21 KiB



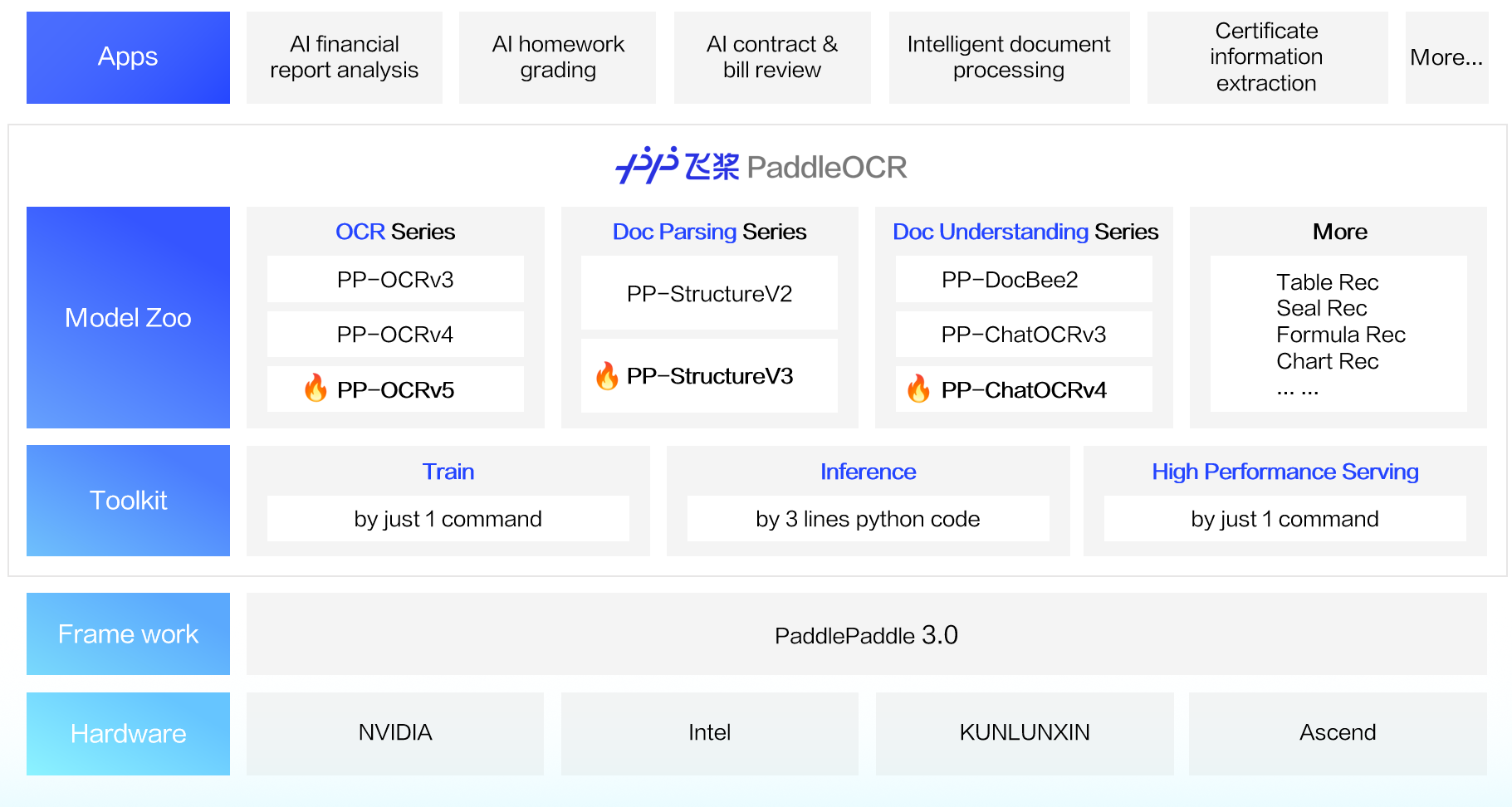
🚀 概要
PaddleOCRは、その最先端のアルゴリズムと実世界での応用実績により、初回リリース以来、学術界、産業界、研究コミュニティから広く支持を得ています。Umi-OCR、OmniParser、MinerU、RAGFlowなどの人気オープンソースプロジェクトで既に採用されており、世界中の開発者にとって定番のOCRツールキットとなっています。
2025年5月20日、PaddlePaddleチームはPaddlePaddle 3.0フレームワークの公式リリースに完全対応したPaddleOCR 3.0を発表しました。このアップデートでは、テキスト認識精度がさらに向上し、複数テキストタイプの認識と手書き文字認識がサポートされ、大規模モデルアプリケーションからの複雑なドキュメントの高精度解析に対する高まる需要に応えます。ERNIE 4.5 Turboと組み合わせることで、キー情報抽出の精度が大幅に向上します。完全な使用方法については、PaddleOCR 3.0 ドキュメント をご参照ください。
PaddleOCR 3.0の3つの主要な新機能:
-
全シーン対応テキスト認識モデル PP-OCRv5: 1つのモデルで5つの異なるテキストタイプと複雑な手書き文字を処理。全体の認識精度は前世代に比べて13パーセントポイント向上。オンラインデモ
-
汎用ドキュメント解析ソリューション PP-StructureV3: 複数レイアウト、複数シーンのPDFの高精度解析を実現し、公開ベンチマークで多くのオープンソースおよびクローズドソースのソリューションを凌駕。オンラインデモ
-
インテリジェントドキュメント理解ソリューション PP-ChatOCRv4: ERNIE 4.5 Turboにネイティブで対応し、前世代よりも15パーセントポイント高い精度を達成。オンラインデモ
PaddleOCR 3.0は、優れたモデルライブラリを提供するだけでなく、モデルのトレーニング、推論、サービス展開をカバーする使いやすいツールも提供しており、開発者がAIアプリケーションを迅速に本番環境に導入できるよう支援します。
📣 最近のアップデート
🔥🔥2025.06.26: PaddleOCR 3.0.3のリリース、以下の内容を含みます:
- バグ修正:
enable_mkldnnパラメータが機能しない問題を修正し、CPUがデフォルトでMKL-DNN推論を使用する動作を復元しました。
🔥🔥2025.06.19: PaddleOCR 3.0.2のリリース、以下の内容を含みます:
- 新機能:
- デフォルトのダウンロード元が
BOSからHuggingFaceに変更されました。ユーザーは環境変数PADDLE_PDX_MODEL_SOURCEをBOSに変更することで、モデルのダウンロード元をBaidu Object Storage (BOS)に戻すこともできます。 - PP-OCRv5、PP-StructureV3、PP-ChatOCRv4などのパイプラインに、C++、Java、Go、C#、Node.js、PHPの6言語のサービス呼び出し例を追加しました。
- PP-StructureV3パイプラインのレイアウト分割ソートアルゴリズムを改善し、複雑な縦書きレイアウトのソートロジックを強化して、より良い結果を提供します。
- モデル選択ロジックを強化:言語が指定されているがモデルのバージョンが指定されていない場合、システムはその言語をサポートする最新のモデルバージョンを自動的に選択します。
- MKL-DNNキャッシュサイズにデフォルトの上限を設定し、無制限の増加を防ぎます。同時に、ユーザーがキャッシュ容量を設定することも可能です。
- 高性能推論のデフォルト設定を更新し、Paddle MKL-DNNアクセラレーションをサポートし、よりスマートな選択のための自動設定選択ロジックを最適化しました。
- インストールされているPaddleフレームワークによる計算デバイスの実際のサポートを考慮するようにデフォルトデバイスの取得ロジックを調整し、プログラムの動作をより直感的にしました。
- PP-OCRv5のAndroidサンプルを追加しました。詳細。
- デフォルトのダウンロード元が
- バグ修正:
- PP-StructureV3の一部のCLIパラメータが有効にならない問題を修正しました。
- 特定のケースで
export_paddlex_config_to_yamlが正しく機能しない問題を解決しました。 save_pathの実際の動作とそのドキュメントの記述との間の不一致を修正しました。- 基本的なサービス展開でMKL-DNNを使用する際の潜在的なマルチスレッドエラーを修正しました。
- Latex-OCRモデルの画像前処理におけるチャネル順序のエラーを修正しました。
