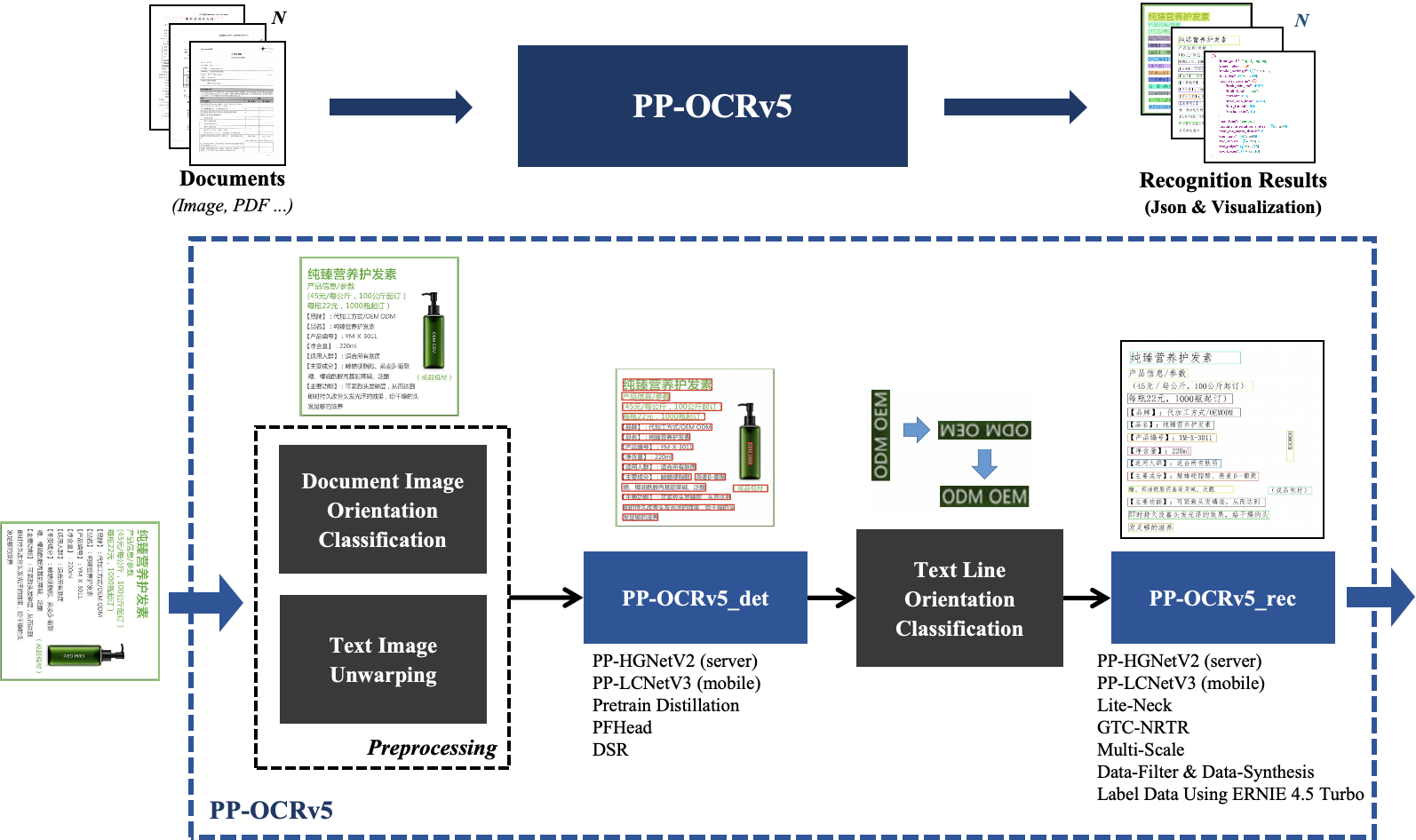
# 一、PP-OCRv5简介
**PP-OCRv5** 是PP-OCR新一代文字识别解决方案,该方案聚焦于多场景、多文字类型的文字识别。在文字类型方面,PP-OCRv5支持简体中文、中文拼音、繁体中文、英文、日文5大主流文字类型,在场景方面,PP-OCRv5升级了中英复杂手写体、竖排文本、生僻字等多种挑战性场景的识别能力。在内部多场景复杂评估集上,PP-OCRv5较PP-OCRv4端到端提升13个百分点。
# 二、关键指标
### 1. 文本检测指标
| 模型 |
手写中文 |
手写英文 |
印刷中文 |
印刷英文 |
繁体中文 |
古籍文本 |
日文 |
通用场景 |
拼音 |
旋转 |
扭曲 |
艺术字 |
平均 |
| PP-OCRv5_server_det |
0.803 |
0.841 |
0.945 |
0.917 |
0.815 |
0.676 |
0.772 |
0.797 |
0.671 |
0.8 |
0.876 |
0.673 |
0.827 |
| PP-OCRv4_server_det |
0.706 |
0.249 |
0.888 |
0.690 |
0.759 |
0.473 |
0.685 |
0.715 |
0.542 |
0.366 |
0.775 |
0.583 |
0.662 |
| PP-OCRv5_mobile_det |
0.744 |
0.777 |
0.905 |
0.910 |
0.823 |
0.581 |
0.727 |
0.721 |
0.575 |
0.647 |
0.827 |
0.525 |
0.770 |
| PP-OCRv4_mobile_det |
0.583 |
0.369 |
0.872 |
0.773 |
0.663 |
0.231 |
0.634 |
0.710 |
0.430 |
0.299 |
0.715 |
0.549 |
0.624 |
对比PP-OCRv4,PP-OCRv5在所有检测场景下均有明显提升,尤其在手写、古籍、日文检测能力上表现更优。
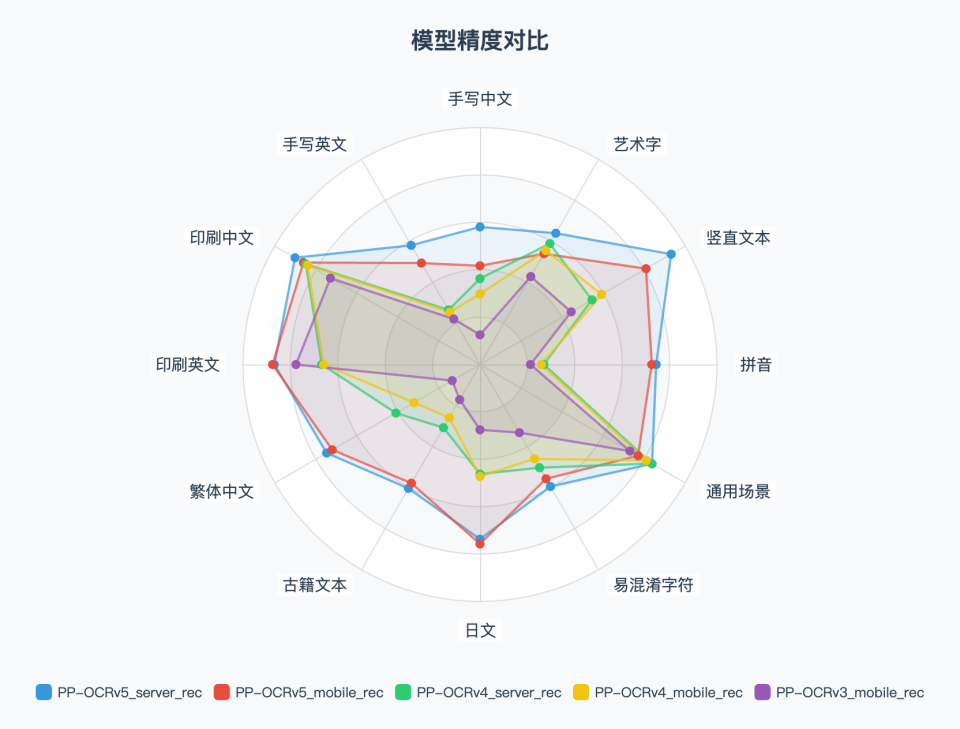
### 2. 文本识别指标
| 评估集类别 |
手写中文 |
手写英文 |
印刷中文 |
印刷英文 |
繁体中文 |
古籍文本 |
日文 |
易混淆字符 |
通用场景 |
拼音 |
竖直文本 |
艺术字 |
加权平均 |
| PP-OCRv5_server_rec |
0.5807 |
0.5806 |
0.9013 |
0.8679 |
0.7472 |
0.6039 |
0.7372 |
0.5946 |
0.8384 |
0.7435 |
0.9314 |
0.6397 |
0.8401 |
| PP-OCRv4_server_rec |
0.3626 |
0.2661 |
0.8486 |
0.6677 |
0.4097 |
0.3080 |
0.4623 |
0.5028 |
0.8362 |
0.2694 |
0.5455 |
0.5892 |
0.5735 |
| PP-OCRv5_mobile_rec |
0.4166 |
0.4944 |
0.8605 |
0.8753 |
0.7199 |
0.5786 |
0.7577 |
0.5570 |
0.7703 |
0.7248 |
0.8089 |
0.5398 |
0.8015 |
| PP-OCRv4_mobile_rec |
0.2980 |
0.2550 |
