diff --git a/applications/多模态表单识别.md b/applications/多模态表单识别.md
index e64a22e169..d47bbe7704 100644
--- a/applications/多模态表单识别.md
+++ b/applications/多模态表单识别.md
@@ -16,14 +16,14 @@
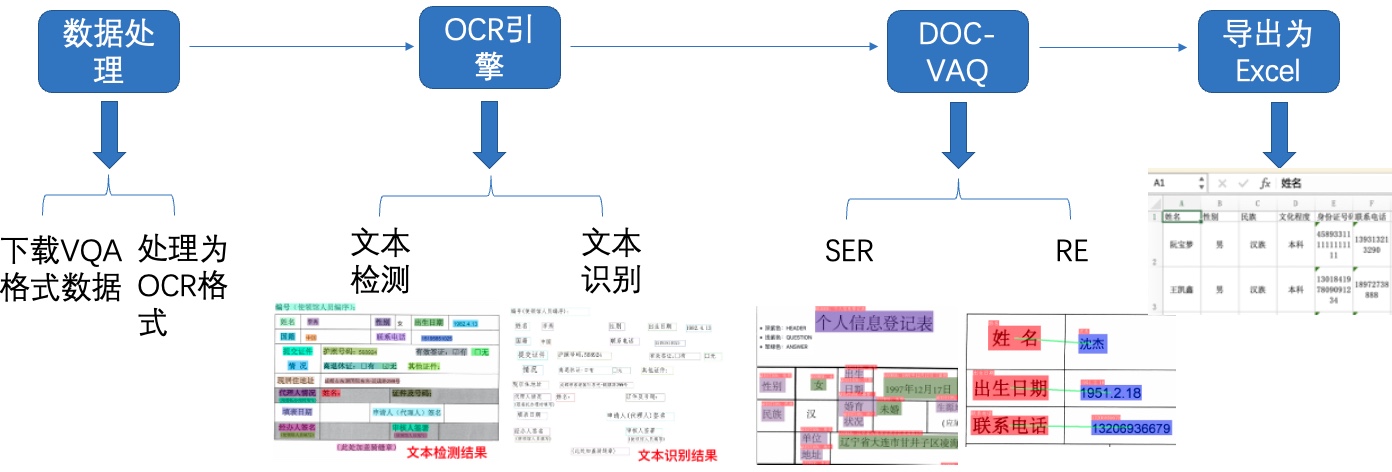 图1 多模态表单识别流程图
-注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3815918)(配备Tesla V100、A100等高级算力资源)
+注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3884375)(配备Tesla V100、A100等高级算力资源)
# 2 安装说明
-下载PaddleOCR源码,本项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
+下载PaddleOCR源码,上述AIStudio项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
```python
@@ -33,7 +33,7 @@
```python
# 如仍需安装or安装更新,可以执行以下步骤
-! git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
+# ! git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
# ! git clone https://gitee.com/PaddlePaddle/PaddleOCR
```
@@ -290,7 +290,7 @@ Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
图1 多模态表单识别流程图
-注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3815918)(配备Tesla V100、A100等高级算力资源)
+注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3884375)(配备Tesla V100、A100等高级算力资源)
# 2 安装说明
-下载PaddleOCR源码,本项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
+下载PaddleOCR源码,上述AIStudio项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
```python
@@ -33,7 +33,7 @@
```python
# 如仍需安装or安装更新,可以执行以下步骤
-! git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
+# ! git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
# ! git clone https://gitee.com/PaddlePaddle/PaddleOCR
```
@@ -290,7 +290,7 @@ Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
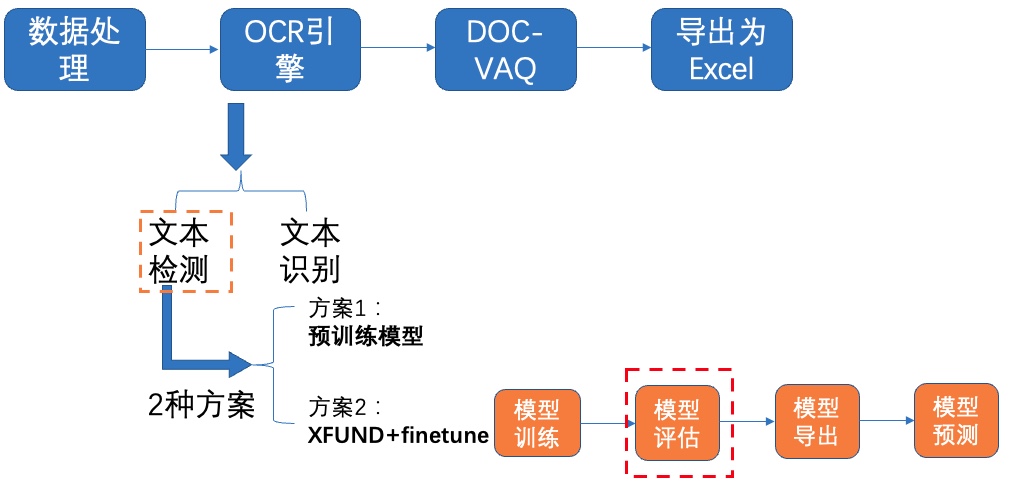 图8 文本检测方案2-模型评估
-使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/ch_db_mv3-student1600-finetune/best_accuracy`
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/ch_db_mv3-student1600-finetune/best_accuracy`,[模型下载地址](https://paddleocr.bj.bcebos.com/fanliku/sheet_recognition/ch_db_mv3-student1600-finetune.zip)
```python
@@ -538,7 +538,7 @@ Train.dataset.ratio_list:动态采样
图16 文本识别方案3-模型评估
-使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/rec_mobile_pp-OCRv2-student-readldata/best_accuracy`
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/rec_mobile_pp-OCRv2-student-readldata/best_accuracy`,[模型下载地址](https://paddleocr.bj.bcebos.com/fanliku/sheet_recognition/rec_mobile_pp-OCRv2-student-realdata.zip)
```python
diff --git a/ppstructure/docs/table/recovery.jpg b/ppstructure/docs/table/recovery.jpg
