28 KiB
LightRAG Server and WebUI
The LightRAG Server is designed to provide a Web UI and API support. The Web UI facilitates document indexing, knowledge graph exploration, and a simple RAG query interface. LightRAG Server also provides an Ollama-compatible interface, aiming to emulate LightRAG as an Ollama chat model. This allows AI chat bots, such as Open WebUI, to access LightRAG easily.



Getting Started
Installation
- Install from PyPI
pip install "lightrag-hku[api]"
- Installation from Source
# Clone the repository
git clone https://github.com/HKUDS/lightrag.git
# Change to the repository directory
cd lightrag
# create a Python virtual environment if necessary
# Install in editable mode with API support
pip install -e ".[api]"
Before Starting LightRAG Server
LightRAG necessitates the integration of both an LLM (Large Language Model) and an Embedding Model to effectively execute document indexing and querying operations. Prior to the initial deployment of the LightRAG server, it is essential to configure the settings for both the LLM and the Embedding Model. LightRAG supports binding to various LLM/Embedding backends:
- ollama
- lollms
- openai or openai compatible
- azure_openai
It is recommended to use environment variables to configure the LightRAG Server. There is an example environment variable file named env.example in the root directory of the project. Please copy this file to the startup directory and rename it to .env. After that, you can modify the parameters related to the LLM and Embedding models in the .env file. It is important to note that the LightRAG Server will load the environment variables from .env into the system environment variables each time it starts. LightRAG Server will prioritize the settings in the system environment variables to .env file.
Since VS Code with the Python extension may automatically load the .env file in the integrated terminal, please open a new terminal session after each modification to the .env file.
Here are some examples of common settings for LLM and Embedding models:
- OpenAI LLM + Ollama Embedding:
LLM_BINDING=openai
LLM_MODEL=gpt-4o
LLM_BINDING_HOST=https://api.openai.com/v1
LLM_BINDING_API_KEY=your_api_key
### Max tokens sent to LLM (less than model context size)
MAX_TOKENS=32768
EMBEDDING_BINDING=ollama
EMBEDDING_BINDING_HOST=http://localhost:11434
EMBEDDING_MODEL=bge-m3:latest
EMBEDDING_DIM=1024
# EMBEDDING_BINDING_API_KEY=your_api_key
- Ollama LLM + Ollama Embedding:
LLM_BINDING=ollama
LLM_MODEL=mistral-nemo:latest
LLM_BINDING_HOST=http://localhost:11434
# LLM_BINDING_API_KEY=your_api_key
### Max tokens sent to LLM (based on your Ollama Server capacity)
MAX_TOKENS=8192
EMBEDDING_BINDING=ollama
EMBEDDING_BINDING_HOST=http://localhost:11434
EMBEDDING_MODEL=bge-m3:latest
EMBEDDING_DIM=1024
# EMBEDDING_BINDING_API_KEY=your_api_key
Starting LightRAG Server
The LightRAG Server supports two operational modes:
- The simple and efficient Uvicorn mode:
lightrag-server
- The multiprocess Gunicorn + Uvicorn mode (production mode, not supported on Windows environments):
lightrag-gunicorn --workers 4
The .env file must be placed in the startup directory.
Upon launching, the LightRAG Server will create a documents directory (default is ./inputs) and a data directory (default is ./rag_storage). This allows you to initiate multiple instances of LightRAG Server from different directories, with each instance configured to listen on a distinct network port.
Here are some commonly used startup parameters:
--host: Server listening address (default: 0.0.0.0)--port: Server listening port (default: 9621)--timeout: LLM request timeout (default: 150 seconds)--log-level: Logging level (default: INFO)--input-dir: Specifying the directory to scan for documents (default: ./inputs)
- The requirement for the .env file to be in the startup directory is intentionally designed this way. The purpose is to support users in launching multiple LightRAG instances simultaneously, allowing different .env files for different instances.
- After changing the .env file, you need to open a new terminal to make the new settings take effect. This because the LightRAG Server will load the environment variables from .env into the system environment variables each time it starts, and LightRAG Server will prioritize the settings in the system environment variables.