0.8398 |
0.6598 |
0.3218 |
0.2593 |
0.4724 |
0.4599 |
0.8106 |
0.2593 |
0.5924 |
0.5555 |
0.5301 |
单模型即可覆盖多语言和多类型文本,识别精度大幅领先前代产品和主流开源方案。
# 三、PP-OCRv5 Demo示例
更多示例
## 四、推理性能参考数据
测试环境:
- NVIDIA Tesla V100
- Intel Xeon Gold 6271C
- PaddlePaddle 3.0.0
在 200 张图像(包括通用图像与文档图像)上测试。测试时从磁盘读取图像,因此读图时间及其他额外开销也被包含在总耗时内。如果将图像提前载入到内存,可进一步减少平均每图约 25 ms 的时间开销。
如果不特别说明,则:
- 使用 PP-OCRv4_mobile_det 和 PP-OCRv4_mobile_rec 模型。
- 不使用文档图像方向分类、文本图像矫正、文本行方向分类。
- 将 `text_det_limit_type` 设置为 `"min"`、`text_det_limit_side_len` 设置为 `736`。
### 1. PP-OCRv5 与 PP-OCRv4 推理性能对比
| 配置 | 说明 |
| --- | --- |
| v5_mobile | 使用 PP-OCRv5_mobile_det 和 PP-OCRv5_mobile_rec 模型。 |
| v4_mobile | 使用 PP-OCRv4_mobile_det 和 PP-OCRv4_mobile_rec 模型。 |
| v5_server | 使用 PP-OCRv5_server_det 和 PP-OCRv5_server_rec 模型。 |
| v4_server | 使用 PP-OCRv4_server_det 和 PP-OCRv4_server_rec 模型。 |
**GPU:**
| 配置 | 平均每图耗时(s) | 平均每秒预测字符数量 | 平均 CPU 利用率(%) | 峰值 RAM 用量(MB) | 平均 RAM 用量(MB) | 平均 GPU 利用率(%) | 峰值 VRAM 用量(MB) | 平均 VRAM 用量(MB) |
|-----------|------------------|--------------------|--------------------|-------------------|-------------------|-------------------|-------------------|-------------------|
| v5_mobile | 0.62 | 1054.23 | 106.35 | 1829.36 | 1521.92 | 17.42 | 4190.00 | 3114.02 |
| v4_mobile | 0.29 | 2062.53 | 112.21 | 1713.10 | 1456.14 | 26.53 | 1304.00 | 1166.68 |
| v5_server | 0.74 | 878.84 | 105.68 | 1899.80 | 1569.46 | 34.39 | 5402.00 | 4683.93 |
| v4_server | 0.47 | 1322.06 | 108.06 | 1773.10 | 1518.94 | 55.25 | 6760.67 | 5788.02 |
**CPU:**
| 配置 | 平均每图耗时(s) | 平均每秒预测字符数量 | 平均 CPU 利用率(%) | 峰值 RAM 用量(MB) | 平均 RAM 用量(MB) |
