# Distributed Group Chat
from autogen_core.application import WorkerAgentRuntimeHost
This example runs a gRPC server using [WorkerAgentRuntimeHost](../../src/autogen_core/application/_worker_runtime_host.py) and instantiates three distributed runtimes using [WorkerAgentRuntime](../../src/autogen_core/application/_worker_runtime.py). These runtimes connect to the gRPC server as hosts and facilitate a round-robin distributed group chat. This example leverages the [Azure OpenAI Service](https://azure.microsoft.com/en-us/products/ai-services/openai-service) to implement writer and editor LLM agents. Agents are instructed to provide concise answers, as the primary goal of this example is to showcase the distributed runtime rather than the quality of agent responses.
## Setup
### Setup Python Environment
1. Create a virtual environment as instructed in [README](../../../../../../../../README.md).
2. Run `uv pip install chainlit` in the same virtual environment
### General Configuration
In the `config.yaml` file, you can configure the `client_config` section to connect the code to the Azure OpenAI Service.
### Authentication
The recommended method for authentication is through Azure Active Directory (AAD), as explained in [Model Clients - Azure AI](https://microsoft.github.io/autogen/dev/user-guide/core-user-guide/framework/model-clients.html#azure-openai). This example works with both the AAD approach (recommended) and by providing the `api_key` in the `config.yaml` file.
## Run
### Run Through Scripts
The [run.sh](./run.sh) file provides commands to run the host and agents using [tmux](https://github.com/tmux/tmux/wiki). The steps for this approach are:
1. Install tmux.
2. Activate the Python environment: `source .venv/bin/activate`.
3. Run the bash script: `./run.sh`.
Here is a screen recording of the execution:
[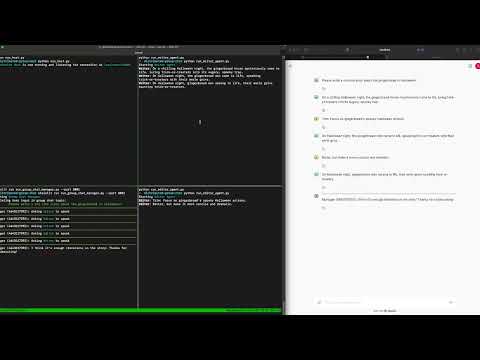](https://youtu.be/kLTzI-3VgPQ)
**Note**: Some `asyncio.sleep` commands have been added to the example code to make the `./run.sh` execution look sequential and visually easy to follow. In practice, these lines are not necessary.
### Run Individual Files
If you prefer to run Python files individually, follow these steps. Note that each step must be run in a different terminal process, and the virtual environment should be activated using `source .venv/bin/activate`.
1. `python run_host.py`: Starts the host and listens for agent connections.
2. `python run_editor.py`: Starts the  editor agent and connects it to the host.
3. `python run_writer.py`: Starts the
editor agent and connects it to the host.
3. `python run_writer.py`: Starts the  writer agent and connects it to the host.
4. `chainlit run run_group_chat_manager.py --port 8001`: Run chainlit app which starts
writer agent and connects it to the host.
4. `chainlit run run_group_chat_manager.py --port 8001`: Run chainlit app which starts  group chat manager agent and sends the initial message to start the conversation. We're using port 8001 as the default port 8000 is used to run host (assuming using same machine to run all of the agents)
## What's Going On?
The general flow of this example is as follows:
1. The Group Chat Manager, on behalf of
group chat manager agent and sends the initial message to start the conversation. We're using port 8001 as the default port 8000 is used to run host (assuming using same machine to run all of the agents)
## What's Going On?
The general flow of this example is as follows:
1. The Group Chat Manager, on behalf of  `User`, sends a `RequestToSpeak` request to the `writer_agent`.
2. The `writer_agent` writes a short sentence into the group chat topic.
3. The `editor_agent` receives the message in the group chat topic and updates its memory.
4. The Group Chat Manager receives the message sent by the writer into the group chat simultaneously and sends the next participant, the `editor_agent`, a `RequestToSpeak` message.
