index of the first occurrence of "<|end_header_id|>"
+ index = text.find(header_end)
+
+ if index != -1:
+ # Return the substring starting after "<|end_header_id|>"
+ return text[index + len(header_end):].strip() # Strip removes leading/trailing whitespace
+ else:
+ # If the token is not found, return the original text
+ return text
diff --git a/pkg/llms_from_scratch/tests/test_llama3.py b/pkg/llms_from_scratch/tests/test_llama3.py
new file mode 100644
index 0000000..70ff8f5
--- /dev/null
+++ b/pkg/llms_from_scratch/tests/test_llama3.py
@@ -0,0 +1,147 @@
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+
+from llms_from_scratch.ch04 import generate_text_simple
+from llms_from_scratch.llama3 import (
+ compute_rope_params,
+ apply_rope,
+ rescale_theta,
+ LLAMA32_CONFIG_1B,
+ Llama3Model
+)
+
+import importlib
+import pytest
+import tiktoken
+import torch
+
+
+transformers_installed = importlib.util.find_spec("transformers") is not None
+
+
+@pytest.mark.skipif(not transformers_installed, reason="transformers not installed")
+def test_rope():
+
+ from transformers.models.llama.modeling_llama import LlamaRotaryEmbedding, apply_rotary_pos_emb
+
+ # Settings
+ batch_size = 1
+ context_len = 8192
+ num_heads = 4
+ head_dim = 16
+ rope_theta = 500_000
+
+ rope_config = {
+ "factor": 8.0,
+ "low_freq_factor": 1.0,
+ "high_freq_factor": 4.0,
+ "original_context_length": 8192,
+ }
+
+ # Instantiate RoPE parameters
+ cos, sin = compute_rope_params(
+ head_dim=head_dim,
+ theta_base=rope_theta,
+ context_length=context_len,
+ freq_config=rope_config,
+ )
+
+ # Dummy query and key tensors
+ torch.manual_seed(123)
+ queries = torch.randn(batch_size, num_heads, context_len, head_dim)
+ keys = torch.randn(batch_size, num_heads, context_len, head_dim)
+
+ # Apply rotary position embeddings
+ queries_rot = apply_rope(queries, cos, sin)
+ keys_rot = apply_rope(keys, cos, sin)
+
+ # Generate reference RoPE via HF
+ hf_rope_params = {
+ "factor": 8.0,
+ "low_freq_factor": 1.0,
+ "high_freq_factor": 4.0,
+ "original_max_position_embeddings": 8192,
+ "rope_type": "llama3"
+ }
+
+ class RoPEConfig:
+ rope_type = "llama3"
+ rope_scaling = hf_rope_params
+ factor = 1.0
+ dim: int = head_dim
+ rope_theta = 500_000
+ max_position_embeddings: int = 8192
+ hidden_size = head_dim * num_heads
+ num_attention_heads = num_heads
+
+ config = RoPEConfig()
+
+ rot_emb = LlamaRotaryEmbedding(config=config)
+ position_ids = torch.arange(context_len, dtype=torch.long).unsqueeze(0)
+ ref_cos, ref_sin = rot_emb(queries, position_ids)
+ ref_queries_rot, ref_keys_rot = apply_rotary_pos_emb(queries, keys, ref_cos, ref_sin)
+
+ torch.testing.assert_close(sin, ref_sin.squeeze(0))
+ torch.testing.assert_close(cos, ref_cos.squeeze(0))
+ torch.testing.assert_close(keys_rot, ref_keys_rot)
+ torch.testing.assert_close(queries_rot, ref_queries_rot)
+
+
+GPT_CONFIG_124M = {
+ "vocab_size": 50257, # Vocabulary size
+ "context_length": 1024, # Context length
+ "emb_dim": 768, # Embedding dimension
+ "n_heads": 12, # Number of attention heads
+ "n_layers": 12, # Number of layers
+ "drop_rate": 0.1, # Dropout rate
+ "qkv_bias": False # Query-Key-Value bias
+}
+
+
+def test_rescale():
+
+ new_theta = rescale_theta(
+ theta_old=500_000.,
+ context_length_old=131_072,
+ context_length_new=8192
+ )
+ assert new_theta == 31250.