| --------- | ---- | ------- | ------ | -------- | -------- |
| v5_mobile | 1.75 | 371.82 | 965.89 | 2219.98 | 1830.97 |
| v4_mobile | 1.37 | 444.27 | 1007.33 | 2090.53 | 1797.76 |
| v5_server | 4.34 | 149.98 | 990.24 | 4020.85 | 3137.20 |
| v4_server | 5.42 | 115.20 | 999.03 | 4018.35 | 3105.29 |
> 说明:PP-OCRv5 的识别模型使用了更大的字典,需要更长的推理时间,导致 PP-OCRv5 的推理速度慢于 PP-OCRv4。
### 2. 使用辅助功能对 PP-OCRv5 推理性能的影响
| 配置 | 说明 |
| --- | --- |
| base | 不使用文档图像方向分类、文本图像矫正、文本行方向分类。 |
| with_textline | 使用文本行方向分类,不使用文档图像方向分类、文本图像矫正。 |
| with_all | 使用文档图像方向分类、文本图像矫正、文本行方向分类。 |
**GPU:**
| 配置 | 平均每图耗时(s) | 平均每秒预测字符数量 | 平均 CPU 利用率(%) | 峰值 RAM 用量(MB) | 平均 RAM 用量(MB) | 平均GPU利用率(%) | 峰值 VRAM 用量(MB) | 平均 VRAM 用量(MB) |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| base | 0.62 | 1054.23 | 106.35 | 1829.36 | 1521.92 | 17.42 | 4190.00 | 3114.02 |
| with_textline | 0.64 | 1012.32 | 106.37 | 1867.69 | 1527.42 | 19.16 | 4198.00 | 3115.05 |
| with_all | 1.09 | 562.99 | 105.67 | 2381.53 | 1792.48 | 10.77 | 2480.00 | 2065.54 |
**CPU:**
| 配置 | 平均每图耗时(s) | 平均每秒预测字符数量 | 平均 CPU 利用率(%) | 峰值 RAM 用量(MB) | 平均 RAM 用量(MB) |
| --- | --- | --- | --- | --- | --- |
| base | 1.75 | 371.82 | 965.89 | 2219.98 | 1830.97 |
| with_textline | 1.87 | 347.61 | 972.08 | 2232.38 | 1822.13 |
| with_all | 3.13 | 195.25 | 828.37 | 2751.47 | 2179.70 |
> 说明:文本图像矫正等辅助功能会对端到端推理精度造成影响,因此并不一定使用的辅助功能越多、资源用量越大。
### 3. 文本检测模块输入缩放尺寸策略对 PP-OCRv5 推理性能的影响
| 配置 | 说明 |
| --- | --- |