new file mode 100644
index 0000000000..bee2e2fb34
Binary files /dev/null and b/ppstructure/docs/table/recovery.jpg differ
diff --git a/ppstructure/predict_system.py b/ppstructure/predict_system.py
index 7f18fcdf8e..b0ede5f3a1 100644
--- a/ppstructure/predict_system.py
+++ b/ppstructure/predict_system.py
@@ -23,6 +23,7 @@ sys.path.append(os.path.abspath(os.path.join(__dir__, '..')))
os.environ["FLAGS_allocator_strategy"] = 'auto_growth'
import cv2
import json
+import numpy as np
import time
import logging
from copy import deepcopy
@@ -33,6 +34,7 @@ from ppocr.utils.logging import get_logger
from tools.infer.predict_system import TextSystem
from ppstructure.table.predict_table import TableSystem, to_excel
from ppstructure.utility import parse_args, draw_structure_result
+from ppstructure.recovery.docx import convert_info_docx
logger = get_logger()
@@ -104,7 +106,12 @@ class StructureSystem(object):
return_ocr_result_in_table)
else:
if self.text_system is not None:
- filter_boxes, filter_rec_res = self.text_system(roi_img)
+ if args.recovery:
+ wht_im = np.ones(ori_im.shape, dtype=ori_im.dtype)
+ wht_im[y1:y2, x1:x2, :] = roi_img
+ filter_boxes, filter_rec_res = self.text_system(wht_im)
+ else:
+ filter_boxes, filter_rec_res = self.text_system(roi_img)
# remove style char
style_token = [
'
图8 文本检测方案2-模型评估
-使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/ch_db_mv3-student1600-finetune/best_accuracy`
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/ch_db_mv3-student1600-finetune/best_accuracy`,[模型下载地址](https://paddleocr.bj.bcebos.com/fanliku/sheet_recognition/ch_db_mv3-student1600-finetune.zip)
```python
@@ -538,7 +538,7 @@ Train.dataset.ratio_list:动态采样
图16 文本识别方案3-模型评估
-使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/rec_mobile_pp-OCRv2-student-readldata/best_accuracy`
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/rec_mobile_pp-OCRv2-student-readldata/best_accuracy`,[模型下载地址](https://paddleocr.bj.bcebos.com/fanliku/sheet_recognition/rec_mobile_pp-OCRv2-student-realdata.zip)
```python
diff --git a/ppstructure/docs/table/recovery.jpg b/ppstructure/docs/table/recovery.jpg
new file mode 100644
index 0000000000..bee2e2fb34
Binary files /dev/null and b/ppstructure/docs/table/recovery.jpg differ
diff --git a/ppstructure/predict_system.py b/ppstructure/predict_system.py
index 7f18fcdf8e..b0ede5f3a1 100644
--- a/ppstructure/predict_system.py