+
+ old_theta = rescale_theta(
+ theta_old=new_theta,
+ context_length_old=8192,
+ context_length_new=131_072
+ )
+ assert old_theta == 500_000.
+
+
+@pytest.mark.parametrize("ModelClass", [Llama3Model])
+def test_gpt_model_variants(ModelClass):
+ torch.manual_seed(123)
+ model = ModelClass(LLAMA32_CONFIG_1B)
+ model.eval()
+
+ start_context = "Hello, I am"
+
+ tokenizer = tiktoken.get_encoding("gpt2")
+ encoded = tokenizer.encode(start_context)
+ encoded_tensor = torch.tensor(encoded).unsqueeze(0)
+
+ print(f"\n{50*'='}\n{22*' '}IN\n{50*'='}")
+ print("\nInput text:", start_context)
+ print("Encoded input text:", encoded)
+ print("encoded_tensor.shape:", encoded_tensor.shape)
+
+ out = generate_text_simple(
+ model=model,
+ idx=encoded_tensor,
+ max_new_tokens=10,
+ context_size=LLAMA32_CONFIG_1B["context_length"]
+ )
+ expect = torch.tensor([
+ [15496, 11, 314, 716, 78563, 89362, 19616, 115725, 114917,
+ 97198, 60342, 19108, 100752, 98969]
+ ])
+ assert torch.equal(expect, out)
diff --git a/pyproject.toml b/pyproject.toml
index d1bda8f..f0805c0 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -4,7 +4,7 @@ build-backend = "setuptools.build_meta"
[project]
name = "llms-from-scratch"
-version = "1.0.2"
+version = "1.0.5"
description = "Implement a ChatGPT-like LLM in PyTorch from scratch, step by step"
readme = "README.md"
requires-python = ">=3.10"
\ No newline at end of file
+
+
+
+
+### Using Llama 3.2 via the `llms-from-scratch` package
+
+For an easy way to use the Llama 3.2 1B and 3B models, you can also use the `llms-from-scratch` PyPI package based on the source code in this repository at [pkg/llms_from_scratch](../../pkg/llms_from_scratch).
+
+
+##### 1) Installation
+
+```bash
+pip install llms_from_scratch blobfile
+```
+
+##### 2) Model and text generation settings
+
+Specify which model to use:
+
+```python
+MODEL_FILE = "llama3.2-1B-instruct.pth"
+# MODEL_FILE = "llama3.2-1B-base.pth"
+# MODEL_FILE = "llama3.2-3B-instruct.pth"
+# MODEL_FILE = "llama3.2-3B-base.pth"
+```
+
+Basic text generation settings that can be defined by the user. Note that the recommended 8192-token context size requires approximately 3 GB of VRAM for the text generation example.
+
+```python
+MODEL_CONTEXT_LENGTH = 8192 # Supports up to 131_072
+
+# Text generation settings
+if "instruct" in MODEL_FILE:
+ PROMPT = "What do llamas eat?"
+else:
+ PROMPT = "Llamas eat"
+
+MAX_NEW_TOKENS = 150
+TEMPERATURE = 0.
