20 KiB



🚀 Introducción
Desde su lanzamiento inicial, PaddleOCR ha sido ampliamente aclamado en las comunidades académica, industrial y de investigación, gracias a sus algoritmos de vanguardia y su rendimiento probado en aplicaciones del mundo real. Ya está impulsando proyectos populares de código abierto como Umi-OCR, OmniParser, MinerU y RAGFlow, convirtiéndose en el conjunto de herramientas de OCR de referencia para desarrolladores de todo el mundo.
El 20 de mayo de 2025, el equipo de PaddlePaddle presentó PaddleOCR 3.0, totalmente compatible con la versión oficial del framework PaddlePaddle 3.0. Esta actualización aumenta aún más la precisión en el reconocimiento de texto, añade soporte para el reconocimiento de múltiples tipos de texto y el reconocimiento de escritura a mano, y satisface la creciente demanda de las aplicaciones de grandes modelos para el análisis (parsing) de alta precisión de documentos complejos. En combinación con ERNIE 4.5 Turbo, mejora significativamente la precisión en la extracción de información clave. Para la documentación de uso completa, consulte la Documentación de PaddleOCR 3.0.
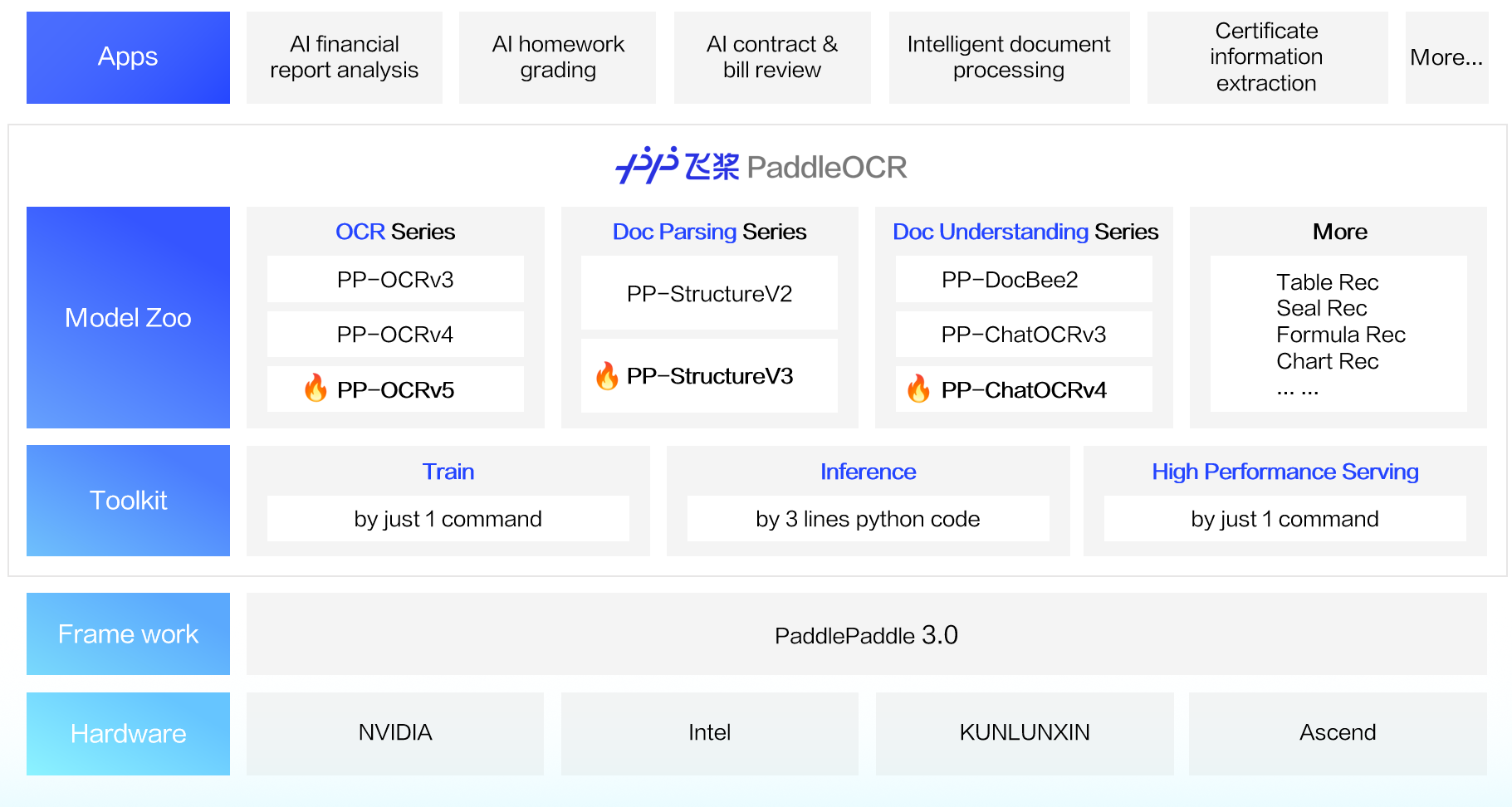
Tres nuevas características principales en PaddleOCR 3.0:
-
Modelo de Reconocimiento de Texto en Escenarios Universales PP-OCRv5: Un único modelo que maneja cinco tipos de texto diferentes además de escritura a mano compleja. La precisión general de reconocimiento ha aumentado en 13 puntos porcentuales con respecto a la generación anterior. Demo en línea
-
Solución de Análisis General de Documentos PP-StructureV3: Ofrece un análisis de alta precisión de PDF con múltiples diseños y escenas, superando a muchas soluciones de código abierto y cerrado en benchmarks públicos. Demo en línea
-
