25 KiB



🚀 مقدمة
منذ إصداره الأولي، حظي PaddleOCR بتقدير واسع النطاق في الأوساط الأكاديمية والصناعية والبحثية، بفضل خوارزمياته المتطورة وأدائه المثبت في تطبيقات العالم الحقيقي. وهو يدعم بالفعل مشاريع مفتوحة المصدر شهيرة مثل Umi-OCR، و OmniParser، و MinerU، و RAGFlow، مما يجعله مجموعة أدوات التعرف الضوئي على الحروف المفضلة للمطورين في جميع أنحاء العالم.
في 20 مايو 2025، كشف فريق PaddlePaddle عن PaddleOCR 3.0، المتوافق تمامًا مع الإصدار الرسمي لإطار العمل PaddlePaddle 3.0. يعزز هذا التحديث دقة التعرف على النصوص، ويضيف دعمًا لـ التعرف على أنواع نصوص متعددة و التعرف على الكتابة اليدوية، ويلبي الطلب المتزايد من التطبيقات القائمة على النماذج الكبيرة على التحليل عالي الدقة للمستندات المعقدة. عند دمجه مع ERNIE 4.5 Turbo، فإنه يعزز بشكل كبير دقة استخراج المعلومات الرئيسية. كما يقدم PaddleOCR 3.0 دعمًا لمسرعات الذكاء الاصطناعي الصينية غير المتجانسة مثل KUNLUNXIN و Ascend. للحصول على وثائق الاستخدام الكاملة، يرجى الرجوع إلى وثائق PaddleOCR 3.0.
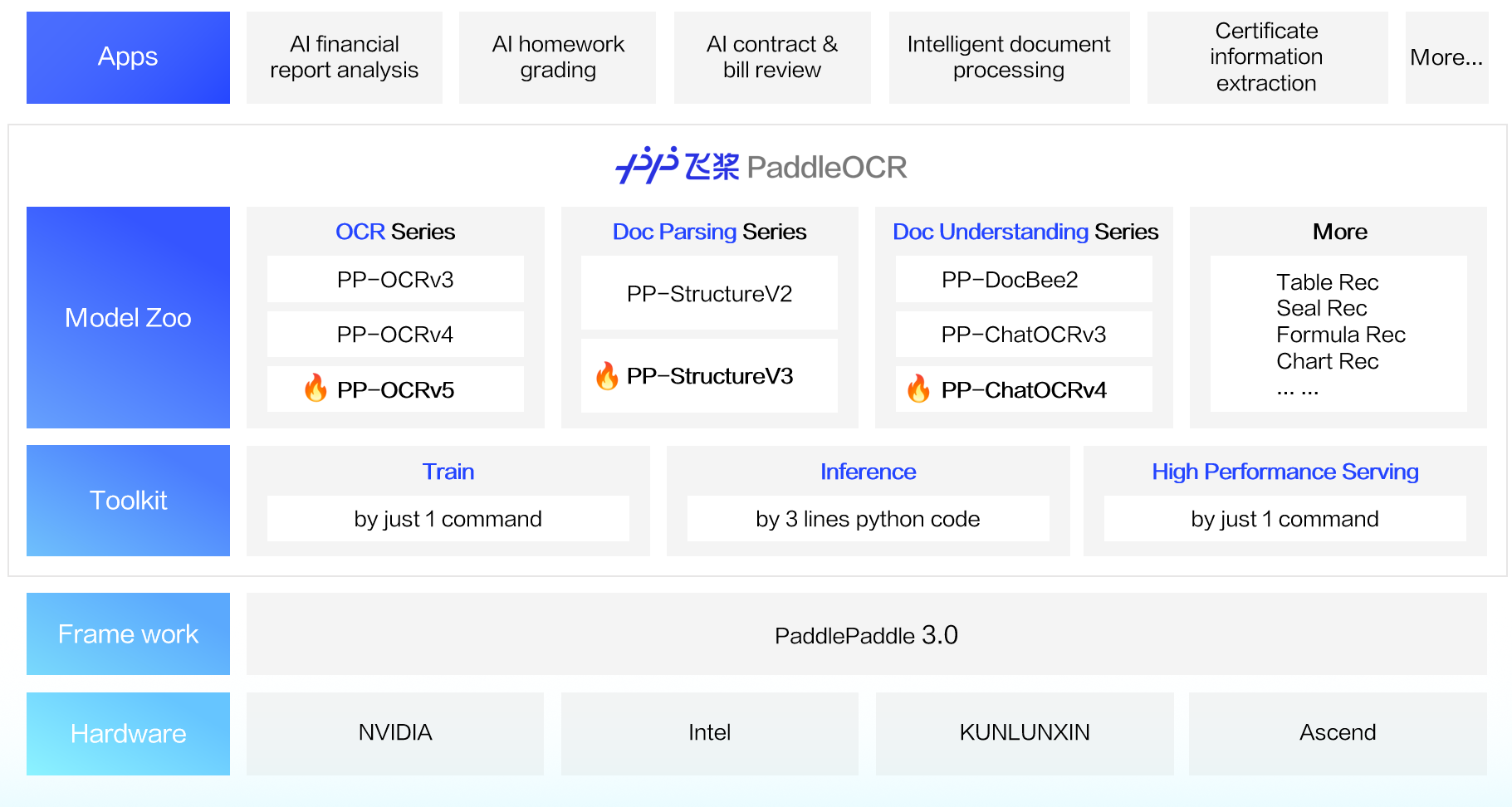
ثلاث ميزات رئيسية جديدة في PaddleOCR 3.0:
نموذج التعرف على النصوص في جميع السيناريوهات PP-OCRv5: نموذج واحد يعالج خمسة أنواع مختلفة من النصوص بالإضافة إلى الكتابة اليدوية المعقدة. زادت دقة التعرف الإجمالية بمقدار 13 نقطة مئوية عن الجيل السابق. تجربة مباشرة
حل تحليل المستندات العام PP-StructureV3: يقدم تحليلًا عالي الدقة لملفات PDF متعددة التخطيطات والسيناريوهات، متفوقًا على العديد من الحلول المفتوحة والمغلقة المصدر في المعايير العامة. تجربة مباشرة