+TOP_K = 1
+```
+
+
+##### 3) Weight download and loading
+
+This automatically downloads the weight file based on the model choice above:
+
+```python
+import os
+import urllib.request
+
+url = f"https://huggingface.co/rasbt/llama-3.2-from-scratch/resolve/main/{MODEL_FILE}"
+
+if not os.path.exists(MODEL_FILE):
+ urllib.request.urlretrieve(url, MODEL_FILE)
+ print(f"Downloaded to {MODEL_FILE}")
+```
+
+The model weights are then loaded as follows:
+
+```python
+import torch
+from llms_from_scratch.llama3 import Llama3Model
+
+if "1B" in MODEL_FILE:
+ from llms_from_scratch.llama3 import LLAMA32_CONFIG_1B as LLAMA32_CONFIG
+elif "3B" in MODEL_FILE:
+ from llms_from_scratch.llama3 import LLAMA32_CONFIG_3B as LLAMA32_CONFIG
+else:
+ raise ValueError("Incorrect model file name")
+
+LLAMA32_CONFIG["context_length"] = MODEL_CONTEXT_LENGTH
+
+model = Llama3Model(LLAMA32_CONFIG)
+model.load_state_dict(torch.load(MODEL_FILE, weights_only=True))
+
+device = (
+ torch.device("cuda") if torch.cuda.is_available() else
+ torch.device("mps") if torch.backends.mps.is_available() else
+ torch.device("cpu")
+)
+model.to(device)
+```
+
+
+##### 4) Initialize tokenizer
+
+The following code downloads and initializes the tokenizer:
+
+```python
+from llms_from_scratch.llama3 import Llama3Tokenizer, ChatFormat, clean_text
+
+TOKENIZER_FILE = "tokenizer.model"
+
+url = f"https://huggingface.co/rasbt/llama-3.2-from-scratch/resolve/main/{TOKENIZER_FILE}"
+
+if not os.path.exists(TOKENIZER_FILE):
+ urllib.request.urlretrieve(url, TOKENIZER_FILE)
+ print(f"Downloaded to {TOKENIZER_FILE}")
+
+tokenizer = Llama3Tokenizer("tokenizer.model")
+
+if "instruct" in MODEL_FILE:
+ tokenizer = ChatFormat(tokenizer)
+```
+
+
+##### 5) Generating text
+
+Lastly, we can generate text via the following code:
+
+```python
+import time
+
+from llms_from_scratch.ch05 import (
+ generate,
+ text_to_token_ids,
+ token_ids_to_text
+)
+
+torch.manual_seed(123)
+
+start = time.time()
+
+token_ids = generate(
+ model=model,
+ idx=text_to_token_ids(PROMPT, tokenizer).to(device),
+ max_new_tokens=MAX_NEW_TOKENS,
+ context_size=LLAMA32_CONFIG["context_length"],
+ top_k=TOP_K,
+ temperature=TEMPERATURE
+)
+
+print(f"Time: {time.time() - start:.2f} sec")
+
+if torch.cuda.is_available():
+ max_mem_bytes = torch.cuda.max_memory_allocated()
+ max_mem_gb = max_mem_bytes / (1024 ** 3)
+ print(f"Max memory allocated: {max_mem_gb:.2f} GB")
+
+output_text = token_ids_to_text(token_ids, tokenizer)
+
+if "instruct" in MODEL_FILE:
+ output_text = clean_text(output_text)
+
+print("\n\nOutput text:\n\n", output_text)
+```
+
+When using the Llama 3.2 1B Instruct model, the output should look similar to the one shown below:
+
+```
+Time: 4.12 sec
+Max memory allocated: 2.91 GB
+
+
+Output text:
+
+ Llamas are herbivores, which means they primarily eat plants. Their diet consists mainly of:
+
+1. Grasses: Llamas love to graze on various types of grasses, including tall grasses and grassy meadows.
+2. Hay: Llamas also eat hay, which is a dry, compressed form of grass or other plants.
+3. Alfalfa: Alfalfa is a legume that is commonly used as a hay substitute in llama feed.
+4. Other plants: Llamas will also eat other plants, such as clover, dandelions, and wild grasses.
+
+It's worth noting that the specific diet of llamas can vary depending on factors such as the breed,
+```
+
+
+**Pro tip**
+
+For up to a 4× speed-up, replace
+
+```python
+model.to(device)
+```
+
+with
+
+```python
+model = torch.compile(model)
+model.to(device)
+```
+
+Note: the speed-up takes effect after the first `generate` call.
