
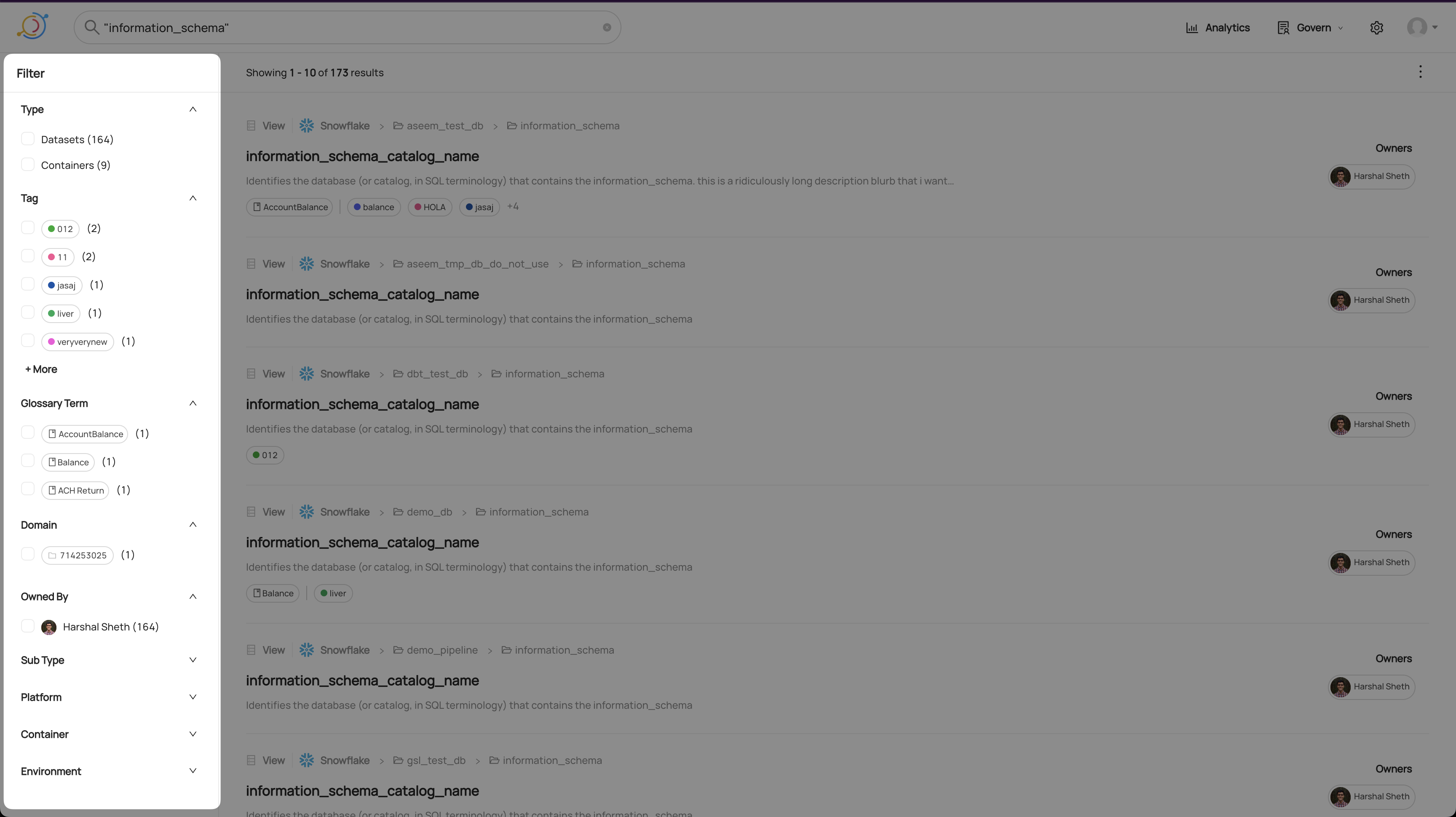
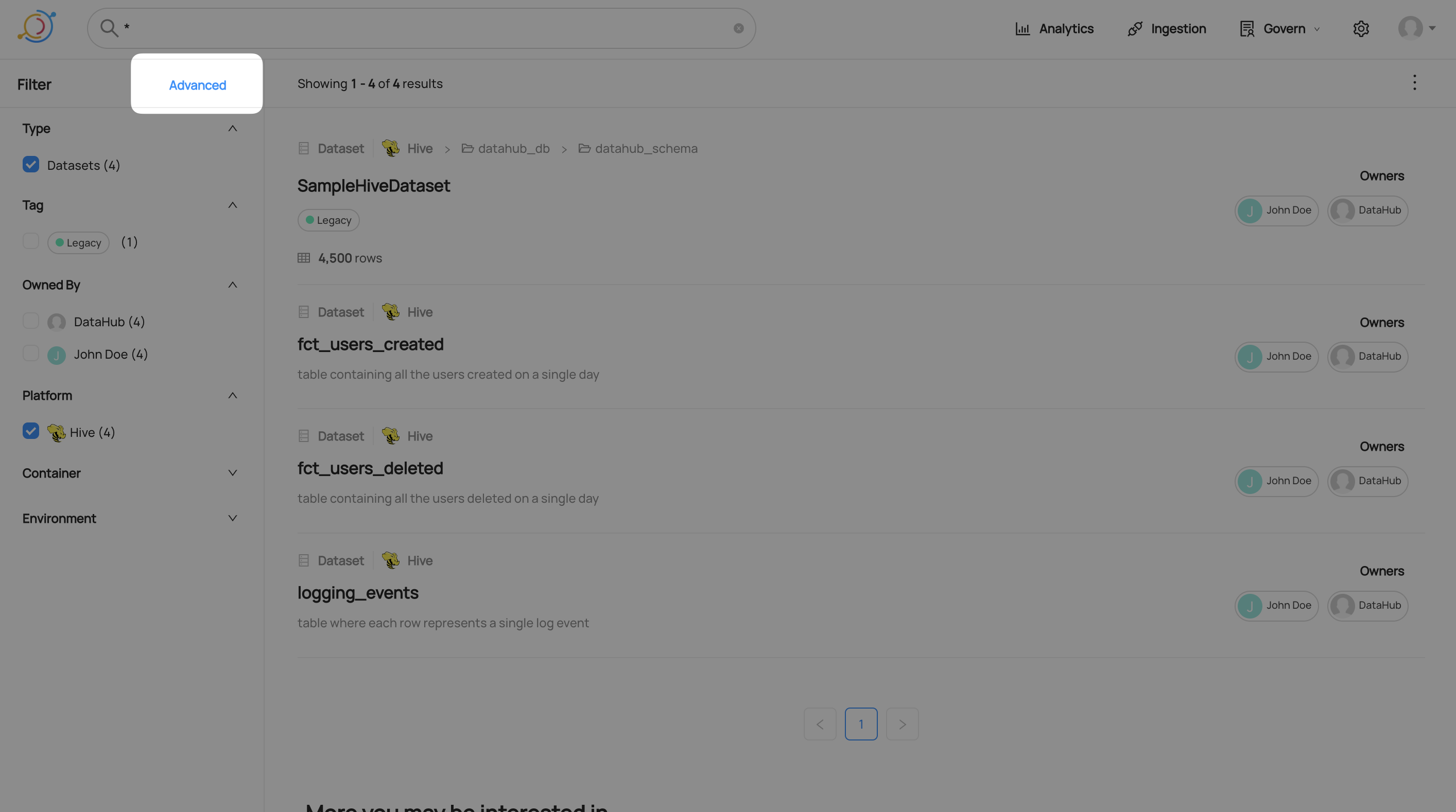
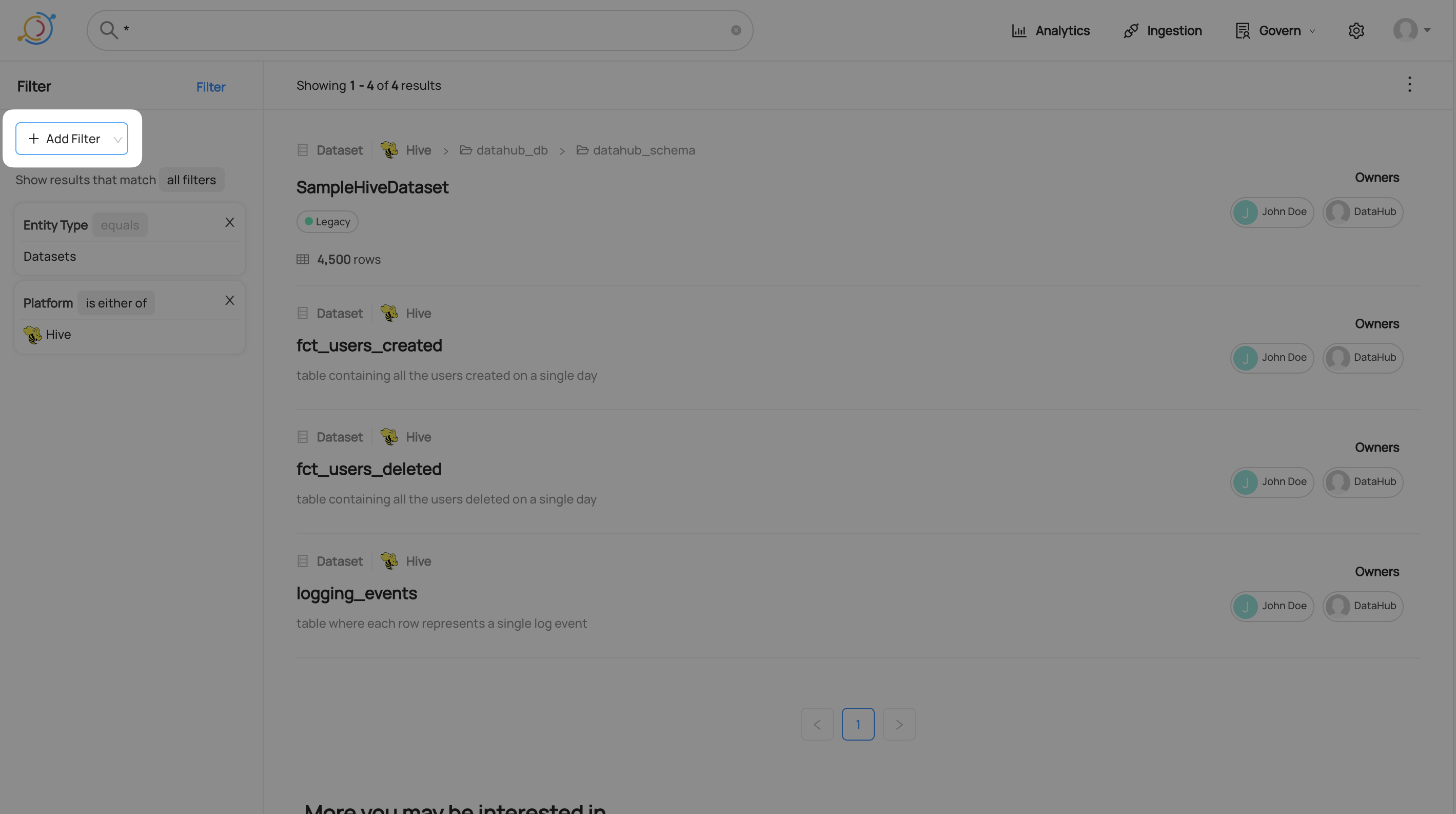
### GraphQL * [searchAcrossEntities](https://datahubproject.io/docs/graphql/queries/#searchacrossentities) * You can try out the API on the demo instance's public GraphQL interface: [here](https://demo.datahubproject.io/api/graphiql) The same GraphQL API that powers the Search UI can be used for integrations and programmatic use-cases. ``` # Example query { searchAcrossEntities( input: {types: [], query: "*", start: 0, count: 10, filters: [{field: "fieldTags", value: "urn:li:tag:Dimension"}]} ) { start count total searchResults { entity { type ... on Dataset { urn type platform { name } name } } } } } ``` ### DataHub Blog * [Using DataHub for Search & Discovery](https://blog.datahubproject.io/using-datahub-for-search-discovery-fa309089be22) ## FAQ and Troubleshooting **How are the results ordered?