| mobile_min_1280 | 使用 PP-OCRv5_mobile_det 和 PP-OCRv5_mobile_rec 模型,将 `text_det_limit_type` 设置为 `"min"`、`text_det_limit_side_len` 设置为 `1280`。 |
| mobile_min_736 | 使用 PP-OCRv5_mobile_det 和 PP-OCRv5_mobile_rec 模型,将 `text_det_limit_type` 设置为 `"min"`、`text_det_limit_side_len` 设置为 `736`。 |
| mobile_max_960 | 使用 PP-OCRv5_mobile_det 和 PP-OCRv5_mobile_rec 模型,将 `text_det_limit_type` 设置为 `"max"`、`text_det_limit_side_len` 设置为 `960`。 |
| mobile_max_640 | 使用 PP-OCRv5_mobile_det 和 PP-OCRv5_mobile_rec 模型,将 `text_det_limit_type` 设置为 `"max"`、`text_det_limit_side_len` 设置为 `640`。 |
| server_min_1280 | 使用 PP-OCRv5_server_det 和 PP-OCRv5_server_rec 模型,将 `text_det_limit_type` 设置为 `"min"`、`text_det_limit_side_len` 设置为 `1280`。 |
| server_min_736 | 使用 PP-OCRv5_server_det 和 PP-OCRv5_server_rec 模型,将 `text_det_limit_type` 设置为 `"min"`、`text_det_limit_side_len` 设置为 `736`。 |
| server_max_960 | 使用 PP-OCRv5_server_det 和 PP-OCRv5_server_rec 模型,将 `text_det_limit_type` 设置为 `"max"`、`text_det_limit_side_len` 设置为 `960`。 |
| server_max_640 | 使用 PP-OCRv5_server_det 和 PP-OCRv5_server_rec 模型,将 `text_det_limit_type` 设置为 `"max"`、`text_det_limit_side_len` 设置为 `640`。 |
**GPU:**
| 配置 | 平均每图耗时(s) | 平均每秒预测字符数量 | 平均 CPU 利用率(%) | 峰值 RAM 用量(MB) | 平均 RAM 用量(MB) | 平均GPU利用率(%) | 峰值 VRAM 用量(MB) | 平均 VRAM 用量(MB) |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| mobile_min_1280 | 0.66 | 985.77 | 109.52 | 1878.74 | 1536.43 | 18.01 | 4050.00 | 3407.33 |
| mobile_min_736 | 0.62 | 1054.23 | 106.35 | 1829.36 | 1521.92 | 17.42 | 4190.00 | 3114.02 |
| mobile_max_960 | 0.52 | 1206.68 | 104.01 | 1795.27 | 1484.73 | 18.66 | 2490.00 | 2173.91 |