- テキスト認識モジュールで可視化画像を保存する際のチャネル順序のエラーを修正しました。
- PP-StructureV3パイプラインで可視化されたテーブル結果のチャネル順序のエラーを解決しました。
- PP-StructureV3パイプラインで非常に特殊な状況下で
overlap_ratioを計算する際のオーバーフロー問題を修正しました。
- ドキュメントの改善:
- ドキュメント内の
enable_mkldnnパラメータの説明を更新し、プログラムの実際の動作を正確に反映するようにしました。 langおよびocr_versionパラメータに関するドキュメントのエラーを修正しました。- CLIを介してプロダクションライン設定ファイルをエクスポートする手順を追加しました。
- PP-OCRv5のパフォーマンスデータテーブルで欠落していた列を修正しました。
- さまざまな構成におけるPP-StructureV3のベンチマーク指標を洗練しました。
- ドキュメント内の
- その他:
- numpyやpandasなどの依存関係のバージョン制限を緩和し、Python 3.12のサポートを復元しました。
更新履歴
🔥🔥 2025.06.05: PaddleOCR 3.0.1のリリース、以下の内容を含みます:
-
一部のモデルとモデル設定の最適化:
- PP-OCRv5のデフォルトモデル設定を更新し、検出と認識の両方をmobileモデルからserverモデルに変更しました。ほとんどのシーンでのデフォルト性能を向上させるため、設定の
limit_side_lenパラメータを736から64に変更しました。 - 新しいテキスト行方向分類モデル
PP-LCNet_x1_0_textline_ori(精度99.42%)を追加しました。OCR、PP-StructureV3、およびPP-ChatOCRv4パイプラインのデフォルトのテキスト行方向分類器がこのモデルに更新されました。 - テキスト行方向分類モデル
PP-LCNet_x0_25_textline_oriを最適化し、精度が3.3パーセントポイント向上し、現在の精度は98.85%です。
- PP-OCRv5のデフォルトモデル設定を更新し、検出と認識の両方をmobileモデルからserverモデルに変更しました。ほとんどのシーンでのデフォルト性能を向上させるため、設定の
-
バージョン3.0.0の一部の問題の最適化と修正、詳細
🔥🔥2025.05.20: PaddleOCR v3.0の公式リリース、以下の内容を含みます:
-
PP-OCRv5: あらゆるシーンに対応する高精度テキスト認識モデル - 画像/PDFから瞬時にテキストを抽出。
- 🌐 単一モデルで5つのテキストタイプをサポート - 簡体字中国語、繁体字中国語、簡体字中国語ピンイン、英語、日本語をシームレスに処理。
- ✍️ 手書き文字認識の向上:複雑な草書体や非標準的な手書き文字の認識性能が大幅に向上。
- 🎯 PP-OCRv4に比べて13ポイントの精度向上を達成し、さまざまな実世界のシナリオで最先端の性能を実現。
-
PP-StructureV3: 汎用ドキュメント解析 – 実世界のシナリオで最先端の画像/PDF解析を解放!
- 🧮 高精度な複数シーンPDF解析により、OmniDocBenchベンチマークでオープンソースおよびクローズドソースのソリューションをリード。
- 🧠 印鑑認識、グラフからテーブルへの変換、ネストされた数式/画像を含むテーブル認識、縦書きテキスト文書の解析、複雑なテーブル構造分析などの専門機能。
-
PP-ChatOCRv4: インテリジェントなドキュメント理解 – 画像/PDFからテキストだけでなく、キー情報を抽出。
- 🔥 PDF/PNG/JPGファイルからのキー情報抽出において、前世代に比べて15ポイントの精度向上。
- 💻 ERNIE 4.5 Turboをネイティブサポートし、PaddleNLP、Ollama、vLLMなどを介した大規模モデルのデプロイメントとの互換性あり。
- 🤝 PP-DocBee2 と統合し、印刷テキスト、手書き文字、印鑑、テーブル、グラフなど、複雑な文書内の一般的な要素の抽出と理解をサポート。
⚡ クイックスタート
1. オンラインデモの実行
2. インストール
インストールガイド を参照してPaddlePaddleをインストールした後、PaddleOCRツールキットをインストールします。
# paddleocrのインストール
pip install paddleocr
3. CLIによる推論の実行
# PP-OCRv5の推論を実行
paddleocr ocr -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --use_doc_orientation_classify False --use_doc_unwarping False --use_textline_orientation False