Solución de Comprensión Inteligente de Documentos PP-ChatOCRv4: Impulsado nativamente por el gran modelo ERNIE 4.5 Turbo, logrando una precisión 15 puntos porcentuales mayor que su predecesor. Demo en línea
Además de proporcionar una excelente biblioteca de modelos, PaddleOCR 3.0 también ofrece herramientas fáciles de usar que cubren el entrenamiento de modelos, la inferencia y el despliegue de servicios, para que los desarrolladores puedan llevar rápidamente las aplicaciones de IA a producción.
📣 Últimas actualizaciones
🔥🔥2025.06.26: Lanzamiento de PaddleOCR 3.0.3, incluye:
- Corrección de error: Se resolvió el problema donde el parámetro
enable_mkldnnno era efectivo, restaurando el comportamiento predeterminado de usar MKL-DNN para la inferencia en CPU.
🔥🔥2025.06.19: Lanzamiento de PaddleOCR 3.0.2, incluye:
-
Nuevas características:
- La fuente de descarga predeterminada se ha cambiado de
BOSaHuggingFace. Los usuarios también pueden cambiar la variable de entornoPADDLE_PDX_MODEL_SOURCEaBOSpara volver a establecer la fuente de descarga del modelo en Baidu Object Storage (BOS). - Se agregaron ejemplos de invocación de servicios para seis idiomas (C++, Java, Go, C#, Node.js y PHP) para pipelines como PP-OCRv5, PP-StructureV3 y PP-ChatOCRv4.
- Se mejoró el algoritmo de ordenación de particiones de diseño en el pipeline PP-StructureV3, mejorando la lógica de ordenación para diseños verticales complejos para ofrecer mejores resultados.
- Lógica de selección de modelo mejorada: cuando se especifica un idioma pero no una versión del modelo, el sistema seleccionará automáticamente la última versión del modelo que admita ese idioma.
- Se estableció un límite superior predeterminado para el tamaño de la caché de MKL-DNN para evitar un crecimiento ilimitado, al tiempo que se permite a los usuarios configurar la capacidad de la caché.