5. The `editor_agent` sends its feedback to the group chat topic.
6. The `writer_agent` receives the feedback and updates its memory.
7. The Group Chat Manager receives the message simultaneously and repeats the loop from step 1.
Here is an illustration of the system developed in this example:
```mermaid
graph TD;
subgraph Host
A1[GRPC Server]
wt[Writer Topic]
et[Editor Topic]
gct[Group Chat Topic]
end
subgraph Distributed Writer Runtime
writer_agent[ Writer Agent] --> A1
wt -.->|2 - Subscription| writer_agent
gct -.->|4 - Subscription| writer_agent
writer_agent -.->|3 - Publish: Group Chat Message| gct
end
subgraph Distributed Editor Runtime
editor_agent[ Editor Agent] --> A1
et -.->|6 - Subscription| editor_agent
gct -.->|4 - Subscription| editor_agent
editor_agent -.->|7 - Publish: Group Chat Message| gct
end
subgraph Distributed Group Chat Manager Runtime
group_chat_manager[ Group Chat Manager Agent] --> A1
gct -.->|4 - Subscription| group_chat_manager
group_chat_manager -.->|1 - Request To Speak| wt
group_chat_manager -.->|5 - Request To Speak| et
end
style wt fill:#beb2c3,color:#000
style et fill:#beb2c3,color:#000
style gct fill:#beb2c3,color:#000
style writer_agent fill:#b7c4d7,color:#000
style editor_agent fill:#b7c4d7,color:#000
style group_chat_manager fill:#b7c4d7,color:#000
```
## TODO:
- [ ] Properly handle chat restarts. It complains about group chat manager being already registered
- [ ] Send Chainlit messages within each agent (Currently the manager can just sends messages in the group chat topic)
- [ ] Add streaming to the UI like [this example](https://docs.chainlit.io/advanced-features/streaming) but Autogen's Open AI Client [does not supporting streaming yet](https://github.com/microsoft/autogen/blob/0f4dd0cc6dd3eea303ad3d2063979b4b9a1aacfc/python/packages/autogen-ext/src/autogen_ext/models/_openai/_openai_client.py#L81)
`User`, sends a `RequestToSpeak` request to the `writer_agent`.
2. The `writer_agent` writes a short sentence into the group chat topic.
3. The `editor_agent` receives the message in the group chat topic and updates its memory.
4. The Group Chat Manager receives the message sent by the writer into the group chat simultaneously and sends the next participant, the `editor_agent`, a `RequestToSpeak` message.
5. The `editor_agent` sends its feedback to the group chat topic.
6. The `writer_agent` receives the feedback and updates its memory.
7. The Group Chat Manager receives the message simultaneously and repeats the loop from step 1.
Here is an illustration of the system developed in this example:
```mermaid
graph TD;
subgraph Host
A1[GRPC Server]
wt[Writer Topic]
et[Editor Topic]
gct[Group Chat Topic]
end
subgraph Distributed Writer Runtime
writer_agent[ Writer Agent] --> A1
wt -.->|2 - Subscription| writer_agent
gct -.->|4 - Subscription| writer_agent
writer_agent -.->|3 - Publish: Group Chat Message| gct
end
subgraph Distributed Editor Runtime
editor_agent[ Editor Agent] --> A1
et -.->|6 - Subscription| editor_agent
gct -.->|4 - Subscription| editor_agent
editor_agent -.->|7 - Publish: Group Chat Message| gct
end
subgraph Distributed Group Chat Manager Runtime
group_chat_manager[ Group Chat Manager Agent] --> A1
gct -.->|4 - Subscription| group_chat_manager
group_chat_manager -.->|1 - Request To Speak| wt
group_chat_manager -.->|5 - Request To Speak| et
end
style wt fill:#beb2c3,color:#000
style et fill:#beb2c3,color:#000
style gct fill:#beb2c3,color:#000
style writer_agent fill:#b7c4d7,color:#000
style editor_agent fill:#b7c4d7,color:#000
style group_chat_manager fill:#b7c4d7,color:#000
```
## TODO:
- [ ] Properly handle chat restarts. It complains about group chat manager being already registered
- [ ] Send Chainlit messages within each agent (Currently the manager can just sends messages in the group chat topic)
- [ ] Add streaming to the UI like [this example](https://docs.chainlit.io/advanced-features/streaming) but Autogen's Open AI Client [does not supporting streaming yet](https://github.com/microsoft/autogen/blob/0f4dd0cc6dd3eea303ad3d2063979b4b9a1aacfc/python/packages/autogen-ext/src/autogen_ext/models/_openai/_openai_client.py#L81)