飞桨训推一体认证
1. 简介
飞桨除了基本的模型训练和预测,还提供了支持多端多平台的高性能推理部署工具。本文档提供了PaddleOCR中所有模型的飞桨训推一体认证 (Training and Inference Pipeline Certification(TIPC)) 信息和测试工具,方便用户查阅每种模型的训练推理部署打通情况,并可以进行一键测试。
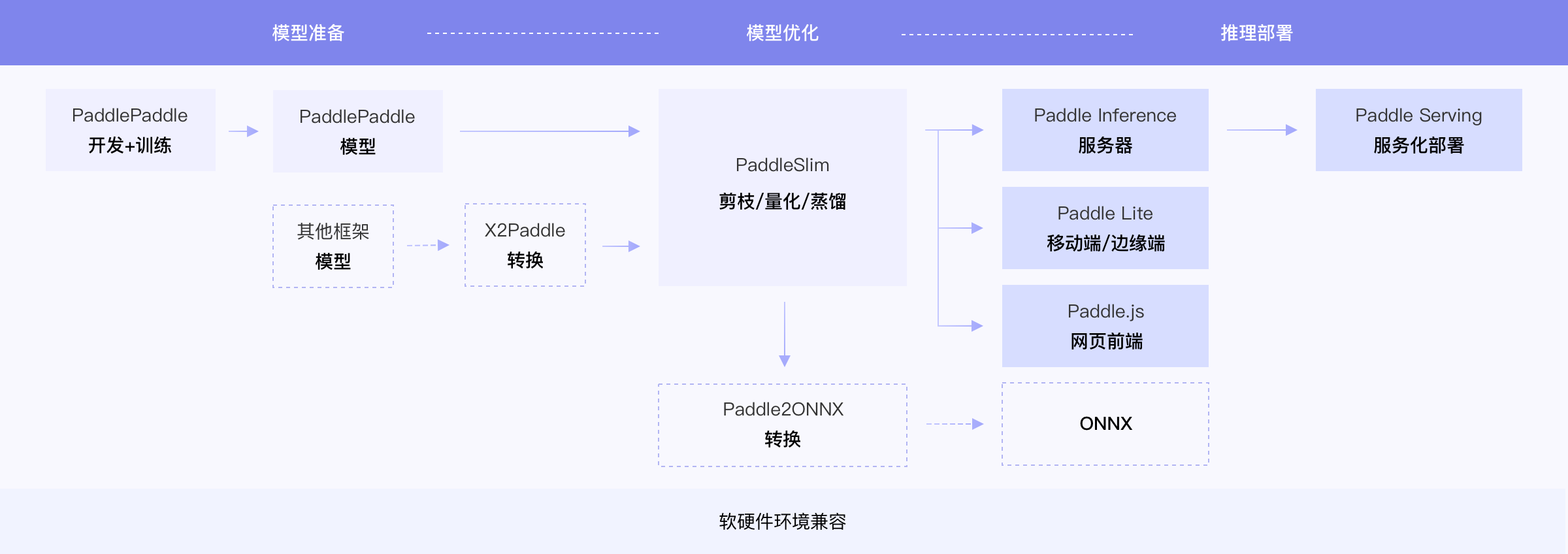
2. 汇总信息
打通情况汇总如下,已填写的部分表示可以使用本工具进行一键测试,未填写的表示正在支持中。
字段说明:
- 基础训练预测:包括模型训练、Paddle Inference Python预测。
- 更多训练方式:包括多机多卡、混合精度。
- 模型压缩:包括裁剪、离线/在线量化、蒸馏。
- 其他预测部署:包括Paddle Inference C++预测、Paddle Serving部署、Paddle-Lite部署等。
更详细的mkldnn、Tensorrt等预测加速相关功能的支持情况可以查看各测试工具的更多教程。
| 算法论文 | 模型名称 | 模型类型 | 基础 训练预测 |
更多 训练方式 |
模型压缩 | 其他预测部署 |
|---|---|---|---|---|---|---|
| DB | ch_ppocr_mobile_v2.0_det | 检测 | 支持 | 多机多卡 混合精度 |
FPGM裁剪 离线量化 |
Paddle Inference: C++ Paddle Serving: Python, C++ Paddle-Lite: (1) ARM CPU(C++) |
| DB | ch_ppocr_server_v2.0_det | 检测 | 支持 | 多机多卡 混合精度 |
FPGM裁剪 离线量化 |
Paddle Inference: C++ Paddle Serving: Python, C++ Paddle-Lite: (1) ARM CPU(C++) |
| DB | ch_PP-OCRv2_det | 检测 | ||||
| CRNN | ch_ppocr_mobile_v2.0_rec | 识别 | 支持 | 多机多卡 混合精度 |
PACT量化 离线量化 |
Paddle Inference: C++ Paddle Serving: Python, C++ Paddle-Lite: (1) ARM CPU(C++) |
| CRNN | ch_ppocr_server_v2.0_rec | 识别 | 支持 | 多机多卡 混合精度 |
PACT量化 离线量化 |
Paddle Inference: C++ Paddle Serving: Python, C++ Paddle-Lite: (1) ARM CPU(C++) |
| CRNN | ch_PP-OCRv2_rec | 识别 | ||||
| PP-OCR | ch_ppocr_mobile_v2.0 | 检测+识别 | 支持 | 多机多卡 混合精度 |
- | Paddle Inference: C++ Paddle Serving: Python, C++ Paddle-Lite: (1) ARM CPU(C++) |
| PP-OCR | ch_ppocr_server_v2.0 | 检测+识别 | 支持 | 多机多卡 混合精度 |
- | Paddle Inference: C++ Paddle Serving: Python, C++ Paddle-Lite: (1) ARM CPU(C++) |