- Se actualizaron las configuraciones predeterminadas para la inferencia de alto rendimiento para admitir la aceleración de Paddle MKL-DNN y se optimizó la lógica para la selección automática de configuración para elecciones más inteligentes.
- Se ajustó la lógica para obtener el dispositivo predeterminado para considerar el soporte real de los dispositivos de computación por parte del framework Paddle instalado, lo que hace que el comportamiento del programa sea más intuitivo.
- Añadido ejemplo de Android para PP-OCRv5. Detalles.
- La fuente de descarga predeterminada se ha cambiado de
-
Corrección de errores:
- Se solucionó un problema con algunos parámetros de CLI en PP-StructureV3 que no tenían efecto.
- Se resolvió un problema por el cual
export_paddlex_config_to_yamlno funcionaba correctamente en ciertos casos. - Se corrigió la discrepancia entre el comportamiento real de
save_pathy la descripción de su documentación. - Se corrigieron posibles errores de subprocesos múltiples al usar MKL-DNN en la implementación de servicios básicos.
- Se corrigieron errores en el orden de los canales en el preprocesamiento de imágenes para el modelo Latex-OCR.
- Se corrigieron errores en el orden de los canales al guardar imágenes visualizadas dentro del módulo de reconocimiento de texto.
- Se resolvieron errores de orden de canales en los resultados de tablas visualizadas dentro del pipeline de PP-StructureV3.
- Se solucionó un problema de desbordamiento en el cálculo de
overlap_ratioen circunstancias extremadamente especiales en el pipeline PP-StructureV3.
-
Mejoras en la documentación:
- Se actualizó la descripción del parámetro
enable_mkldnnen la documentación para reflejar con precisión el comportamiento real del programa. - Se corrigieron errores en la documentación con respecto a los parámetros
langyocr_version. - Se agregaron instrucciones para exportar archivos de configuración de la línea de producción a través de CLI.
- Se corrigieron las columnas que faltaban en la tabla de datos de rendimiento para PP-OCRv5.
- Se refinaron las métricas de referencia para PP-StructureV3 en diferentes configuraciones.
- Se actualizó la descripción del parámetro
-
Otros:
- Se flexibilizaron las restricciones de versión en dependencias como numpy y pandas, restaurando el soporte para Python 3.12.
Historial de actualizaciones
🔥🔥 2025.06.05: Lanzamiento de PaddleOCR 3.0.1, incluye:
-
Optimización de ciertos modelos y configuraciones de modelos:
- Actualizada la configuración de modelo por defecto para PP-OCRv5, cambiando tanto la detección como el reconocimiento de modelos
mobileaserver. Para mejorar el rendimiento por defecto en la mayoría de los escenarios, el parámetrolimit_side_lenen la configuración ha sido cambiado de 736 a 64. - Añadido un nuevo modelo de clasificación de orientación de línea de texto
PP-LCNet_x1_0_textline_oricon una precisión del 99.42%. El clasificador de orientación de línea de texto por defecto para los pipelines de OCR, PP-StructureV3 y PP-ChatOCRv4 ha sido actualizado a este modelo. - Optimizado el modelo de clasificación de orientación de línea de texto
PP-LCNet_x0_25_textline_ori, mejorando la precisión en 3.3 puntos porcentuales hasta una precisión actual del 98.85%.
- Actualizada la configuración de modelo por defecto para PP-OCRv5, cambiando tanto la detección como el reconocimiento de modelos
-
Optimizaciones y correcciones de algunos problemas en la versión 3.0.0, detalles
🔥🔥2025.05.20: Lanzamiento oficial de PaddleOCR v3.0, incluyendo:
-
PP-OCRv5: Modelo de Reconocimiento de Texto de Alta Precisión para Todos los Escenarios - Texto Instantáneo desde Imágenes/PDFs.
- 🌐 Soporte en un único modelo para cinco tipos de texto - Procese sin problemas Chino Simplificado, Chino Tradicional, Pinyin de Chino Simplificado, Inglés y Japonés dentro de un solo modelo.
