19 KiB



🚀 소개
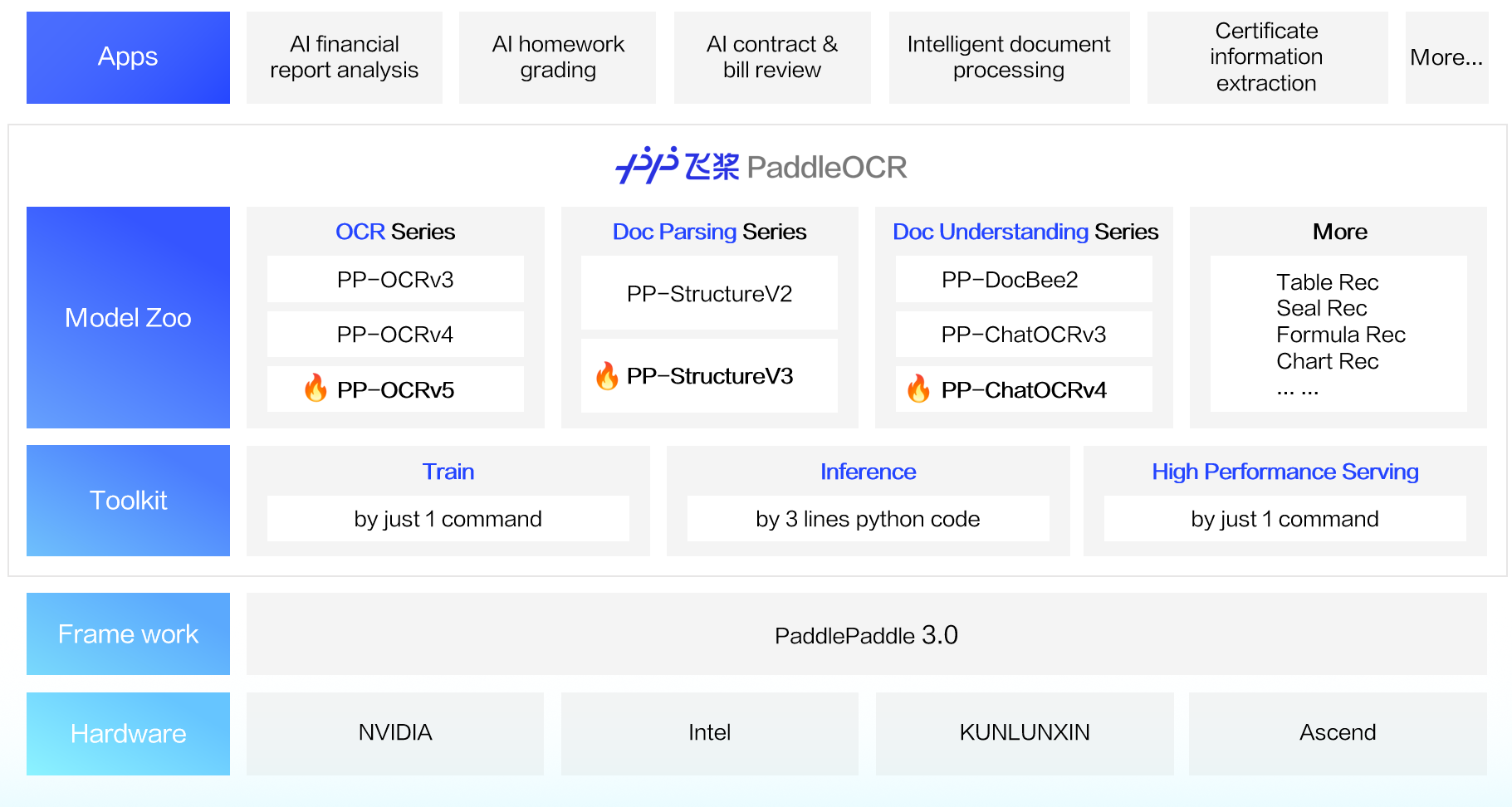
PaddleOCR은 출시 이후 최첨단 알고리즘(algorithm)과 실제 애플리케이션(application)에서의 입증된 성능 덕분에 학계, 산업계, 연구 커뮤니티에서 폭넓은 찬사를 받아왔습니다. Umi-OCR, OmniParser, MinerU, RAGFlow와 같은 유명 오픈소스 프로젝트에 이미 적용되어 전 세계 개발자(developer)들에게 필수 OCR 툴킷(toolkit)으로 자리 잡았습니다.
