21 KiB



🚀 Introduction
Depuis sa sortie initiale, PaddleOCR a été largement acclamé par les milieux universitaires, industriels et de la recherche, grâce à ses algorithmes de pointe et à ses performances éprouvées dans des applications réelles. Il alimente déjà des projets open-source populaires tels que Umi-OCR, OmniParser, MinerU et RAGFlow, ce qui en fait la boîte à outils OCR de référence pour les développeurs du monde entier.
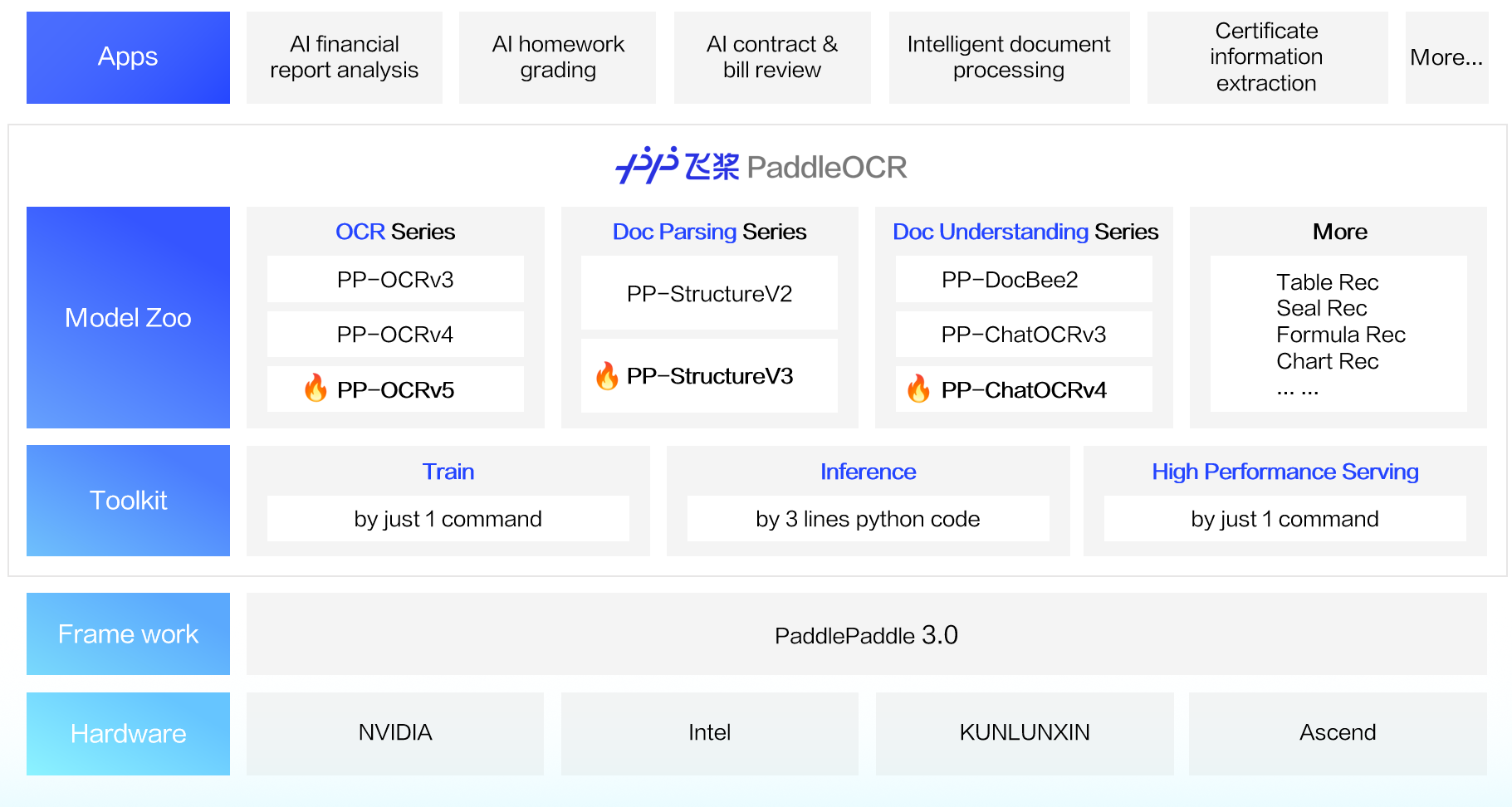
Le 20 mai 2025, l'équipe de PaddlePaddle a dévoilé PaddleOCR 3.0, entièrement compatible avec la version officielle du framework PaddlePaddle 3.0. Cette mise à jour améliore encore la précision de la reconnaissance de texte, ajoute la prise en charge de la reconnaissance de multiples types de texte et de la reconnaissance de l'écriture manuscrite, et répond à la demande croissante des applications de grands modèles pour l'analyse de haute précision de documents complexes. Combiné avec ERNIE 4.5 Turbo, il améliore considérablement la précision de l'extraction d'informations clés. Pour la documentation d'utilisation complète, veuillez vous référer à la Documentation de PaddleOCR 3.0.
Trois nouvelles fonctionnalités majeures dans PaddleOCR 3.0 :
-
Modèle de reconnaissance de texte pour toutes scènes PP-OCRv5 : Un modèle unique qui gère cinq types de texte différents ainsi que l'écriture manuscrite complexe. La précision globale de la reconnaissance a augmenté de 13 points de pourcentage par rapport à la génération précédente. Démo en ligne
-
Solution d'analyse de documents générique PP-StructureV3 : Fournit une analyse de haute précision des PDF multi-mises en page et multi-scènes, surpassant de nombreuses solutions open-source et propriétaires sur les benchmarks publics. Démo en ligne
-