| PP-OCRv2 | ch_PP-OCRv2 | 检测+识别 | ||||
| DB | det_mv3_db_v2.0 | 检测 | ||||
| DB | det_r50_vd_db_v2.0 | 检测 | ||||
| EAST | det_mv3_east_v2.0 | 检测 | ||||
| EAST | det_r50_vd_east_v2.0 | 检测 | ||||
| PSENet | det_mv3_pse_v2.0 | 检测 | ||||
| PSENet | det_r50_vd_pse_v2.0 | 检测 | ||||
| SAST | det_r50_vd_sast_totaltext_v2.0 | 检测 | ||||
| Rosetta | rec_mv3_none_none_ctc_v2.0 | 识别 | ||||
| Rosetta | rec_r34_vd_none_none_ctc_v2.0 | 识别 | ||||
| CRNN | rec_mv3_none_bilstm_ctc_v2.0 | 识别 | ||||
| CRNN | rec_r34_vd_none_bilstm_ctc_v2.0 | 识别 | ||||
| StarNet | rec_mv3_tps_bilstm_ctc_v2.0 | 识别 | ||||
| StarNet | rec_r34_vd_tps_bilstm_ctc_v2.0 | 识别 | ||||
| RARE | rec_mv3_tps_bilstm_att_v2.0 | 识别 | ||||
| RARE | rec_r34_vd_tps_bilstm_att_v2.0 | 识别 | ||||
| SRN | rec_r50fpn_vd_none_srn | 识别 | ||||
| NRTR | rec_mtb_nrtr | 识别 | ||||
| SAR | rec_r31_sar | 识别 | ||||
| PGNet | rec_r34_vd_none_none_ctc_v2.0 | 端到端 |
3. 一键测试工具使用
目录介绍
test_tipc/
├── configs/ # 配置文件目录
├── ppocr_det_mobile # ppocr_det_mobile模型的测试配置文件目录
├── det_mv3_db.yml # 测试mobile版ppocr检测模型训练的yml文件
├── train_infer_python.txt.txt # 测试Linux上python训练预测(基础训练预测)的配置文件
├── model_linux_gpu_normal_normal_infer_cpp_linux_gpu_cpu.txt # 测试Linux上c++预测的配置文件
├── model_linux_gpu_normal_normal_infer_python_jetson.txt # 测试Jetson上python预测的配置文件
├── train_linux_gpu_fleet_amp_infer_python_linux_gpu_cpu.txt # 测试Linux上多机多卡、混合精度训练和python预测的配置文件
├── ...
├── ppocr_det_server # ppocr_det_server模型的测试配置文件目录
├── ...
├── ppocr_rec_mobile # ppocr_rec_mobile模型的测试配置文件目录
├── ...