+
diff --git a/pkg/llms_from_scratch/README.md b/pkg/llms_from_scratch/README.md
index 355d967..7b2bddd 100644
--- a/pkg/llms_from_scratch/README.md
+++ b/pkg/llms_from_scratch/README.md
@@ -109,5 +109,13 @@ from llms_from_scratch.ch07 import (
from llms_from_scratch.appendix_a import NeuralNetwork, ToyDataset
from llms_from_scratch.appendix_d import find_highest_gradient, train_model
+
+from llms_from_scratch.llama3 import (
+ Llama3Model,
+ Llama3Tokenizer,
+ ChatFormat,
+ clean_text
+)
```
+(For the `llms_from_scratch.llama3` usage information, please see [this bonus section](../../ch05/07_gpt_to_llama/README.md).
diff --git a/pkg/llms_from_scratch/llama3.py b/pkg/llms_from_scratch/llama3.py
new file mode 100644
index 0000000..203b996
--- /dev/null
+++ b/pkg/llms_from_scratch/llama3.py
@@ -0,0 +1,377 @@
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+
+import os
+from pathlib import Path
+
+import torch
+import torch.nn as nn
+
+import tiktoken
+from tiktoken.load import load_tiktoken_bpe
+
+
+LLAMA32_CONFIG_1B = {
+ "vocab_size": 128_256, # Vocabulary size
+ "context_length": 8192, # Maximum context length to use (reduced to save memory)
+ "orig_context_length": 131_072, # Context length that was used to train the model
+ "emb_dim": 2048, # Embedding dimension
+ "n_heads": 32, # Number of attention heads
+ "n_layers": 16, # Number of layers
+ "hidden_dim": 8192, # Size of the intermediate dimension in FeedForward
+ "n_kv_groups": 8, # Key-Value groups for grouped-query attention
+ "rope_base": 500_000.0, # The base in RoPE's "theta"
+ "dtype": torch.bfloat16, # Lower-precision dtype to reduce memory usage
+ "rope_freq": { # RoPE frequency scaling
+ "factor": 32.0,
+ "low_freq_factor": 1.0,
+ "high_freq_factor": 4.0,
+ "original_context_length": 8192,
+ }
+}
+
+LLAMA32_CONFIG_3B = {
+ "vocab_size": 128_256, # Vocabulary size
+ "context_length": 8192, # Maximum context length to use (reduced to save memory)
+ "orig_context_length": 131_072, # Context length that was used to train the model
+ "emb_dim": 3072, # Embedding dimension
+ "n_heads": 24, # Number of attention heads
+ "n_layers": 28, # Number of layers
+ "hidden_dim": 8192, # Size of the intermediate dimension in FeedForward
+ "n_kv_groups": 8, # Key-Value groups for grouped-query attention
+ "rope_base": 500_000.0, # The base in RoPE's "theta"
+ "dtype": torch.bfloat16, # Lower-precision dtype to reduce memory usage
+ "rope_freq": { # RoPE frequency scaling
+ "factor": 32.0,
+ "low_freq_factor": 1.0,
+ "high_freq_factor": 4.0,
+ "original_context_length": 8192,
+ }
+}
+
+
+class Llama3Model(nn.Module):
+ def __init__(self, cfg):
+ super().__init__()
+
+ # Main model parameters
+ self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"], dtype=cfg["dtype"])
+
+ self.trf_blocks = nn.ModuleList( # ModuleList since Sequential can only accept one input, and we need `x, mask, cos, sin`
+ [TransformerBlock(cfg) for _ in range(cfg["n_layers"])]
+ )
+
+ self.final_norm = nn.RMSNorm(cfg["emb_dim"], eps=1e-5, dtype=cfg["dtype"])
+ self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False, dtype=cfg["dtype"])
+
+ # Reusuable utilities
+ self.register_buffer("mask", torch.triu(torch.ones(cfg["context_length"], cfg["context_length"]), diagonal=1).bool())
+
+ if cfg["orig_context_length"] != cfg["context_length"]:
+ cfg["rope_base"] = rescale_theta(
+ cfg["rope_base"],
+ cfg["orig_context_length"],
+ cfg["context_length"]
+ )
+ cos, sin = compute_rope_params(
+ head_dim=cfg["emb_dim"] // cfg["n_heads"],
+ theta_base=cfg["rope_base"],