Solution de compréhension de documents intelligente PP-ChatOCRv4 : Nativement propulsé par le grand modèle ERNIE 4.5 Turbo, atteignant une précision supérieure de 15 points de pourcentage à celle de son prédécesseur. Démo en ligne
En plus de fournir une bibliothèque de modèles exceptionnelle, PaddleOCR 3.0 propose également des outils conviviaux couvrant l'entraînement de modèles, l'inférence et le déploiement de services, afin que les développeurs puissent rapidement mettre en production des applications d'IA.
📣 Mises à jour récentes
26/06/2025 : Publication de PaddleOCR 3.0.3, incluant :
- Correction de bug : Résolution du problème où le paramètre
enable_mkldnnne fonctionnait pas, rétablissant le comportement par défaut d'utilisation de MKL-DNN pour l'inférence CPU.
🔥🔥19/06/2025 : Publication de PaddleOCR 3.0.2, incluant :
-
Nouvelles fonctionnalités :
- La source de téléchargement par défaut a été changée de
BOSàHuggingFace. Les utilisateurs peuvent également changer la variable d'environnementPADDLE_PDX_MODEL_SOURCEenBOSpour rétablir la source de téléchargement sur Baidu Object Storage (BOS). - Ajout d'exemples d'appel de service pour six langues — C++, Java, Go, C#, Node.js et PHP — pour les pipelines tels que PP-OCRv5, PP-StructureV3 et PP-ChatOCRv4.
- Amélioration de l'algorithme de tri de partition de mise en page dans le pipeline PP-StructureV3, améliorant la logique de tri pour les mises en page verticales complexes afin de fournir de meilleurs résultats.
- Logique de sélection de modèle améliorée : lorsqu'une langue est spécifiée mais pas une version de modèle, le système sélectionnera automatiquement la dernière version du modèle prenant en charge cette langue.
- Définition d'une limite supérieure par défaut pour la taille du cache MKL-DNN afin d'éviter une croissance illimitée, tout en permettant aux utilisateurs de configurer la capacité du cache.