2025년 5월 20일, PaddlePaddle 팀은 PaddlePaddle 3.0 프레임워크의 공식 릴리스와 완전히 호환되는 PaddleOCR 3.0을 발표했습니다. 이 업데이트는 텍스트 인식 정확도를 더욱 향상시키고, 다중 텍스트 유형 인식 및 필기 인식을 지원하며, 대규모 모델 애플리케이션의 복잡한 문서의 고정밀 구문 분석에 대한 증가하는 수요를 충족합니다. ERNIE 4.5 Turbo와 결합하면 주요 정보 추출 정확도가 크게 향상됩니다. 사용 설명서 전체는 PaddleOCR 3.0 문서를 참조하십시오.
PaddleOCR 3.0의 세 가지 주요 신규 기능:
-
범용 장면 텍스트 인식 모델(Universal-Scene Text Recognition Model) PP-OCRv5: 다섯 가지 다른 텍스트 유형과 복잡한 필기체를 처리하는 단일 모델입니다. 전체 인식 정확도는 이전 세대보다 13%p 향상되었습니다. 온라인 체험
-
일반 문서 파싱(parsing) 솔루션 PP-StructureV3: 다중 레이아웃(multi-layout), 다중 장면 PDF의 고정밀 파싱(parsing)을 제공하며, 공개 벤치마크(benchmark)에서 많은 오픈 소스 및 클로즈드 소스 솔루션을 능가합니다. 온라인 체험
-
지능형 문서 이해 솔루션 PP-ChatOCRv4: ERNIE 4.5 Turbo에 의해 네이티브로 구동되며, 이전 모델보다 15%p 높은 정확도를 달성합니다. 온라인 체험
PaddleOCR 3.0은 뛰어난 모델 라이브러리(model library)를 제공할 뿐만 아니라 모델 훈련, 추론 및 서비스 배포를 포괄하는 사용하기 쉬운 도구를 제공하여 개발자가 AI 애플리케이션을 신속하게 상용화할 수 있도록 지원합니다.
📣 최신 업데이트
2025.06.26: PaddleOCR 3.0.3 릴리스, 포함 내용:
- 버그 수정:
enable_mkldnn매개변수가 작동하지 않는 문제를 해결하고, CPU가 기본적으로 MKL-DNN 추론을 사용하는 동작을 복원했습니다.
🔥🔥 2025.06.19: PaddleOCR 3.0.2 릴리스, 포함 내용:
-
새로운 기능:
- 모델 기본 다운로드 소스가
BOS에서HuggingFace로 변경되었습니다. 사용자는 환경 변수PADDLE_PDX_MODEL_SOURCE를BOS로 설정하여 모델 다운로드 소스를 Baidu Object Storage(BOS)로 되돌릴 수 있습니다. - PP-OCRv5, PP-StructureV3, PP-ChatOCRv4 파이프라인에 대해 C++, Java, Go, C#, Node.js, PHP 6개 언어의 서비스 호출 예제가 추가되었습니다.
- PP-StructureV3 파이프라인의 레이아웃 파티션 정렬 알고리즘을 개선하여 복잡한 세로 레이아웃의 정렬 논리를 향상했습니다.
- 언어(
lang)만 지정하고 모델 버전을 명시하지 않은 경우, 해당 언어를 지원하는 최신 모델 버전을 자동으로 선택하도록 모델 선택 로직을 강화했습니다. - MKL-DNN 캐시 크기에 기본 상한을 설정하여 무한 확장을 방지하고, 사용자 정의 캐시 용량 설정을 지원합니다.