Launching LightRAG Server with Docker
- Clone the repository:
git clone https://github.com/HKUDS/LightRAG.git
cd LightRAG
-
Prepare the .env file: Create a personalized .env file from sample file
env.example. Configure the LLM and embedding parameters according to your requirements. -
Start the LightRAG Server using the following commands:
docker compose up
# Use --build if you have pulled a new version
docker compose up --build
Deploying LightRAG Server with docker without cloneing the repository
- Create a working folder for LightRAG Server:
mkdir lightrag
cd lightrag
- Create a docker compose file named docker-compose.yml:
services:
lightrag:
container_name: lightrag
image: ghcr.io/hkuds/lightrag:latest
ports:
- "${PORT:-9621}:9621"
volumes:
- ./data/rag_storage:/app/data/rag_storage
- ./data/inputs:/app/data/inputs
- ./config.ini:/app/config.ini
- ./.env:/app/.env
env_file:
- .env
restart: unless-stopped
extra_hosts:
- "host.docker.internal:host-gateway"
-
Prepare the .env file: Create a personalized .env file from sample file
env.example. Configure the LLM and embedding parameters according to your requirements. -
Start the LightRAG Server using the following commands:
docker compose up
Historical versions of LightRAG docker images can be found here: LightRAG Docker Images
Auto scan on startup
When starting any of the servers with the --auto-scan-at-startup parameter, the system will automatically:
- Scan for new files in the input directory
- Index new documents that aren't already in the database
- Make all content immediately available for RAG queries
The
--input-dirparameter specifies the input directory to scan. You can trigger the input directory scan from the Web UI.
Multiple workers for Gunicorn + Uvicorn
The LightRAG Server can operate in the Gunicorn + Uvicorn preload mode. Gunicorn's multiple worker (multiprocess) capability prevents document indexing tasks from blocking RAG queries. Using CPU-exhaustive document extraction tools, such as docling, can lead to the entire system being blocked in pure Uvicorn mode.
Though LightRAG Server uses one worker to process the document indexing pipeline, with the async task support of Uvicorn, multiple files can be processed in parallel. The bottleneck of document indexing speed mainly lies with the LLM. If your LLM supports high concurrency, you can accelerate document indexing by increasing the concurrency level of the LLM. Below are several environment variables related to concurrent processing, along with their default values:
### Number of worker processes, not greater than (2 x number_of_cores) + 1
WORKERS=2
### Number of parallel files to process in one batch
MAX_PARALLEL_INSERT=2
### Max concurrent requests to the LLM
MAX_ASYNC=4
Install LightRAG as a Linux Service
Create your service file lightrag.service from the sample file: lightrag.service.example. Modify the WorkingDirectory and ExecStart in the service file:
Description=LightRAG Ollama Service
WorkingDirectory=<lightrag installed directory>
ExecStart=<lightrag installed directory>/lightrag/api/lightrag-api
Modify your service startup script: lightrag-api. Change your Python virtual environment activation command as needed:
#!/bin/bash
# your python virtual environment activation
source /home/netman/lightrag-xyj/venv/bin/activate
# start lightrag api server
lightrag-server
Install LightRAG service. If your system is Ubuntu, the following commands will work:
sudo cp lightrag.service /etc/systemd/system/
sudo systemctl daemon-reload
sudo systemctl start lightrag.service
sudo systemctl status lightrag.service
sudo systemctl enable lightrag.service
Ollama Emulation
We provide Ollama-compatible interfaces for LightRAG, aiming to emulate LightRAG as an Ollama chat model. This allows AI chat frontends supporting Ollama, such as Open WebUI, to access LightRAG easily.
Connect Open WebUI to LightRAG
After starting the lightrag-server, you can add an Ollama-type connection in the Open WebUI admin panel. And then a model named lightrag:latest will appear in Open WebUI's model management interface. Users can then send queries to LightRAG through the chat interface. You should install LightRAG as a service for this use case.