├── ppocr_rec_server # ppocr_rec_server模型的测试配置文件目录
├── ...
├── ...
├── results/ # 预先保存的预测结果,用于和实际预测结果进行精读比对
├── python_ppocr_det_mobile_results_fp32.txt # 预存的mobile版ppocr检测模型python预测fp32精度的结果
├── python_ppocr_det_mobile_results_fp16.txt # 预存的mobile版ppocr检测模型python预测fp16精度的结果
├── cpp_ppocr_det_mobile_results_fp32.txt # 预存的mobile版ppocr检测模型c++预测的fp32精度的结果
├── cpp_ppocr_det_mobile_results_fp16.txt # 预存的mobile版ppocr检测模型c++预测的fp16精度的结果
├── ...
├── prepare.sh # 完成test_*.sh运行所需要的数据和模型下载
├── test_train_inference_python.sh # 测试python训练预测的主程序
├── test_inference_cpp.sh # 测试c++预测的主程序
├── test_serving.sh # 测试serving部署预测的主程序
├── test_lite_arm_cpu_cpp.sh # 测试lite在arm_cpu上部署的C++预测的主程序
├── compare_results.py # 用于对比log中的预测结果与results中的预存结果精度误差是否在限定范围内
└── readme.md # 使用文档
配置文件命名规范
在configs目录下,按模型名称划分为子目录,子目录中存放所有该模型测试需要用到的配置文件,配置文件的命名遵循如下规范:
-
基础训练预测配置简单命名为:
train_infer_python.txt,表示Linux环境下单机、不使用混合精度训练+python预测,其完整命名对应train_linux_gpu_fleet_amp_infer_python_linux_gpu_cpu.txt,由于本配置文件使用频率较高,这里进行了名称简化。 -
其他带训练配置命名格式为:
train_训练硬件环境(linux_gpu/linux_dcu/…)_是否多机(fleet/normal)_是否混合精度(amp/normal)_预测模式(infer/lite/serving/js)_语言(cpp/python/java)_预测硬件环境(linux_gpu/mac/jetson/opencl_arm_gpu/...).txt。如,linux gpu下多机多卡+混合精度链条测试对应配置train_linux_gpu_fleet_amp_infer_python_linux_gpu_cpu.txt,linux dcu下基础训练预测对应配置train_linux_dcu_normal_normal_infer_python_dcu.txt。 -
仅预测的配置(如serving、lite等)命名格式:
model_训练硬件环境(linux_gpu/linux_dcu/…)_是否多机(fleet/normal)_是否混合精度(amp/normal)_(infer/lite/serving/js)_语言(cpp/python/java)_预测硬件环境(linux_gpu/mac/jetson/opencl_arm_gpu/...).txt,即,与2相比,仅第一个字段从train换为model,测试时模型直接下载获取,这里的“训练硬件环境”表示所测试的模型是在哪种环境下训练得到的。
根据上述命名规范,可以直接从配置文件名看出对应的测试场景和功能。
测试流程
使用本工具,可以测试不同功能的支持情况,以及预测结果是否对齐,测试流程如下:

- 运行prepare.sh准备测试所需数据和模型;
- 运行要测试的功能对应的测试脚本
test_*.sh,产出log,由log可以看到不同配置是否运行成功; - 用
compare_results.py对比log中的预测结果和预存在results目录下的结果,判断预测精度是否符合预期(在误差范围内)。
其中,有4个测试主程序,功能如下:
test_train_inference_python.sh:测试基于Python的模型训练、评估、推理等基本功能,包括裁剪、量化、蒸馏。test_inference_cpp.sh:测试基于C++的模型推理。test_serving.sh:测试基于Paddle Serving的服务化部署功能。test_lite_arm_cpu_cpp.sh:测试基于Paddle-Lite的ARM CPU端c++预测部署功能。test_paddle2onnx.sh:测试Paddle2ONNX的模型转化功能,并验证正确性。
更多教程
各功能测试中涉及混合精度、裁剪、量化等训练相关,及mkldnn、Tensorrt等多种预测相关参数配置,请点击下方相应链接了解更多细节和使用教程:
test_train_inference_python 使用
test_inference_cpp 使用
test_serving 使用
test_lite_arm_cpu_cpp 使用
test_paddle2onnx 使用