- Mise à jour des configurations par défaut pour l'inférence haute performance afin de prendre en charge l'accélération Paddle MKL-DNN et optimisation de la logique de sélection automatique de la configuration pour des choix plus intelligents.
- Ajustement de la logique d'obtention du périphérique par défaut pour tenir compte du support réel des dispositifs de calcul par le framework Paddle installé, rendant le comportement du programme plus intuitif.
- Ajout d'un exemple Android pour PP-OCRv5. Détails.
- La source de téléchargement par défaut a été changée de
-
Corrections de bugs :
- Correction d'un problème où certains paramètres CLI dans PP-StructureV3 ne prenaient pas effet.
- Résolution d'un problème où
export_paddlex_config_to_yamlne fonctionnait pas correctement dans certains cas. - Correction de l'écart entre le comportement réel de
save_pathet sa description dans la documentation. - Correction d'erreurs potentielles de multithreading lors de l'utilisation de MKL-DNN dans le déploiement de services de base.
- Correction des erreurs d'ordre des canaux dans le prétraitement des images pour le modèle Latex-OCR.
- Correction des erreurs d'ordre des canaux lors de la sauvegarde des images visualisées dans le module de reconnaissance de texte.
- Résolution des erreurs d'ordre des canaux dans les résultats de tableaux visualisés dans le pipeline PP-StructureV3.
- Correction d'un problème de débordement dans le calcul de
overlap_ratiodans des circonstances très spéciales dans le pipeline PP-StructureV3.
-
Améliorations de la documentation :
- Mise à jour de la description du paramètre
enable_mkldnndans la documentation pour refléter précisément le comportement réel du programme. - Correction d'erreurs dans la documentation concernant les paramètres
langetocr_version. - Ajout d'instructions pour l'exportation des fichiers de configuration de la ligne de production via CLI.
- Correction des colonnes manquantes dans le tableau de données de performance pour PP-OCRv5.
- Affinement des métriques de benchmark pour PP-StructureV3 pour différentes configurations.
- Mise à jour de la description du paramètre
-
Autres :
- Assouplissement des restrictions de version sur les dépendances comme numpy et pandas, restaurant la prise en charge de Python 3.12.
Historique des mises à jour
🔥🔥 05/06/2025 : Publication de PaddleOCR 3.0.1, incluant :
-
Optimisation de certains modèles et de leurs configurations :
- Mise à jour de la configuration par défaut du modèle pour PP-OCRv5, en passant les modèles de détection et de reconnaissance de
mobileàserver. Pour améliorer les performances par défaut dans la plupart des scénarios, le paramètrelimit_side_lendans la configuration a été changé de 736 à 64. - Ajout d'un nouveau modèle de classification de l'orientation des lignes de texte
PP-LCNet_x1_0_textline_oriavec une précision de 99.42%. Le classifieur d'orientation de ligne de texte par défaut pour les pipelines OCR, PP-StructureV3 et PP-ChatOCRv4 a été mis à jour vers ce modèle. - Optimisation du modèle de classification de l'orientation des lignes de texte
PP-LCNet_x0_25_textline_ori, améliorant la précision de 3,3 points de pourcentage pour atteindre une précision actuelle de 98,85%.
- Mise à jour de la configuration par défaut du modèle pour PP-OCRv5, en passant les modèles de détection et de reconnaissance de
-
Optimisations et corrections de certains problèmes de la version 3.0.0, détails
🔥🔥20/05/2025 : Lancement officiel de PaddleOCR v3.0, incluant :
-
PP-OCRv5 : Modèle de reconnaissance de texte de haute précision pour tous les scénarios - Texte instantané à partir d'images/PDF.
- 🌐 Prise en charge par un seul modèle de cinq types de texte - Traitez de manière transparente le chinois simplifié, le chinois traditionnel, le pinyin chinois simplifié, l'anglais et le japonais au sein d'un seul modèle.