Open WebUI uses an LLM to do the session title and session keyword generation task. So the Ollama chat completion API detects and forwards OpenWebUI session-related requests directly to the underlying LLM. Screenshot from Open WebUI:
Choose Query mode in chat
The default query mode is hybrid if you send a message (query) from the Ollama interface of LightRAG. You can select query mode by sending a message with a query prefix.
A query prefix in the query string can determine which LightRAG query mode is used to generate the response for the query. The supported prefixes include:
/local
/global
/hybrid
/naive
/mix
/bypass
/context
/localcontext
/globalcontext
/hybridcontext
/naivecontext
/mixcontext
For example, the chat message /mix What's LightRAG? will trigger a mix mode query for LightRAG. A chat message without a query prefix will trigger a hybrid mode query by default.
/bypass is not a LightRAG query mode; it will tell the API Server to pass the query directly to the underlying LLM, including the chat history. So the user can use the LLM to answer questions based on the chat history. If you are using Open WebUI as a front end, you can just switch the model to a normal LLM instead of using the /bypass prefix.
/context is also not a LightRAG query mode; it will tell LightRAG to return only the context information prepared for the LLM. You can check the context if it's what you want, or process the context by yourself.
Add user prompt in chat
When using LightRAG for content queries, avoid combining the search process with unrelated output processing, as this significantly impacts query effectiveness. User prompt is specifically designed to address this issue — it does not participate in the RAG retrieval phase, but rather guides the LLM on how to process the retrieved results after the query is completed. We can append square brackets to the query prefix to provide the LLM with the user prompt:
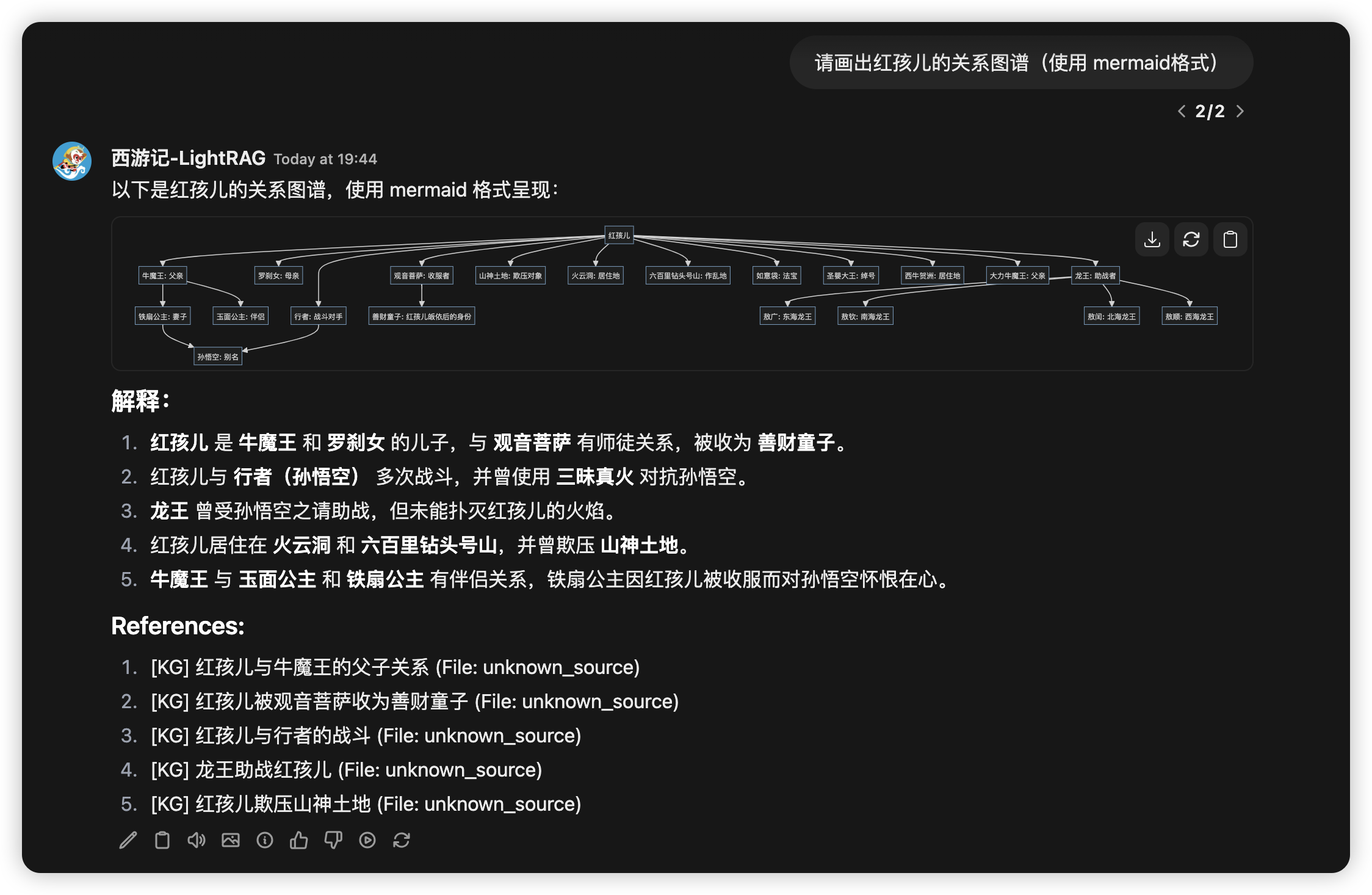
/[Use mermaid format for diagrams] Please draw a character relationship diagram for Scrooge
/mix[Use mermaid format for diagrams] Please draw a character relationship diagram for Scrooge
API Key and Authentication
By default, the LightRAG Server can be accessed without any authentication. We can configure the server with an API Key or account credentials to secure it.
- API Key:
LIGHTRAG_API_KEY=your-secure-api-key-here