+ context_length=cfg["context_length"],
+ freq_config=cfg["rope_freq"]
+ )
+ self.register_buffer("cos", cos, persistent=False)
+ self.register_buffer("sin", sin, persistent=False)
+ self.cfg = cfg
+
+ def forward(self, in_idx):
+ # Forward pass
+ tok_embeds = self.tok_emb(in_idx)
+ x = tok_embeds
+
+ for block in self.trf_blocks:
+ x = block(x, self.mask, self.cos, self.sin)
+ x = self.final_norm(x)
+ logits = self.out_head(x.to(self.cfg["dtype"]))
+ return logits
+
+
+class TransformerBlock(nn.Module):
+ def __init__(self, cfg):
+ super().__init__()
+ self.att = GroupedQueryAttention(
+ d_in=cfg["emb_dim"],
+ d_out=cfg["emb_dim"],
+ num_heads=cfg["n_heads"],
+ num_kv_groups=cfg["n_kv_groups"],
+ dtype=cfg["dtype"]
+ )
+ self.ff = FeedForward(cfg)
+ self.norm1 = nn.RMSNorm(cfg["emb_dim"], eps=1e-5, dtype=cfg["dtype"])
+ self.norm2 = nn.RMSNorm(cfg["emb_dim"], eps=1e-5, dtype=cfg["dtype"])
+
+ def forward(self, x, mask, cos, sin):
+ # Shortcut connection for attention block
+ shortcut = x
+ x = self.norm1(x)
+ x = self.att(x, mask, cos, sin) # Shape [batch_size, num_tokens, emb_size]
+ x = x + shortcut # Add the original input back
+
+ # Shortcut connection for feed-forward block
+ shortcut = x
+ x = self.norm2(x)
+ x = self.ff(x)
+ x = x + shortcut # Add the original input back
+
+ return x
+
+
+class FeedForward(nn.Module):
+ def __init__(self, cfg):
+ super().__init__()
+ self.fc1 = nn.Linear(cfg["emb_dim"], cfg["hidden_dim"], dtype=cfg["dtype"], bias=False)
+ self.fc2 = nn.Linear(cfg["emb_dim"], cfg["hidden_dim"], dtype=cfg["dtype"], bias=False)
+ self.fc3 = nn.Linear(cfg["hidden_dim"], cfg["emb_dim"], dtype=cfg["dtype"], bias=False)
+
+ def forward(self, x):
+ x_fc1 = self.fc1(x)
+ x_fc2 = self.fc2(x)
+ x = nn.functional.silu(x_fc1) * x_fc2
+ return self.fc3(x)
+
+
+class GroupedQueryAttention(nn.Module):
+ def __init__(
+ self, d_in, d_out, num_heads,
+ num_kv_groups,
+ dtype=None
+ ):
+ super().__init__()
+ assert d_out % num_heads == 0, "d_out must be divisible by num_heads"
+ assert num_heads % num_kv_groups == 0, "num_heads must be divisible by num_kv_groups"
+
+ self.d_out = d_out
+ self.num_heads = num_heads
+ self.head_dim = d_out // num_heads
+
+ self.W_key = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)
+ self.W_value = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)
+ self.num_kv_groups = num_kv_groups
+ self.group_size = num_heads // num_kv_groups
+
+ self.W_query = nn.Linear(d_in, d_out, bias=False, dtype=dtype)
+ self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype)
+
+ def forward(self, x, mask, cos, sin):
+ b, num_tokens, d_in = x.shape
+
+ queries = self.W_query(x) # Shape: (b, num_tokens, d_out)
+ keys = self.W_key(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)
+ values = self.W_value(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)
+
+ # Reshape queries, keys, and values
+ queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
+ keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim)
+ values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim)
+
+ # Transpose keys, values, and queries
+ keys = keys.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)
+ values = values.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)
+ queries = queries.transpose(1, 2) # Shape: (b, num_query_groups, num_tokens, head_dim)
+
+ # Apply RoPE
+ keys = apply_rope(keys, cos, sin)
+ queries = apply_rope(queries, cos, sin)
+
+ # Expand keys and values to match the number of heads
+ # Shape: (b, num_heads, num_tokens, head_dim)