- 고성능 추론의 기본 구성을 업데이트하여 Paddle MKL-DNN 가속을 지원하고, 자동 구성 선택 로직을 최적화했습니다.
- 설치된 Paddle 프레임워크가 지원하는 실제 디바이스를 고려하도록 기본 디바이스 선택 로직을 조정했습니다.
- PP-OCRv5의 Android 예제가 추가되었습니다. Details.
- 모델 기본 다운로드 소스가
-
버그 수정:
- PP-StructureV3 일부 CLI 파라미터가 적용되지 않던 문제를 수정했습니다.
export_paddlex_config_to_yaml가 특정 상황에서 정상 동작하지 않던 문제를 해결했습니다.save_path의 실제 동작과 문서 설명이 일치하지 않던 문제를 수정했습니다.- 기본 서비스화 배포에서 MKL-DNN을 사용할 때 발생할 수 있는 다중 스레딩 오류를 수정했습니다.
- Latex-OCR 모델의 이미지 전처리 과정에서 채널 순서 오류를 수정했습니다.
- 텍스트 인식 모듈에서 시각화 이미지를 저장할 때 발생하던 채널 순서 오류를 수정했습니다.
- PP-StructureV3 파이프라인의 표 시각화 결과에 발생하던 채널 순서 오류를 수정했습니다.
- PP-StructureV3 파이프라인에서 특수한 상황에서
overlap_ratio계산 시 발생하던 오버플로 문제를 수정했습니다.
-
문서 개선:
- 문서의
enable_mkldnn파라미터 설명을 프로그램의 실제 동작에 맞게 업데이트했습니다. lang및ocr_version파라미터에 대한 문서 오류를 수정했습니다.- CLI를 통해 생산 라인 설정 파일을 내보내는 방법을 문서에 추가했습니다.
- PP-OCRv5 성능 데이터 표에서 누락된 열을 복원했습니다.
- 다양한 구성에서 PP-StructureV3의 벤치마크 지표를 개선했습니다.
- 문서의
-
기타:
- numpy, pandas 등 의존성 버전 제한을 완화하여 Python 3.12 지원을 복원했습니다.
🔥🔥 2025.06.05: PaddleOCR 3.0.1 릴리스, 포함 내용:
-
일부 모델 및 모델 구성 최적화:
- PP-OCRv5의 기본 모델 구성을 업데이트하여 탐지 및 인식을 모두 mobile에서 server 모델로 변경했습니다. 대부분의 시나리오에서 기본 성능을 향상시키기 위해 구성의
limit_side_len파라미터(parameter)가 736에서 64로 변경되었습니다. - 99.42%의 정확도를 가진 새로운 텍스트 라인 방향 분류 모델
PP-LCNet_x1_0_textline_ori를 추가했습니다. OCR, PP-StructureV3, PP-ChatOCRv4 파이프라인의 기본 텍스트 라인 방향 분류기가 이 모델로 업데이트되었습니다. - 텍스트 라인 방향 분류 모델
PP-LCNet_x0_25_textline_ori를 최적화하여 정확도를 3.3%p 향상시켜 현재 정확도는 98.85%입니다.
- PP-OCRv5의 기본 모델 구성을 업데이트하여 탐지 및 인식을 모두 mobile에서 server 모델로 변경했습니다. 대부분의 시나리오에서 기본 성능을 향상시키기 위해 구성의
-
버전 3.0.0의 일부 문제점에 대한 최적화 및 수정, 상세 정보
🔥🔥2025.05.20: PaddleOCR v3.0 정식 출시, 포함 내용:
-
PP-OCRv5: 모든 시나리오를 위한 고정밀 텍스트 인식 모델 - 이미지/PDF에서 즉시 텍스트 추출.
- 🌐 단일 모델로 다섯 가지 텍스트 유형 지원 - 중국어 간체, 중국어 번체, 중국어 간체 병음, 영어, 일본어를 단일 모델 내에서 원활하게 처리합니다.