WHITELIST_PATHS=/health,/api/*
Health check and Ollama emulation endpoints are excluded from API Key check by default.
- Account credentials (the Web UI requires login before access can be granted):
LightRAG API Server implements JWT-based authentication using the HS256 algorithm. To enable secure access control, the following environment variables are required:
# For jwt auth
AUTH_ACCOUNTS='admin:admin123,user1:pass456'
TOKEN_SECRET='your-key'
TOKEN_EXPIRE_HOURS=4
Currently, only the configuration of an administrator account and password is supported. A comprehensive account system is yet to be developed and implemented.
If Account credentials are not configured, the Web UI will access the system as a Guest. Therefore, even if only an API Key is configured, all APIs can still be accessed through the Guest account, which remains insecure. Hence, to safeguard the API, it is necessary to configure both authentication methods simultaneously.
For Azure OpenAI Backend
Azure OpenAI API can be created using the following commands in Azure CLI (you need to install Azure CLI first from https://docs.microsoft.com/en-us/cli/azure/install-azure-cli):
# Change the resource group name, location, and OpenAI resource name as needed
RESOURCE_GROUP_NAME=LightRAG
LOCATION=swedencentral
RESOURCE_NAME=LightRAG-OpenAI
az login
az group create --name $RESOURCE_GROUP_NAME --location $LOCATION
az cognitiveservices account create --name $RESOURCE_NAME --resource-group $RESOURCE_GROUP_NAME --kind OpenAI --sku S0 --location swedencentral
az cognitiveservices account deployment create --resource-group $RESOURCE_GROUP_NAME --model-format OpenAI --name $RESOURCE_NAME --deployment-name gpt-4o --model-name gpt-4o --model-version "2024-08-06" --sku-capacity 100 --sku-name "Standard"
az cognitiveservices account deployment create --resource-group $RESOURCE_GROUP_NAME --model-format OpenAI --name $RESOURCE_NAME --deployment-name text-embedding-3-large --model-name text-embedding-3-large --model-version "1" --sku-capacity 80 --sku-name "Standard"
az cognitiveservices account show --name $RESOURCE_NAME --resource-group $RESOURCE_GROUP_NAME --query "properties.endpoint"
az cognitiveservices account keys list --name $RESOURCE_NAME -g $RESOURCE_GROUP_NAME
The output of the last command will give you the endpoint and the key for the OpenAI API. You can use these values to set the environment variables in the .env file.