+ keys = keys.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)
+ values = values.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)
+ # For example, before repeat_interleave along dim=1 (query groups):
+ # [K1, K2]
+ # After repeat_interleave (each query group is repeated group_size times):
+ # [K1, K1, K2, K2]
+ # If we used regular repeat instead of repeat_interleave, we'd get:
+ # [K1, K2, K1, K2]
+
+ # Compute scaled dot-product attention (aka self-attention) with a causal mask
+ # Shape: (b, num_heads, num_tokens, num_tokens)
+ attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
+
+ # Use the mask to fill attention scores
+ attn_scores = attn_scores.masked_fill(mask[:num_tokens, :num_tokens], -torch.inf)
+
+ attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
+ assert keys.shape[-1] == self.head_dim
+
+ # Shape: (b, num_tokens, num_heads, head_dim)
+ context_vec = (attn_weights @ values).transpose(1, 2)
+
+ # Combine heads, where self.d_out = self.num_heads * self.head_dim
+ context_vec = context_vec.reshape(b, num_tokens, self.d_out)
+ context_vec = self.out_proj(context_vec) # optional projection
+
+ return context_vec
+
+
+def compute_rope_params(head_dim, theta_base=10_000, context_length=4096, freq_config=None, dtype=torch.float32):
+ assert head_dim % 2 == 0, "Embedding dimension must be even"
+
+ # Compute the inverse frequencies
+ inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim, 2, dtype=dtype)[: (head_dim // 2)].float() / head_dim))
+
+ # Frequency adjustments
+ if freq_config is not None:
+ low_freq_wavelen = freq_config["original_context_length"] / freq_config["low_freq_factor"]
+ high_freq_wavelen = freq_config["original_context_length"] / freq_config["high_freq_factor"]
+
+ wavelen = 2 * torch.pi / inv_freq
+
+ inv_freq_llama = torch.where(
+ wavelen > low_freq_wavelen, inv_freq / freq_config["factor"], inv_freq
+ )
+
+ smooth_factor = (freq_config["original_context_length"] / wavelen - freq_config["low_freq_factor"]) / (
+ freq_config["high_freq_factor"] - freq_config["low_freq_factor"]
+ )
+
+ smoothed_inv_freq = (
+ (1 - smooth_factor) * (inv_freq / freq_config["factor"]) + smooth_factor * inv_freq
+ )
+
+ is_medium_freq = (wavelen <= low_freq_wavelen) & (wavelen >= high_freq_wavelen)
+ inv_freq_llama = torch.where(is_medium_freq, smoothed_inv_freq, inv_freq_llama)
+ inv_freq = inv_freq_llama
+
+ # Generate position indices
+ positions = torch.arange(context_length, dtype=dtype)
+
+ # Compute the angles
+ angles = positions[:, None] * inv_freq[None, :] # Shape: (context_length, head_dim // 2)
+
+ # Expand angles to match the head_dim
+ angles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)
+
+ # Precompute sine and cosine
+ cos = torch.cos(angles)
+ sin = torch.sin(angles)
+
+ return cos, sin
+
+
+def apply_rope(x, cos, sin):
+ # x: (batch_size, num_heads, seq_len, head_dim)
+ batch_size, num_heads, seq_len, head_dim = x.shape
+ assert head_dim % 2 == 0, "Head dimension must be even"
+
+ # Split x into first half and second half
+ x1 = x[..., : head_dim // 2] # First half
+ x2 = x[..., head_dim // 2:] # Second half
+
+ # Adjust sin and cos shapes
+ cos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)
+ sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)
+
+ # Apply the rotary transformation
+ rotated = torch.cat((-x2, x1), dim=-1)
+ x_rotated = (x * cos) + (rotated * sin)
+
+ # It's ok to use lower-precision after applying cos and sin rotation
+ return x_rotated.to(dtype=x.dtype)
+
+