- ✍️ 향상된 필기체 인식: 복잡한 흘림체 및 비표준 필기체에서 성능이 크게 향상되었습니다.
- 🎯 PP-OCRv4에 비해 정확도 13%p 향상, 다양한 실제 시나리오에서 SOTA(state-of-the-art) 성능을 달성했습니다.
-
PP-StructureV3: 범용 문서 파싱(parsing) – 실제 시나리오를 위한 SOTA 이미지/PDF 파싱(parsing) 성능!
- 🧮 고정밀 다중 장면 PDF 파싱(parsing), OmniDocBench 벤치마크(benchmark)에서 오픈 소스 및 클로즈드 소스 솔루션을 모두 능가합니다.
- 🧠 전문 기능에는 도장 인식, 차트-표 변환, 중첩된 수식/이미지가 있는 표 인식, 세로 텍스트 문서 파싱(parsing), 복잡한 표 구조 분석 등이 포함됩니다.
-
PP-ChatOCRv4: 지능형 문서 이해 – 이미지/PDF에서 단순한 텍스트가 아닌 핵심 정보 추출.
- 🔥 이전 세대에 비해 PDF/PNG/JPG 파일의 핵심 정보 추출에서 정확도 15%p 향상.
- 💻 ERNIE 4.5 Turbo 기본 지원, PaddleNLP, Ollama, vLLM 등을 통한 대규모 모델 배포와 호환됩니다.
- 🤝 PP-DocBee2와 통합되어 인쇄된 텍스트, 필기체, 도장, 표, 차트 등 복잡한 문서의 일반적인 요소 추출 및 이해를 지원합니다.
⚡ 빠른 시작
1. 온라인 데모 실행
2. 설치
설치 가이드를 참조하여 PaddlePaddle을 설치한 후, PaddleOCR 툴킷을 설치하십시오.
# paddleocr 설치
pip install paddleocr
3. CLI를 통한 추론 실행
# PP-OCRv5 추론 실행
paddleocr ocr -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --use_doc_orientation_classify False --use_doc_unwarping False --use_textline_orientation False
# PP-StructureV3 추론 실행
paddleocr pp_structurev3 -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_structure_v3_demo.png --use_doc_orientation_classify False --use_doc_unwarping False
# 먼저 Qianfan API 키를 받고, PP-ChatOCRv4 추론 실행
paddleocr pp_chatocrv4_doc -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_certificate-1.png -k 驾驶室准乘人数 --qianfan_api_key your_api_key --use_doc_orientation_classify False --use_doc_unwarping False
# "paddleocr ocr"에 대한 추가 정보 얻기
paddleocr ocr --help
4. API를 통한 추론 실행
4.1 PP-OCRv5 예제
from paddleocr import PaddleOCR
# PaddleOCR 인스턴스 초기화
ocr = PaddleOCR(
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False)
# 샘플 이미지에 대해 OCR 추론 실행
result = ocr.predict(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png")
# 결과 시각화 및 JSON 결과 저장
for res in result:
res.print()
res.save_to_img("output")
res.save_to_json("output")
4.2 PP-StructureV3 예제
from pathlib import Path
from paddleocr import PPStructureV3
pipeline = PPStructureV3(
use_doc_orientation_classify=False,
use_doc_unwarping=False
)
# 이미지용
output = pipeline.predict(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_structure_v3_demo.png",
)
# 결과 시각화 및 JSON 결과 저장
for res in output:
res.print()
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")
4.3 PP-ChatOCRv4 예제
from paddleocr import PPChatOCRv4Doc
chat_bot_config = {
"module_name": "chat_bot",
"model_name": "ernie-3.5-8k",
"base_url": "https://qianfan.baidubce.com/v2",
"api_type": "openai",
"api_key": "api_key", # your api_key
}
retriever_config = {
"module_name": "retriever",
"model_name": "embedding-v1",
"base_url": "https://qianfan.baidubce.com/v2",
"api_type": "qianfan",
"api_key": "api_key", # your api_key
}
pipeline = PPChatOCRv4Doc(
use_doc_orientation_classify=False,
use_doc_unwarping=False
)
visual_predict_res = pipeline.visual_predict(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_certificate-1.png",
use_common_ocr=True,
use_seal_recognition=True,
use_table_recognition=True,
)
mllm_predict_info = None
use_mllm = False
# 다중 모드 대형 모델을 사용하는 경우 로컬 mllm 서비스를 시작해야 합니다. 문서: https://github.com/PaddlePaddle/PaddleX/blob/release/3.0/docs/pipeline_usage/tutorials/vlm_pipelines/doc_understanding.en.md를 참조하여 배포하고 mllm_chat_bot_config 구성을 업데이트할 수 있습니다.