- ✍️ Reconocimiento de escritura a mano mejorado: Significativamente mejor en escritura cursiva compleja y caligrafía no estándar.
- 🎯 Ganancia de precisión de 13 puntos sobre PP-OCRv4, alcanzando un rendimiento de vanguardia (state-of-the-art) en una variedad de escenarios del mundo real.
-
PP-StructureV3: Solución de Análisis de Documentos de Propósito General – ¡Libere el poder del análisis SOTA de Imágenes/PDFs para escenarios del mundo real!
- 🧮 Análisis de PDF multiescena de alta precisión, liderando tanto a las soluciones de código abierto como a las de código cerrado en el benchmark OmniDocBench.
- 🧠 Capacidades especializadas que incluyen reconocimiento de sellos, conversión de gráficos a tablas, reconocimiento de tablas con fórmulas/imágenes anidadas, análisis de documentos de texto vertical y análisis de estructuras de tablas complejas.
-
PP-ChatOCRv4: Solución Inteligente de Comprensión de Documentos – Extraiga Información Clave, no solo texto de Imágenes/PDFs.
- 🔥 Ganancia de precisión de 15 puntos en la extracción de información clave en archivos PDF/PNG/JPG con respecto a la generación anterior.
- 💻 Soporte nativo para ERNIE 4.5 Turbo, con compatibilidad para despliegues de modelos grandes a través de PaddleNLP, Ollama, vLLM y más.
- 🤝 Integrado con PP-DocBee2, permitiendo la extracción y comprensión de texto impreso, escritura a mano, sellos, tablas, gráficos y otros elementos comunes en documentos complejos.
⚡ Inicio rápido
1. Ejecutar demo en línea
2. Instalación
Instale PaddlePaddle consultando la Guía de Instalación, y después, instale el toolkit de PaddleOCR.
# Instalar paddleocr
pip install paddleocr
3. Ejecutar inferencia por CLI
# Ejecutar inferencia de PP-OCRv5
paddleocr ocr -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --use_doc_orientation_classify False --use_doc_unwarping False --use_textline_orientation False
# Ejecutar inferencia de PP-StructureV3
paddleocr pp_structurev3 -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_structure_v3_demo.png --use_doc_orientation_classify False --use_doc_unwarping False
# Obtenga primero la API Key de Qianfan y luego ejecute la inferencia de PP-ChatOCRv4
paddleocr pp_chatocrv4_doc -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_certificate-1.png -k 驾驶室准乘人数 --qianfan_api_key your_api_key --use_doc_orientation_classify False --use_doc_unwarping False
# Obtener más información sobre "paddleocr ocr"
paddleocr ocr --help
4. Ejecutar inferencia por API
4.1 Ejemplo de PP-OCRv5
from paddleocr import PaddleOCR
# Inicializar la instancia de PaddleOCR
ocr = PaddleOCR(
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False)
# Ejecutar inferencia de OCR en una imagen de ejemplo
result = ocr.predict(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png")
# Visualizar los resultados y guardar los resultados en JSON
for res in result:
res.print()
res.save_to_img("output")
res.save_to_json("output")
4.2 Ejemplo de PP-StructureV3
from pathlib import Path
from paddleocr import PPStructureV3
pipeline = PPStructureV3(
use_doc_orientation_classify=False,
use_doc_unwarping=False
)
# Para Imagen
output = pipeline.predict(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_structure_v3_demo.png",
)
# Visualizar los resultados y guardar los resultados en JSON
for res in output:
res.print()
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")
4.3 Ejemplo de PP-ChatOCRv4
from paddleocr import PPChatOCRv4Doc
chat_bot_config = {
"module_name": "chat_bot",
"model_name": "ernie-3.5-8k",
"base_url": "https://qianfan.baidubce.com/v2",
"api_type": "openai",
"api_key": "api_key", # su api_key
}
retriever_config = {
"module_name": "retriever",
"model_name": "embedding-v1",
"base_url": "https://qianfan.baidubce.com/v2",
"api_type": "qianfan",
"api_key": "api_key", # su api_key
}
pipeline = PPChatOCRv4Doc(
use_doc_orientation_classify=False,
use_doc_unwarping=False
)
visual_predict_res = pipeline.visual_predict(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_certificate-1.png",
use_common_ocr=True,
use_seal_recognition=True,
use_table_recognition=True,
)
mllm_predict_info = None
use_mllm = False
# Si se utiliza un modelo grande multimodal, es necesario iniciar el servicio mllm local. Puede consultar la documentación: https://github.com/PaddlePaddle/PaddleX/blob/release/3.0/docs/pipeline_usage/tutorials/vlm_pipelines/doc_understanding.en.md para realizar el despliegue y actualizar la configuración de mllm_chat_bot_config.