- ✍️ Reconnaissance de l'écriture manuscrite améliorée : Nettement plus performant sur les écritures cursives complexes et non standard.
- 🎯 Gain de précision de 13 points par rapport à PP-OCRv4, atteignant des performances de pointe dans une variété de scénarios réels.
-
PP-StructureV3 : Analyse de documents à usage général – Libérez une analyse d'images/PDF de pointe pour des scénarios du monde réel !
- 🧮 Analyse de PDF multi-scènes de haute précision, devançant les solutions open-source et propriétaires sur le benchmark OmniDocBench.
- 🧠 Les capacités spécialisées incluent la reconnaissance de sceaux, la conversion de graphiques en tableaux, la reconnaissance de tableaux avec formules/images imbriquées, l'analyse de documents à texte vertical et l'analyse de structures de tableaux complexes.
-
PP-ChatOCRv4 : Compréhension intelligente de documents – Extrayez des informations clés, pas seulement du texte, à partir d'images/PDF.
- 🔥 Gain de précision de 15 points dans l'extraction d'informations clés sur les fichiers PDF/PNG/JPG par rapport à la génération précédente.
- 💻 Prise en charge native de ERNIE 4.5 Turbo, avec une compatibilité pour les déploiements de grands modèles via PaddleNLP, Ollama, vLLM, et plus encore.
- 🤝 Intégration de PP-DocBee2, permettant l'extraction et la compréhension de texte imprimé, d'écriture manuscrite, de sceaux, de tableaux, de graphiques et d'autres éléments courants dans les documents complexes.
⚡ Démarrage Rapide
1. Lancer la démo en ligne
2. Installation
Installez PaddlePaddle en vous référant au Guide d'installation, puis installez la boîte à outils PaddleOCR.
# Installer paddleocr
pip install paddleocr
3. Exécuter l'inférence par CLI
# Exécuter l'inférence PP-OCRv5
paddleocr ocr -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --use_doc_orientation_classify False --use_doc_unwarping False --use_textline_orientation False
# Exécuter l'inférence PP-StructureV3
paddleocr pp_structurev3 -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_structure_v3_demo.png --use_doc_orientation_classify False --use_doc_unwarping False
# Obtenez d'abord la clé API Qianfan, puis exécutez l'inférence PP-ChatOCRv4
paddleocr pp_chatocrv4_doc -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_certificate-1.png -k 驾驶室准乘人数 --qianfan_api_key your_api_key --use_doc_orientation_classify False --use_doc_unwarping False
# Obtenir plus d'informations sur "paddleocr ocr"
paddleocr ocr --help
4. Exécuter l'inférence par API
4.1 Exemple PP-OCRv5
# Initialiser l'instance de PaddleOCR
from paddleocr import PaddleOCR
ocr = PaddleOCR(
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False)
# Exécuter l'inférence OCR sur un exemple d'image
result = ocr.predict(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png")
# Visualiser les résultats et sauvegarder les résultats JSON
for res in result:
res.print()
res.save_to_img("output")
res.save_to_json("output")
4.2 Exemple PP-StructureV3
from pathlib import Path
from paddleocr import PPStructureV3
pipeline = PPStructureV3(
use_doc_orientation_classify=False,
use_doc_unwarping=False
)
# Pour une image
output = pipeline.predict(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_structure_v3_demo.png",
)
# Visualiser les résultats et sauvegarder les résultats JSON
for res in output:
res.print()
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")
4.3 Exemple PP-ChatOCRv4
from paddleocr import PPChatOCRv4Doc
chat_bot_config = {
"module_name": "chat_bot",
"model_name": "ernie-3.5-8k",
"base_url": "https://qianfan.baidubce.com/v2",
"api_type": "openai",
"api_key": "api_key", # votre api_key
}
retriever_config = {
"module_name": "retriever",
"model_name": "embedding-v1",
"base_url": "https://qianfan.baidubce.com/v2",
"api_type": "qianfan",
"api_key": "api_key", # votre api_key
}
pipeline = PPChatOCRv4Doc(
use_doc_orientation_classify=False,
use_doc_unwarping=False
)
visual_predict_res = pipeline.visual_predict(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_certificate-1.png",
use_common_ocr=True,
use_seal_recognition=True,
use_table_recognition=True,
)
mllm_predict_info = None
use_mllm = False
# Si un grand modèle multimodal est utilisé, le service mllm local doit être démarré. Vous pouvez vous référer à la documentation : https://github.com/PaddlePaddle/PaddleX/blob/release/3.0/docs/pipeline_usage/tutorials/vlm_pipelines/doc_understanding.en.md pour effectuer le déploiement et mettre à jour la configuration mllm_chat_bot_config.