** The order of the search results is based on the weight what Datahub gives them based on our search algorithm. The current algorithm in OSS DataHub is based on a text-match score from Elastic Search. **Where to find more information?** The sample queries here are non exhaustive. [The link here](https://demo.datahubproject.io/tag/urn:li:tag:Searchable) shows the current list of indexed fields for each entity inside Datahub. Click on the fields inside each entity and see which field has the tag ```Searchable```. However, it does not tell you the specific attribute name to use for specialized searches. One way to do so is to inspect the ElasticSearch indices, for example: `curl http://localhost:9200/_cat/indices` returns all the ES indices in the ElasticSearch container. ``` yellow open chartindex_v2_1643510690325 bQO_RSiCSUiKJYsmJClsew 1 1 2 0 8.5kb 8.5kb yellow open mlmodelgroupindex_v2_1643510678529 OjIy0wb7RyKqLz3uTENRHQ 1 1 0 0 208b 208b yellow open dataprocessindex_v2_1643510676831 2w-IHpuiTUCs6e6gumpYHA 1 1 0 0 208b 208b yellow open corpgroupindex_v2_1643510673894 O7myCFlqQWKNtgsldzBS6g 1 1 3 0 16.8kb 16.8kb yellow open corpuserindex_v2_1643510672335 0rIe_uIQTjme5Wy61MFbaw 1 1 6 2 32.4kb 32.4kb yellow open datasetindex_v2_1643510688970 bjBfUEswSoSqPi3BP4iqjw 1 1 15 0 29.2kb 29.2kb yellow open dataflowindex_v2_1643510681607 N8CMlRFvQ42rnYMVDaQJ2g 1 1 1 0 10.2kb 10.2kb yellow open dataset_datasetusagestatisticsaspect_v1_1643510694706 kdqvqMYLRWq1oZt1pcAsXQ 1 1 4 0 8.9kb 8.9kb yellow open .ds-datahub_usage_event-000003 YMVcU8sHTFilUwyI4CWJJg 1 1 186 0 203.9kb 203.9kb yellow open datajob_datahubingestioncheckpointaspect_v1 nTXJf7C1Q3GoaIJ71gONxw 1 1 0 0 208b 208b yellow open .ds-datahub_usage_event-000004 XRFwisRPSJuSr6UVmmsCsg 1 1 196 0 165.5kb 165.5kb yellow open .ds-datahub_usage_event-000005 