| mobile_max_640 | 0.45 | 1353.49 | 103.32 | 1728.91 | 1470.64 | 18.55 | 2378.00 | 1998.62 |
| server_min_1280 | 0.86 | 759.10 | 107.81 | 1876.31 | 1572.20 | 37.33 | 10368.00 | 8287.41 |
| server_min_736 | 0.74 | 878.84 | 105.68 | 1899.80 | 1569.46 | 34.39 | 5402.00 | 4683.93 |
| server_max_960 | 0.64 | 988.85 | 103.61 | 1831.31 | 1544.26 | 30.29 | 2929.33 | 2079.90 |
| server_max_640 | 0.57 | 1036.90 | 102.89 | 1838.36 | 1532.50 | 28.91 | 3153.33 | 2743.40 |
**CPU:**
| 配置 | 平均每图耗时(s) | 平均每秒预测字符数量 | 平均 CPU 利用率(%) | 峰值 RAM 用量(MB) | 平均 RAM 用量(MB) |
| --- | --- | --- | --- | --- | --- |
| mobile_min_1280 | 2.00 | 326.44 | 976.83 | 2233.16 | 1867.94 |
| mobile_min_736 | 1.75 | 371.82 | 965.89 | 2219.98 | 1830.97 |
| mobile_max_960 | 1.49 | 422.62 | 969.11 | 2048.67 | 1677.82 |
| mobile_max_640 | 1.31 | 459.11 | 978.41 | 2023.25 | 1616.42 |
| server_min_1280 | 5.57 | 117.08 | 991.34 | 4452.39 | 3286.19 |
| server_min_736 | 4.34 | 149.98 | 990.24 | 4020.85 | 3137.20 |
| server_max_960 | 3.39 | 186.59 | 984.67 | 3492.62 | 2977.13 |
| server_max_640 | 2.95 | 201.00 | 980.59 | 3342.38 | 2935.24 |
# 五、部署与二次开发
* **多系统支持**:兼容Windows、Linux、Mac等主流操作系统。
* **多硬件支持**:除了英伟达GPU外,还支持Intel CPU、昆仑芯、昇腾等新硬件推理和部署。
* **高性能推理插件**:推荐结合高性能推理插件进一步提升推理速度,详见[高性能推理指南](../../deployment/high_performance_inference.md)。
* **服务化部署**:支持高稳定性服务化部署方案,详见[服务化部署指南](../../deployment/serving.md)。
* **二次开发能力**:支持自定义数据集训练、字典扩展、模型微调。举例:如需增加韩文识别,可扩展字典并微调模型,无缝集成到现有产线,详见[文本检测模块使用教程](../../module_usage/text_detection.md)及[文本识别模块使用教程](../../module_usage/text_recognition.md)