if use_mllm:
mllm_chat_bot_config = {
"module_name": "chat_bot",
"model_name": "PP-DocBee",
"base_url": "http://127.0.0.1:8080/", # url de votre service mllm local
"api_type": "openai",
"api_key": "api_key", # votre api_key
}
mllm_predict_res = pipeline.mllm_pred(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_certificate-1.png",
key_list=["驾驶室准乘人数"],
mllm_chat_bot_config=mllm_chat_bot_config,
)
mllm_predict_info = mllm_predict_res["mllm_res"]
visual_info_list = []
for res in visual_predict_res:
visual_info_list.append(res["visual_info"])
layout_parsing_result = res["layout_parsing_result"]
vector_info = pipeline.build_vector(
visual_info_list, flag_save_bytes_vector=True, retriever_config=retriever_config
)
chat_result = pipeline.chat(
key_list=["驾驶室准乘人数"],
visual_info=visual_info_list,
vector_info=vector_info,
mllm_predict_info=mllm_predict_info,
chat_bot_config=chat_bot_config,
retriever_config=retriever_config,
)
print(chat_result)
⛰️ Tutoriels avancés
🔄 Aperçu rapide des résultats d'exécution


👩👩👧👦 Communauté
| Compte officiel WeChat de PaddlePaddle | Rejoignez le groupe de discussion technique |
|---|---|
 |
 |
😃 Projets formidables utilisant PaddleOCR
PaddleOCR ne serait pas là où il est aujourd'hui sans son incroyable communauté ! 💗 Un immense merci à tous nos partenaires de longue date, nos nouveaux collaborateurs, et tous ceux qui ont mis leur passion dans PaddleOCR — que nous vous ayons nommés ou non. Votre soutien nous anime !
| Nom du projet | Description |
|---|---|
RAGFlow  |
Moteur RAG basé sur la compréhension profonde des documents. |
MinerU  |
Outil de conversion de documents multi-types en Markdown |
Umi-OCR  |
Logiciel d'OCR hors ligne, gratuit, open-source et par lots. |
OmniParser |
Outil d'analyse d'écran pour agent GUI basé sur la vision pure. |
QAnything |
Questions et réponses basées sur n'importe quel contenu. |
PDF-Extract-Kit  |
Une puissante boîte à outils open-source conçue pour extraire efficacement du contenu de haute qualité à partir de documents PDF complexes et diversifiés. |
| Dango-Translator |
Reconnaît le texte à l'écran, le traduit et affiche les résultats de la traduction en temps réel. |
| En savoir plus | Plus de projets basés sur PaddleOCR |
👩👩👧👦 Contributeurs
🌟 Star
📄 Licence
Ce projet est publié sous la licence Apache 2.0.
🎓 Citation
@misc{paddleocr2020,
title={PaddleOCR, Awesome multilingual OCR toolkits based on PaddlePaddle.},
author={PaddlePaddle Authors},
howpublished = {\url{https://github.com/PaddlePaddle/PaddleOCR}},
year={2020}
}