# PP-StructureV3の推論を実行
paddleocr pp_structurev3 -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_structure_v3_demo.png --use_doc_orientation_classify False --use_doc_unwarping False
# 最初にQianfan APIキーを取得し、その後PP-ChatOCRv4の推論を実行
paddleocr pp_chatocrv4_doc -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_certificate-1.png -k 驾驶室准乘人数 --qianfan_api_key your_api_key --use_doc_orientation_classify False --use_doc_unwarping False
# "paddleocr ocr" の詳細情報を取得
paddleocr ocr --help
4. APIによる推論の実行
4.1 PP-OCRv5の例
# PaddleOCRインスタンスの初期化
from paddleocr import PaddleOCR
ocr = PaddleOCR(
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False)
# サンプル画像でOCR推論を実行
result = ocr.predict(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png")
# 結果を可視化し、JSON形式で保存
for res in result:
res.print()
res.save_to_img("output")
res.save_to_json("output")
4.2 PP-StructureV3の例
from pathlib import Path
from paddleocr import PPStructureV3
pipeline = PPStructureV3(
use_doc_orientation_classify=False,
use_doc_unwarping=False
)
# 画像の場合
output = pipeline.predict(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_structure_v3_demo.png",
)
# 結果を可視化し、JSON形式で保存
for res in output:
res.print()
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")
4.3 PP-ChatOCRv4の例
from paddleocr import PPChatOCRv4Doc
chat_bot_config = {
"module_name": "chat_bot",
"model_name": "ernie-3.5-8k",
"base_url": "https://qianfan.baidubce.com/v2",
"api_type": "openai",
"api_key": "api_key", # your api_key
}
retriever_config = {
"module_name": "retriever",
"model_name": "embedding-v1",
"base_url": "https://qianfan.baidubce.com/v2",
"api_type": "qianfan",
"api_key": "api_key", # your api_key
}
pipeline = PPChatOCRv4Doc(
use_doc_orientation_classify=False,
use_doc_unwarping=False
)
visual_predict_res = pipeline.visual_predict(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_certificate-1.png",
use_common_ocr=True,
use_seal_recognition=True,
use_table_recognition=True,
)
mllm_predict_info = None
use_mllm = False