حل فهم المستندات الذكي PP-ChatOCRv4: مدعوم أصلاً بنموذج ERNIE 4.5 Turbo، ويحقق دقة أعلى بنسبة 15 نقطة مئوية من سابقه. تجربة مباشرة
بالإضافة إلى توفير مكتبة نماذج متميزة، يقدم PaddleOCR 3.0 أيضًا أدوات سهلة الاستخدام تغطي تدريب النماذج والاستدلال ونشر الخدمات، حتى يتمكن المطورون من إدخال تطبيقات الذكاء الاصطناعي إلى الإنتاج بسرعة.
📣 آخر التحديثات
🔥🔥2025.06.26: إصدار PaddleOCR 3.0.3، يتضمن:
- تصحيح خلل: تم حل المشكلة التي لم يكن فيها معلمة
enable_mkldnnفعّالة، واستعادة السلوك الافتراضي باستخدام MKL-DNN للاستدلال بوحدة المعالجة المركزية.
🔥🔥2025.06.19: إصدار PaddleOCR 3.0.2، يتضمن:
- ميزات جديدة:
- تم تغيير مصدر التنزيل الافتراضي من
BOSإلىHuggingFace. يمكن للمستخدمين أيضًا تغيير متغير البيئةPADDLE_PDX_MODEL_SOURCEإلىBOSلإعادة تعيين مصدر تنزيل النموذج إلى Baidu Object Storage (BOS). - تمت إضافة أمثلة استدعاء الخدمة لست لغات — C++, Java, Go, C#, Node.js, و PHP — لخطوط الأنابيب مثل PP-OCRv5, PP-StructureV3, و PP-ChatOCRv4.
- تحسين خوارزمية فرز تقسيم التخطيط في خط أنابيب PP-StructureV3، مما يعزز منطق الفرز للتخطيطات العمودية المعقدة لتقديم نتائج أفضل.
- تحسين منطق اختيار النموذج: عند تحديد لغة وعدم تحديد إصدار النموذج، سيقوم النظام تلقائيًا بتحديد أحدث إصدار للنموذج يدعم تلك اللغة.
- تعيين حد أعلى افتراضي لحجم ذاكرة التخزين المؤقت لـ MKL-DNN لمنع النمو غير المحدود، مع السماح للمستخدمين أيضًا بتكوين سعة ذاكرة التخزين المؤقت.