if use_mllm:
mllm_chat_bot_config = {
"module_name": "chat_bot",
"model_name": "PP-DocBee",
"base_url": "http://127.0.0.1:8080/", # la URL de su servicio mllm local
"api_type": "openai",
"api_key": "api_key", # su api_key
}
mllm_predict_res = pipeline.mllm_pred(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_certificate-1.png",
key_list=["驾驶室准乘人数"],
mllm_chat_bot_config=mllm_chat_bot_config,
)
mllm_predict_info = mllm_predict_res["mllm_res"]
visual_info_list = []
for res in visual_predict_res:
visual_info_list.append(res["visual_info"])
layout_parsing_result = res["layout_parsing_result"]
vector_info = pipeline.build_vector(
visual_info_list, flag_save_bytes_vector=True, retriever_config=retriever_config
)
chat_result = pipeline.chat(
key_list=["驾驶室准乘人数"],
visual_info=visual_info_list,
vector_info=vector_info,
mllm_predict_info=mllm_predict_info,
chat_bot_config=chat_bot_config,
retriever_config=retriever_config,
)
print(chat_result)
⛰️ Tutoriales avanzados
🔄 Vista rápida de los resultados de ejecución


👩👩👧👦 Comunidad
| Cuenta oficial de PaddlePaddle en WeChat | Únase al grupo de discusión técnica |
|---|---|
 |
 |
😃 Proyectos increíbles que aprovechan PaddleOCR
¡PaddleOCR no estaría donde está hoy sin su increíble comunidad! 💗 Un enorme agradecimiento a todos nuestros socios de siempre, nuevos colaboradores y a todos los que han volcado su pasión en PaddleOCR, ya sea que los hayamos nombrado o no. ¡Su apoyo alimenta nuestro fuego!
| Nombre del Proyecto | Descripción |
|---|---|
RAGFlow  |
Motor de RAG basado en la comprensión profunda de documentos. |
MinerU  |
Herramienta de conversión de documentos de múltiples tipos a Markdown. |
Umi-OCR  |
Software de OCR por lotes, sin conexión, gratuito y de código abierto. |
OmniParser |
OmniParser: Herramienta de análisis de pantalla para agentes GUI basados puramente en visión. |
QAnything |
Preguntas y respuestas basadas en cualquier cosa. |
PDF-Extract-Kit  |
Un potente toolkit de código abierto diseñado para extraer eficientemente contenido de alta calidad de documentos PDF complejos y diversos. |
| Dango-Translator |
Reconoce texto en la pantalla, lo traduce y muestra los resultados de la traducción en tiempo real. |
| Conozca más proyectos | Más proyectos basados en PaddleOCR |
👩👩👧👦 Contribuidores
🌟 Star
📄 Licencia
Este proyecto se publica bajo la licencia Apache 2.0.
🎓 Citación
@misc{paddleocr2020,
title={PaddleOCR, Awesome multilingual OCR toolkits based on PaddlePaddle.},
author={PaddlePaddle Authors},
howpublished = {\url{https://github.com/PaddlePaddle/PaddleOCR}},
year={2020}
}