# Azure OpenAI Configuration in .env:
LLM_BINDING=azure_openai
LLM_BINDING_HOST=your-azure-endpoint
LLM_MODEL=your-model-deployment-name
LLM_BINDING_API_KEY=your-azure-api-key
### API version is optional, defaults to latest version
AZURE_OPENAI_API_VERSION=2024-08-01-preview
### If using Azure OpenAI for embeddings
EMBEDDING_BINDING=azure_openai
EMBEDDING_MODEL=your-embedding-deployment-name
LightRAG Server Configuration in Detail
The API Server can be configured in three ways (highest priority first):
- Command line arguments
- Environment variables or .env file
- Config.ini (Only for storage configuration)
Most of the configurations come with default settings; check out the details in the sample file: .env.example. Data storage configuration can also be set by config.ini. A sample file config.ini.example is provided for your convenience.
LLM and Embedding Backend Supported
LightRAG supports binding to various LLM/Embedding backends:
- ollama
- lollms
- openai & openai compatible
- azure_openai
Use environment variables LLM_BINDING or CLI argument --llm-binding to select the LLM backend type. Use environment variables EMBEDDING_BINDING or CLI argument --embedding-binding to select the Embedding backend type.
Entity Extraction Configuration
- ENABLE_LLM_CACHE_FOR_EXTRACT: Enable LLM cache for entity extraction (default: true)
It's very common to set ENABLE_LLM_CACHE_FOR_EXTRACT to true for a test environment to reduce the cost of LLM calls.
Storage Types Supported
LightRAG uses 4 types of storage for different purposes:
- KV_STORAGE: llm response cache, text chunks, document information
- VECTOR_STORAGE: entities vectors, relation vectors, chunks vectors
- GRAPH_STORAGE: entity relation graph
- DOC_STATUS_STORAGE: document indexing status
Each storage type has several implementations:
- KV_STORAGE supported implementations:
JsonKVStorage JsonFile (default)
PGKVStorage Postgres
RedisKVStorage Redis
MongoKVStorage MongoDB
- GRAPH_STORAGE supported implementations:
NetworkXStorage NetworkX (default)
Neo4JStorage Neo4J
PGGraphStorage PostgreSQL with AGE plugin
Testing has shown that Neo4J delivers superior performance in production environments compared to PostgreSQL with AGE plugin.
- VECTOR_STORAGE supported implementations:
NanoVectorDBStorage NanoVector (default)
PGVectorStorage Postgres
MilvusVectorDBStorage Milvus
ChromaVectorDBStorage Chroma
FaissVectorDBStorage Faiss
QdrantVectorDBStorage Qdrant
MongoVectorDBStorage MongoDB
- DOC_STATUS_STORAGE: supported implementations:
JsonDocStatusStorage JsonFile (default)
PGDocStatusStorage Postgres
MongoDocStatusStorage MongoDB
How to Select Storage Implementation
You can select storage implementation by environment variables. You can set the following environment variables to a specific storage implementation name before the first start of the API Server:
LIGHTRAG_KV_STORAGE=PGKVStorage
LIGHTRAG_VECTOR_STORAGE=PGVectorStorage
LIGHTRAG_GRAPH_STORAGE=PGGraphStorage
LIGHTRAG_DOC_STATUS_STORAGE=PGDocStatusStorage
You cannot change storage implementation selection after adding documents to LightRAG. Data migration from one storage implementation to another is not supported yet. For further information, please read the sample env file or config.ini file.