+def rescale_theta(theta_old, context_length_old, context_length_new):
+ scaling_factor = context_length_new / context_length_old
+ theta_new = theta_old * scaling_factor
+ return theta_new
+
+
+##########################################
+# Tokenizer
+##########################################
+
+
+class Llama3Tokenizer:
+ def __init__(self, model_path):
+ assert os.path.isfile(model_path), f"Model file {model_path} not found"
+ mergeable_ranks = load_tiktoken_bpe(model_path)
+
+ self.special_tokens = {
+ "<|begin_of_text|>": 128000,
+ "<|end_of_text|>": 128001,
+ "<|start_header_id|>": 128006,
+ "<|end_header_id|>": 128007,
+ "<|eot_id|>": 128009,
+ }
+ self.special_tokens.update({
+ f"<|reserved_{i}|>": 128002 + i for i in range(256) if (128002 + i) not in self.special_tokens.values()
+ })
+
+ self.model = tiktoken.Encoding(
+ name=Path(model_path).name,
+ pat_str=r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+",
+ mergeable_ranks=mergeable_ranks,
+ special_tokens=self.special_tokens
+ )
+
+ def encode(self, text, bos=False, eos=False, allowed_special=set(), disallowed_special=()):
+ if bos:
+ tokens = [self.special_tokens["<|begin_of_text|>"]]
+ else:
+ tokens = []
+
+ tokens += self.model.encode(text, allowed_special=allowed_special, disallowed_special=disallowed_special)
+
+ if eos:
+ tokens.append(self.special_tokens["<|end_of_text|>"])
+ return tokens
+
+ def decode(self, tokens):
+ return self.model.decode(tokens)
+
+
+class ChatFormat:
+ def __init__(self, tokenizer):
+ self.tokenizer = tokenizer
+
+ def encode_header(self, message):
+ tokens = []
+ tokens.append(self.tokenizer.special_tokens["<|start_header_id|>"])
+ tokens.extend(self.tokenizer.encode(message["role"], bos=False, eos=False))
+ tokens.append(self.tokenizer.special_tokens["<|end_header_id|>"])
+ tokens.extend(self.tokenizer.encode("\n\n", bos=False, eos=False))
+ return tokens
+
+ def encode(self, text, allowed_special=None):
+ message = {
+ "role": "user",
+ "content": text
+ }
+
+ tokens = self.encode_header(message)
+ tokens.extend(
+ self.tokenizer.encode(
+ message["content"].strip(),
+ bos=False,
+ eos=False,
+ allowed_special=allowed_special
+ )
+ )
+ tokens.append(self.tokenizer.special_tokens["<|eot_id|>"])
+ return tokens
+
+ def decode(self, token_ids):
+ return self.tokenizer.decode(token_ids)
+
+
+def clean_text(text, header_end="assistant<|end_header_id|>\n\n"):
+ # Find the index of the first occurrence of "<|end_header_id|>"
+ index = text.find(header_end)
+
+ if index != -1:
+ # Return the substring starting after "<|end_header_id|>"
+ return text[index + len(header_end):].strip() # Strip removes leading/trailing whitespace
+ else:
+ # If the token is not found, return the original text
+ return text
diff --git a/pkg/llms_from_scratch/tests/test_llama3.py b/pkg/llms_from_scratch/tests/test_llama3.py
new file mode 100644
index 0000000..70ff8f5
--- /dev/null
+++ b/pkg/llms_from_scratch/tests/test_llama3.py
@@ -0,0 +1,147 @@
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+
+from llms_from_scratch.ch04 import generate_text_simple
+from llms_from_scratch.llama3 import (
+ compute_rope_params,
+ apply_rope,
+ rescale_theta,
+ LLAMA32_CONFIG_1B,
+ Llama3Model
+)
+
+import importlib
+import pytest
+import tiktoken
+import torch
+
+
+transformers_installed = importlib.util.find_spec("transformers") is not None
+
+
+@pytest.mark.skipif(not transformers_installed, reason="transformers not installed")
+def test_rope():
+
+ from transformers.models.llama.modeling_llama import LlamaRotaryEmbedding, apply_rotary_pos_emb