- تحديث التكوينات الافتراضية للاستدلال عالي الأداء لدعم تسريع Paddle MKL-DNN وتحسين منطق الاختيار التلقائي للتكوين لخيارات أكثر ذكاءً.
- تعديل منطق الحصول على الجهاز الافتراضي لمراعاة الدعم الفعلي لأجهزة الحوسبة بواسطة إطار عمل Paddle المثبت، مما يجعل سلوك البرنامج أكثر بديهية.
- إضافة مثال Android لـ PP-OCRv5. التفاصيل.
- تم تغيير مصدر التنزيل الافتراضي من
- إصلاحات الأخطاء:
- إصلاح مشكلة عدم تفعيل بعض معلمات CLI في PP-StructureV3.
- حل مشكلة حيث لا تعمل
export_paddlex_config_to_yamlبشكل صحيح في بعض الحالات. - تصحيح التناقض بين السلوك الفعلي لـ
save_pathووصفه في الوثائق. - إصلاح أخطاء تعدد الخيوط المحتملة عند استخدام MKL-DNN في نشر الخدمة الأساسية.
- تصحيح أخطاء ترتيب القنوات في المعالجة المسبقة للصور لنموذج Latex-OCR.
- إصلاح أخطاء ترتيب القنوات في حفظ الصور المرئية داخل وحدة التعرف على النص.
- حل أخطاء ترتيب القنوات في نتائج الجداول المرئية داخل خط أنابيب PP-StructureV3.
- إصلاح مشكلة تجاوز السعة في حساب
overlap_ratioفي ظروف خاصة للغاية في خط أنابيب PP-StructureV3.
- تحسينات على الوثائق:
- تحديث وصف المعلمة
enable_mkldnnفي الوثائق لتعكس بدقة السلوك الفعلي للبرنامج. - إصلاح الأخطاء في الوثائق المتعلقة بمعلمات
langوocr_version. - إضافة تعليمات لتصدير ملفات تكوين خط الإنتاج عبر CLI.
- إصلاح الأعمدة المفقودة في جدول بيانات أداء PP-OCRv5.
- تحسين مقاييس الأداء لـ PP-StructureV3 عبر تكوينات مختلفة.
- تحديث وصف المعلمة
- أخرى:
- تخفيف قيود الإصدار على التبعيات مثل numpy و pandas، واستعادة الدعم لـ Python 3.12.
سجل التحديثات
🔥🔥 2025.06.05: إصدار PaddleOCR 3.0.1، يتضمن:
- تحسين بعض النماذج وتكويناتها:
- تحديث تكوين النموذج الافتراضي لـ PP-OCRv5، وتغيير كل من الكشف والتعرف من
mobileإلىserver. لتحسين الأداء الافتراضي في معظم السيناريوهات، تم تغيير المعلمةlimit_side_lenفي التكوين من 736 إلى 64. - إضافة نموذج جديد لتصنيف اتجاه أسطر النص
PP-LCNet_x1_0_textline_oriبدقة 99.42%. تم تحديث مصنف اتجاه أسطر النص الافتراضي لخطوط أنابيب OCR و PP-StructureV3 و PP-ChatOCRv4 إلى هذا النموذج. - تحسين نموذج تصنيف اتجاه أسطر النص
PP-LCNet_x0_25_textline_ori، مما أدى إلى تحسين الدقة بمقدار 3.3 نقطة مئوية لتصل إلى الدقة الحالية البالغة 98.85%.
- تحديث تكوين النموذج الافتراضي لـ PP-OCRv5، وتغيير كل من الكشف والتعرف من
- تحسينات وإصلاحات لبعض المشكلات في الإصدار 3.0.0، التفاصيل
🔥🔥2025.05.20: الإصدار الرسمي لـ PaddleOCR v3.0، بما في ذلك:
PP-OCRv5: نموذج التعرف على النصوص عالي الدقة لجميع السيناريوهات – نص فوري من الصور/PDF.
- 🌐 دعم نموذج واحد **لخمسة** أنواع من النصوص - معالجة سلسة **للصينية المبسطة والصينية التقليدية وبينين الصينية المبسطة والإنجليزية** و**اليابانية** ضمن نموذج واحد.