if use_mllm:
mllm_chat_bot_config = {
"module_name": "chat_bot",
"model_name": "PP-DocBee",
"base_url": "http://127.0.0.1:8080/", # your local mllm service url
"api_type": "openai",
"api_key": "api_key", # your api_key
}
mllm_predict_res = pipeline.mllm_pred(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_certificate-1.png",
key_list=["驾驶室准乘人数"],
mllm_chat_bot_config=mllm_chat_bot_config,
)
mllm_predict_info = mllm_predict_res["mllm_res"]
visual_info_list = []
for res in visual_predict_res:
visual_info_list.append(res["visual_info"])
layout_parsing_result = res["layout_parsing_result"]
vector_info = pipeline.build_vector(
visual_info_list, flag_save_bytes_vector=True, retriever_config=retriever_config
)
chat_result = pipeline.chat(
key_list=["驾驶室准乘人数"],
visual_info=visual_info_list,
vector_info=vector_info,
mllm_predict_info=mllm_predict_info,
chat_bot_config=chat_bot_config,
retriever_config=retriever_config,
)
print(chat_result)
⛰️ 고급 튜토리얼
🔄 실행 결과 빠른 개요


👩👩👧👦 커뮤니티
| PaddlePaddle 위챗(WeChat) 공식 계정 | 기술 토론 그룹 가입 |
|---|---|
 |
 |
🏆 PaddleOCR을 활용하는 우수 프로젝트
PaddleOCR의 발전은 커뮤니티 없이는 불가능합니다! 💗 오랜 파트너, 새로운 협력자, 그리고 이름을 언급했든 안 했든 PaddleOCR에 열정을 쏟아부은 모든 분들께 진심으로 감사드립니다. 여러분의 지원이 우리의 원동력입니다!
| 프로젝트 이름 | 설명 |
|---|---|
RAGFlow  |
심층 문서 이해 기반의 RAG 엔진. |
MinerU  |
다중 유형 문서를 마크다운(Markdown)으로 변환하는 도구 |
Umi-OCR  |
무료, 오픈 소스, 배치 오프라인 OCR 소프트웨어. |
OmniParser |
순수 비전 기반 GUI 에이전트를 위한 화면 파싱(parsing) 도구. |
QAnything |
무엇이든 기반으로 한 질의응답 시스템. |
PDF-Extract-Kit  |
복잡하고 다양한 PDF 문서에서 고품질 콘텐츠를 효율적으로 추출하도록 설계된 강력한 오픈 소스 툴킷. |
| Dango-Translator |
화면의 텍스트를 인식하여 번역하고 번역 결과를 실시간으로 표시합니다. |
| Learn more projects | More projects based on PaddleOCR |
👩👩👧👦 기여자
🌟 Star
📄 라이선스
이 프로젝트는 Apache 2.0 license에 따라 배포됩니다.
🎓 인용
@misc{paddleocr2020,
title={PaddleOCR, Awesome multilingual OCR toolkits based on PaddlePaddle.},
author={PaddlePaddle Authors},
howpublished = {\url{https://github.com/PaddlePaddle/PaddleOCR}},
year={2020}
}