# マルチモーダル大規模モデルを使用する場合、ローカルmllmサービスを起動する必要があります。ドキュメント:https://github.com/PaddlePaddle/PaddleX/blob/release/3.0/docs/pipeline_usage/tutorials/vlm_pipelines/doc_understanding.en.md を参照してデプロイを行い、mllm_chat_bot_config設定を更新してください。
if use_mllm:
mllm_chat_bot_config = {
"module_name": "chat_bot",
"model_name": "PP-DocBee",
"base_url": "http://127.0.0.1:8080/", # your local mllm service url
"api_type": "openai",
"api_key": "api_key", # your api_key
}
mllm_predict_res = pipeline.mllm_pred(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_certificate-1.png",
key_list=["驾驶室准乘人数"],
mllm_chat_bot_config=mllm_chat_bot_config,
)
mllm_predict_info = mllm_predict_res["mllm_res"]
visual_info_list = []
for res in visual_predict_res:
visual_info_list.append(res["visual_info"])
layout_parsing_result = res["layout_parsing_result"]
vector_info = pipeline.build_vector(
visual_info_list, flag_save_bytes_vector=True, retriever_config=retriever_config
)
chat_result = pipeline.chat(
key_list=["驾驶室准乘人数"],
visual_info=visual_info_list,
vector_info=vector_info,
mllm_predict_info=mllm_predict_info,
chat_bot_config=chat_bot_config,
retriever_config=retriever_config,
)
print(chat_result)
⛰️ 上級チュートリアル
🔄 実行結果のクイックレビュー


👩👩👧👦 コミュニティ
| PaddlePaddle WeChat公式アカウント | 技術ディスカッショングループへの参加 |
|---|---|
 |
 |
😃 PaddleOCRを活用した素晴らしいプロジェクト
PaddleOCRは、その素晴らしいコミュニティなしでは今日の姿にはなりえませんでした!💗長年のパートナー、新しい協力者、そしてPaddleOCRに情熱を注いでくださったすべての方々に心から感謝申し上げます。皆様のサポートが私たちの原動力です!
| プロジェクト名 | 概要 |
|---|---|
RAGFlow  |
詳細なドキュメント理解に基づくRAGエンジン。 |
MinerU  |
複数タイプのドキュメントからMarkdownへの変換ツール |
Umi-OCR  |
無料、オープンソースのバッチオフラインOCRソフトウェア。 |
OmniParser |
OmniParser: 純粋なビジョンベースのGUIエージェントのための画面解析ツール。 |
QAnything |
あらゆるものに基づいた質疑応答。 |
PDF-Extract-Kit  |
複雑で多様なPDFドキュメントから高品質なコンテンツを効率的に抽出するために設計された強力なオープンソースツールキット。 |
| Dango-Translator |
画面上のテキストを認識し、翻訳して、リアルタイムで翻訳結果を表示します。 |
| 他のプロジェクトを見る | PaddleOCRをベースにした他のプロジェクト |
👩👩👧👦 貢献者
🌟 Star
📄 ライセンス
このプロジェクトはApache 2.0 licenseの下で公開されています。
🎓 引用
@misc{paddleocr2020,
title={PaddleOCR, Awesome multilingual OCR toolkits based on PaddlePaddle.},
author={PaddlePaddle Authors},
howpublished = {\url{https://github.com/PaddlePaddle/PaddleOCR}},
year={2020}
}