- ✍️ تحسين **التعرف على الكتابة اليدوية**: أداء أفضل بشكل ملحوظ في النصوص المتصلة المعقدة والكتابة اليدوية غير القياسية.
- 🎯 **زيادة في الدقة بمقدار 13 نقطة** عن PP-OCRv4، مما يحقق أداءً على أحدث طراز في مجموعة متنوعة من سيناريوهات العالم الحقيقي.
PP-StructureV3: تحليل المستندات للأغراض العامة – أطلق العنان لتحليل الصور/PDFs بأحدث التقنيات لسيناريوهات العالم الحقيقي!
- 🧮 **تحليل PDF عالي الدقة متعدد السيناريوهات**، يتصدر كلاً من الحلول المفتوحة والمغلقة المصدر على معيار OmniDocBench.
- 🧠 تشمل القدرات المتخصصة **التعرف على الأختام**، **تحويل المخططات إلى جداول**، **التعرف على الجداول التي تحتوي على صيغ/صور متداخلة**، **تحليل المستندات ذات النصوص العمودية**، و**تحليل هياكل الجداول المعقدة**.
PP-ChatOCRv4: فهم المستندات الذكي – استخرج المعلومات الأساسية، وليس فقط النصوص من الصور/PDFs.
- 🔥 **زيادة في الدقة بمقدار 15 نقطة** في استخراج المعلومات الأساسية من ملفات PDF/PNG/JPG مقارنة بالجيل السابق.
- 💻 دعم أصلي لـ ERNIE 4.5 Turbo، مع التوافق مع عمليات نشر النماذج الكبيرة عبر PaddleNLP و Ollama و vLLM والمزيد.
- 🤝 دمج PP-DocBee2، مما يتيح استخراج وفهم النصوص المطبوعة والمخطوطة والأختام والجداول والمخططات والعناصر الشائعة الأخرى في المستندات المعقدة.
⚡ التشغيل السريع
1. تشغيل العرض التوضيحي عبر الإنترنت
2. التثبيت
قم بتثبيت PaddlePaddle بالرجوع إلى دليل التثبيت، وبعد ذلك، قم بتثبيت مجموعة أدوات PaddleOCR.
# Install paddleocr
pip install paddleocr
3. تشغيل الاستدلال عبر واجهة سطر الأوامر (CLI)
# Run PP-OCRv5 inference
paddleocr ocr -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --use_doc_orientation_classify False --use_doc_unwarping False --use_textline_orientation False
# Run PP-StructureV3 inference
paddleocr pp_structurev3 -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_structure_v3_demo.png --use_doc_orientation_classify False --use_doc_unwarping False
# Get the Qianfan API Key at first, and then run PP-ChatOCRv4 inference
paddleocr pp_chatocrv4_doc -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_certificate-1.png -k 驾驶室准乘人数 --qianfan_api_key your_api_key --use_doc_orientation_classify False --use_doc_unwarping False
# Get more information about "paddleocr ocr"
paddleocr ocr --help
4. تشغيل الاستدلال عبر واجهة برمجة التطبيقات (API)
4.1 مثال PP-OCRv5
from paddleocr import PaddleOCR
ocr = PaddleOCR(
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False)
result = ocr.predict(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png")
for res in result:
res.print()
res.save_to_img("output")
res.save_to_json("output")
4.2 مثال PP-StructureV3
from pathlib import Path
from paddleocr import PPStructureV3
pipeline = PPStructureV3(
use_doc_orientation_classify=False,
use_doc_unwarping=False
)
# للصور
output = pipeline.predict(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_structure_v3_demo.png",
)
# عرض النتائج وحفظها بصيغة JSON
for res in output:
res.print()
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")
4.3 مثال PP-ChatOCRv4
from paddleocr import PPChatOCRv4Doc
chat_bot_config = {
"module_name": "chat_bot",
"model_name": "ernie-3.5-8k",
"base_url": "https://qianfan.baidubce.com/v2",
"api_type": "openai",
"api_key": "api_key", # your api_key
}
retriever_config = {
"module_name": "retriever",
"model_name": "embedding-v1",
"base_url": "https://qianfan.baidubce.com/v2",
"api_type": "qianfan",
"api_key": "api_key", # your api_key
}
pipeline = PPChatOCRv4Doc(
use_doc_orientation_classify=False,
use_doc_unwarping=False
)
visual_predict_res = pipeline.visual_predict(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_certificate-1.png",
use_common_ocr=True,
use_seal_recognition=True,
use_table_recognition=True,
)
mllm_predict_info = None
use_mllm = False
# إذا تم استخدام نموذج كبير متعدد الوسائط، فيجب بدء خدمة mllm المحلية. يمكنك الرجوع إلى الوثائق: https://github.com/PaddlePaddle/PaddleX/blob/release/3.0/docs/pipeline_usage/tutorials/vlm_pipelines/doc_understanding.en.md لتنفيذ النشر وتحديث تكوين mllm_chat_bot_config.