LightRAG API Server Command Line Options
| Parameter | Default | Description |
|---|---|---|
| --host | 0.0.0.0 | Server host |
| --port | 9621 | Server port |
| --working-dir | ./rag_storage | Working directory for RAG storage |
| --input-dir | ./inputs | Directory containing input documents |
| --max-async | 4 | Maximum number of async operations |
| --max-tokens | 32768 | Maximum token size |
| --timeout | 150 | Timeout in seconds. None for infinite timeout (not recommended) |
| --log-level | INFO | Logging level (DEBUG, INFO, WARNING, ERROR, CRITICAL) |
| --verbose | - | Verbose debug output (True, False) |
| --key | None | API key for authentication. Protects the LightRAG server against unauthorized access |
| --ssl | False | Enable HTTPS |
| --ssl-certfile | None | Path to SSL certificate file (required if --ssl is enabled) |
| --ssl-keyfile | None | Path to SSL private key file (required if --ssl is enabled) |
| --top-k | 50 | Number of top-k items to retrieve; corresponds to entities in "local" mode and relationships in "global" mode. |
| --cosine-threshold | 0.4 | The cosine threshold for nodes and relation retrieval, works with top-k to control the retrieval of nodes and relations. |
| --llm-binding | ollama | LLM binding type (lollms, ollama, openai, openai-ollama, azure_openai) |
| --embedding-binding | ollama | Embedding binding type (lollms, ollama, openai, azure_openai) |
| --auto-scan-at-startup | - | Scan input directory for new files and start indexing |
.env Examples
### Server Configuration
# HOST=0.0.0.0
PORT=9621
WORKERS=2
### Settings for document indexing
ENABLE_LLM_CACHE_FOR_EXTRACT=true
SUMMARY_LANGUAGE=Chinese
MAX_PARALLEL_INSERT=2
### LLM Configuration (Use valid host. For local services installed with docker, you can use host.docker.internal)
TIMEOUT=200
TEMPERATURE=0.0
MAX_ASYNC=4
MAX_TOKENS=32768
LLM_BINDING=openai
LLM_MODEL=gpt-4o-mini
LLM_BINDING_HOST=https://api.openai.com/v1
LLM_BINDING_API_KEY=your-api-key
### Embedding Configuration (Use valid host. For local services installed with docker, you can use host.docker.internal)
EMBEDDING_MODEL=bge-m3:latest
EMBEDDING_DIM=1024
EMBEDDING_BINDING=ollama
EMBEDDING_BINDING_HOST=http://localhost:11434
### For JWT Auth
# AUTH_ACCOUNTS='admin:admin123,user1:pass456'
# TOKEN_SECRET=your-key-for-LightRAG-API-Server-xxx
# TOKEN_EXPIRE_HOURS=48
# LIGHTRAG_API_KEY=your-secure-api-key-here-123
# WHITELIST_PATHS=/api/*
# WHITELIST_PATHS=/health,/api/*
Document and Chunk Processing Login Clarification
The document processing pipeline in LightRAG is somewhat complex and is divided into two primary stages: the Extraction stage (entity and relationship extraction) and the Merging stage (entity and relationship merging). There are two key parameters that control pipeline concurrency: the maximum number of files processed in parallel (MAX_PARALLEL_INSERT) and the maximum number of concurrent LLM requests (MAX_ASYNC). The workflow is described as follows:
- MAX_PARALLEL_INSERT controls the number of files processed in parallel during the extraction stage.
- MAX_ASYNC limits the total number of concurrent LLM requests in the system, including those for querying, extraction, and merging. LLM requests have different priorities: query operations have the highest priority, followed by merging, and then extraction.
- Within a single file, entity and relationship extractions from different text blocks are processed concurrently, with the degree of concurrency set by MAX_ASYNC. Only after MAX_ASYNC text blocks are processed will the system proceed to the next batch within the same file.
- The merging stage begins only after all text blocks in a file have completed entity and relationship extraction. When a file enters the merging stage, the pipeline allows the next file to begin extraction.
- Since the extraction stage is generally faster than merging, the actual number of files being processed concurrently may exceed MAX_PARALLEL_INSERT, as this parameter only controls parallelism during the extraction stage.