+
+ # Settings
+ batch_size = 1
+ context_len = 8192
+ num_heads = 4
+ head_dim = 16
+ rope_theta = 500_000
+
+ rope_config = {
+ "factor": 8.0,
+ "low_freq_factor": 1.0,
+ "high_freq_factor": 4.0,
+ "original_context_length": 8192,
+ }
+
+ # Instantiate RoPE parameters
+ cos, sin = compute_rope_params(
+ head_dim=head_dim,
+ theta_base=rope_theta,
+ context_length=context_len,
+ freq_config=rope_config,
+ )
+
+ # Dummy query and key tensors
+ torch.manual_seed(123)
+ queries = torch.randn(batch_size, num_heads, context_len, head_dim)
+ keys = torch.randn(batch_size, num_heads, context_len, head_dim)
+
+ # Apply rotary position embeddings
+ queries_rot = apply_rope(queries, cos, sin)
+ keys_rot = apply_rope(keys, cos, sin)
+
+ # Generate reference RoPE via HF
+ hf_rope_params = {
+ "factor": 8.0,
+ "low_freq_factor": 1.0,
+ "high_freq_factor": 4.0,
+ "original_max_position_embeddings": 8192,
+ "rope_type": "llama3"
+ }
+
+ class RoPEConfig:
+ rope_type = "llama3"
+ rope_scaling = hf_rope_params
+ factor = 1.0
+ dim: int = head_dim
+ rope_theta = 500_000
+ max_position_embeddings: int = 8192
+ hidden_size = head_dim * num_heads
+ num_attention_heads = num_heads
+
+ config = RoPEConfig()
+
+ rot_emb = LlamaRotaryEmbedding(config=config)
+ position_ids = torch.arange(context_len, dtype=torch.long).unsqueeze(0)
+ ref_cos, ref_sin = rot_emb(queries, position_ids)
+ ref_queries_rot, ref_keys_rot = apply_rotary_pos_emb(queries, keys, ref_cos, ref_sin)
+
+ torch.testing.assert_close(sin, ref_sin.squeeze(0))
+ torch.testing.assert_close(cos, ref_cos.squeeze(0))
+ torch.testing.assert_close(keys_rot, ref_keys_rot)
+ torch.testing.assert_close(queries_rot, ref_queries_rot)
+
+
+GPT_CONFIG_124M = {
+ "vocab_size": 50257, # Vocabulary size
+ "context_length": 1024, # Context length
+ "emb_dim": 768, # Embedding dimension
+ "n_heads": 12, # Number of attention heads
+ "n_layers": 12, # Number of layers
+ "drop_rate": 0.1, # Dropout rate
+ "qkv_bias": False # Query-Key-Value bias
+}
+
+
+def test_rescale():
+
+ new_theta = rescale_theta(
+ theta_old=500_000.,
+ context_length_old=131_072,
+ context_length_new=8192
+ )
+ assert new_theta == 31250.
+
+ old_theta = rescale_theta(
+ theta_old=new_theta,
+ context_length_old=8192,
+ context_length_new=131_072
+ )
+ assert old_theta == 500_000.
+
+
+@pytest.mark.parametrize("ModelClass", [Llama3Model])
+def test_gpt_model_variants(ModelClass):
+ torch.manual_seed(123)
+ model = ModelClass(LLAMA32_CONFIG_1B)
+ model.eval()
+
+ start_context = "Hello, I am"
+
+ tokenizer = tiktoken.get_encoding("gpt2")
+ encoded = tokenizer.encode(start_context)
+ encoded_tensor = torch.tensor(encoded).unsqueeze(0)
+
+ print(f"\n{50*'='}\n{22*' '}IN\n{50*'='}")
+ print("\nInput text:", start_context)
+ print("Encoded input text:", encoded)
+ print("encoded_tensor.shape:", encoded_tensor.shape)
+
+ out = generate_text_simple(
+ model=model,
+ idx=encoded_tensor,
+ max_new_tokens=10,
+ context_size=LLAMA32_CONFIG_1B["context_length"]
+ )
+ expect = torch.tensor([
+ [15496, 11, 314, 716, 78563, 89362, 19616, 115725, 114917,
+ 97198, 60342, 19108, 100752, 98969]
+ ])
+ assert torch.equal(expect, out)
diff --git a/pyproject.toml b/pyproject.toml
index d1bda8f..f0805c0 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -4,7 +4,7 @@ build-backend = "setuptools.build_meta"
[project]
name = "llms-from-scratch"
-version = "1.0.2"
+version = "1.0.5"
description = "Implement a ChatGPT-like LLM in PyTorch from scratch, step by step"
readme = "README.md"
requires-python = ">=3.10"