if use_mllm:
mllm_chat_bot_config = {
"module_name": "chat_bot",
"model_name": "PP-DocBee",
"base_url": "http://127.0.0.1:8080/", # your local mllm service url
"api_type": "openai",
"api_key": "api_key", # your api_key
}
mllm_predict_res = pipeline.mllm_pred(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_certificate-1.png",
key_list=["驾驶室准乘人数"],
mllm_chat_bot_config=mllm_chat_bot_config,
)
mllm_predict_info = mllm_predict_res["mllm_res"]
visual_info_list = []
for res in visual_predict_res:
visual_info_list.append(res["visual_info"])
layout_parsing_result = res["layout_parsing_result"]
vector_info = pipeline.build_vector(
visual_info_list, flag_save_bytes_vector=True, retriever_config=retriever_config
)
chat_result = pipeline.chat(
key_list=["驾驶室准乘人数"],
visual_info=visual_info_list,
vector_info=vector_info,
mllm_predict_info=mllm_predict_info,
chat_bot_config=chat_bot_config,
retriever_config=retriever_config,
)
print(chat_result)
5. مسرّعات الذكاء الاصطناعي الصينية غير المتجانسة
⛰️ دروس متقدمة
🔄 نظرة سريعة على نتائج التنفيذ


👩👩👧👦 المجتمع
| حساب PaddlePaddle الرسمي على WeChat | انضم إلى مجموعة النقاش التقني |
|---|---|
 |
 |
😃 مشاريع رائعة تستخدم PaddleOCR
لم يكن PaddleOCR ليصل إلى ما هو عليه اليوم بدون مجتمعه المذهل! 💗 شكرًا جزيلاً لجميع شركائنا القدامى، والمتعاونين الجدد، وكل من صب شغفه في PaddleOCR - سواء ذكرنا اسمك أم لا. دعمكم يشعل نارنا!
| اسم المشروع | الوصف |
|---|---|
RAGFlow  |
محرك RAG يعتمد على فهم عميق للوثائق. |
MinerU  |
أداة تحويل المستندات متعددة الأنواع إلى Markdown |
Umi-OCR  |
برنامج OCR مجاني ومفتوح المصدر للعمل دفعة واحدة دون اتصال بالإنترنت. |
OmniParser |
أداة OmniParser: أداة تحليل الشاشة لوكيل واجهة المستخدم الرسومية المستند إلى الرؤية البحتة. |
QAnything |
نظام سؤال وجواب يعتمد على أي شيء. |
PDF-Extract-Kit  |
مجموعة أدوات قوية مفتوحة المصدر مصممة لاستخراج محتوى عالي الجودة بكفاءة من مستندات PDF المعقدة والمتنوعة. |
| Dango-Translator |
يتعرف على النص على الشاشة، ويترجمه ويعرض نتائج الترجمة في الوقت الفعلي. |
| تعرف على المزيد من المشاريع | مشاريع أخرى تعتمد على PaddleOCR |
👩👩👧👦 المساهمون
🌟 نجمة
📄 الترخيص
هذا المشروع مرخص بموجب ترخيص Apache 2.0.
🎓 الاستشهاد الأكاديمي
@misc{paddleocr2020,
title={PaddleOCR, Awesome multilingual OCR toolkits based on PaddlePaddle.},
author={PaddlePaddle Authors},
howpublished = {\url{https://github.com/PaddlePaddle/PaddleOCR}},
year={2020}
}