- To prevent race conditions, the merging stage does not support concurrent processing of multiple files; only one file can be merged at a time, while other files must wait in queue.
- Each file is treated as an atomic processing unit in the pipeline. A file is marked as successfully processed only after all its text blocks have completed extraction and merging. If any error occurs during processing, the entire file is marked as failed and must be reprocessed.
- When a file is reprocessed due to errors, previously processed text blocks can be quickly skipped thanks to LLM caching. Although LLM cache is also utilized during the merging stage, inconsistencies in merging order may limit its effectiveness in this stage.
- If an error occurs during extraction, the system does not retain any intermediate results. If an error occurs during merging, already merged entities and relationships might be preserved; when the same file is reprocessed, re-extracted entities and relationships will be merged with the existing ones, without impacting the query results.
- At the end of the merging stage, all entity and relationship data are updated in the vector database. Should an error occur at this point, some updates may be retained. However, the next processing attempt will overwrite previous results, ensuring that successfully reprocessed files do not affect the integrity of future query results.
Large files should be divided into smaller segments to enable incremental processing. Reprocessing of failed files can be initiated by pressing the "Scan" button on the web UI.
API Endpoints
All servers (LoLLMs, Ollama, OpenAI and Azure OpenAI) provide the same REST API endpoints for RAG functionality. When the API Server is running, visit:
- Swagger UI: http://localhost:9621/docs
- ReDoc: http://localhost:9621/redoc
You can test the API endpoints using the provided curl commands or through the Swagger UI interface. Make sure to:
- Start the appropriate backend service (LoLLMs, Ollama, or OpenAI)
- Start the RAG server
- Upload some documents using the document management endpoints
- Query the system using the query endpoints
- Trigger document scan if new files are put into the inputs directory
Query Endpoints:
POST /query
Query the RAG system with options for different search modes.
curl -X POST "http://localhost:9621/query" \
-H "Content-Type: application/json" \
-d '{"query": "Your question here", "mode": "hybrid"}'
POST /query/stream
Stream responses from the RAG system.
curl -X POST "http://localhost:9621/query/stream" \
-H "Content-Type: application/json" \
-d '{"query": "Your question here", "mode": "hybrid"}'
Document Management Endpoints:
POST /documents/text
Insert text directly into the RAG system.
curl -X POST "http://localhost:9621/documents/text" \
-H "Content-Type: application/json" \
-d '{"text": "Your text content here", "description": "Optional description"}'
POST /documents/file
Upload a single file to the RAG system.
curl -X POST "http://localhost:9621/documents/file" \
-F "file=@/path/to/your/document.txt" \
-F "description=Optional description"
POST /documents/batch
Upload multiple files at once.
curl -X POST "http://localhost:9621/documents/batch" \
-F "files=@/path/to/doc1.txt" \
-F "files=@/path/to/doc2.txt"
POST /documents/scan
Trigger document scan for new files in the input directory.
curl -X POST "http://localhost:9621/documents/scan" --max-time 1800
Adjust max-time according to the estimated indexing time for all new files.
DELETE /documents
Clear all documents from the RAG system.
curl -X DELETE "http://localhost:9621/documents"
Ollama Emulation Endpoints:
GET /api/version
Get Ollama version information.
curl http://localhost:9621/api/version
GET /api/tags
Get available Ollama models.
curl http://localhost:9621/api/tags
POST /api/chat
Handle chat completion requests. Routes user queries through LightRAG by selecting query mode based on query prefix. Detects and forwards OpenWebUI session-related requests (for metadata generation task) directly to the underlying LLM.
curl -N -X POST http://localhost:9621/api/chat -H "Content-Type: application/json" -d \
'{"model":"lightrag:latest","messages":[{"role":"user","content":"猪八戒是谁"}],"stream":true}'
For more information about Ollama API, please visit: Ollama API documentation
POST /api/generate
Handle generate completion requests. For compatibility purposes, the request is not processed by LightRAG, and will be handled by the underlying LLM model.
Utility Endpoints:
GET /health
Check server health and configuration.
curl "http://localhost:9621/health"