+++ b/ppstructure/predict_system.py
@@ -23,6 +23,7 @@ sys.path.append(os.path.abspath(os.path.join(__dir__, '..')))
os.environ["FLAGS_allocator_strategy"] = 'auto_growth'
import cv2
import json
+import numpy as np
import time
import logging
from copy import deepcopy
@@ -33,6 +34,7 @@ from ppocr.utils.logging import get_logger
from tools.infer.predict_system import TextSystem
from ppstructure.table.predict_table import TableSystem, to_excel
from ppstructure.utility import parse_args, draw_structure_result
+from ppstructure.recovery.docx import convert_info_docx
logger = get_logger()
@@ -104,7 +106,12 @@ class StructureSystem(object):
return_ocr_result_in_table)
else:
if self.text_system is not None:
- filter_boxes, filter_rec_res = self.text_system(roi_img)
+ if args.recovery:
+ wht_im = np.ones(ori_im.shape, dtype=ori_im.dtype)
+ wht_im[y1:y2, x1:x2, :] = roi_img
+ filter_boxes, filter_rec_res = self.text_system(wht_im)
+ else:
+ filter_boxes, filter_rec_res = self.text_system(roi_img)
# remove style char
style_token = [
'', '', '', '', '',
@@ -118,7 +125,8 @@ class StructureSystem(object):
for token in style_token:
if token in rec_str:
rec_str = rec_str.replace(token, '')
- box += [x1, y1]
+ if not args.recovery:
+ box += [x1, y1]
res.append({
'text': rec_str,
'confidence': float(rec_conf),
@@ -192,6 +200,8 @@ def main(args):
# img_save_path = os.path.join(save_folder, img_name + '.jpg')
cv2.imwrite(img_save_path, draw_img)
logger.info('result save to {}'.format(img_save_path))
+ if args.recovery:
+ convert_info_docx(img, res, save_folder, img_name)
elapse = time.time() - starttime
logger.info("Predict time : {:.3f}s".format(elapse))
diff --git a/ppstructure/recovery/README.md b/ppstructure/recovery/README.md
new file mode 100644
index 0000000000..7e59367063
--- /dev/null
+++ b/ppstructure/recovery/README.md
@@ -0,0 +1,40 @@
+English | [简体中文](README_ch.md)
+
+- [Getting Started](#getting-started)
+ - [1. Introduction](#1)
+ - [2. Quick Start](#2)
+
+
+
+## 1. Introduction
+
+Layout recovery means that after OCR recognition, the content is still arranged like the original document pictures, and the paragraphs are output to word document in the same order.
+
+Layout recovery combines [layout analysis](../layout/README.md)、[table recognition](../table/README.md) to better recover images, tables, titles, etc.
+The following figure shows the result:
+
+
+

+
+
+