d0O6l5wIRLOyG6iIfAISGw 1 1 77 0 108.1kb 108.1kb yellow open dataplatformindex_v2_1643510671426 _4SIIhfAT8yq_WROufunXA 1 1 0 0 208b 208b yellow open mlmodeldeploymentindex_v2_1643510670629 n81eJIypSp2Qx-fpjZHgRw 1 1 0 0 208b 208b yellow open .ds-datahub_usage_event-000006 oyrWKndjQ-a8Rt1IMD9aSA 1 1 143 0 127.1kb 127.1kb yellow open mlfeaturetableindex_v2_1643510677164 iEXPt637S1OcilXpxPNYHw 1 1 5 0 8.9kb 8.9kb yellow open .ds-datahub_usage_event-000001 S9EnGj64TEW8O3sLUb9I2Q 1 1 257 0 163.9kb 163.9kb yellow open .ds-datahub_usage_event-000002 2xJyvKG_RYGwJOG9yq8pJw 1 1 44 0 155.4kb 155.4kb yellow open dataset_datasetprofileaspect_v1_1643510693373 uahwTHGRRAC7w1c2VqVy8g 1 1 31 0 18.9kb 18.9kb yellow open mlprimarykeyindex_v2_1643510687579 MUcmT8ASSASzEpLL98vrWg 1 1 7 0 9.5kb 9.5kb yellow open glossarytermindex_v2_1643510686127 cQL8Pg6uQeKfMly9GPhgFQ 1 1 3 0 10kb 10kb yellow open datajob_datahubingestionrunsummaryaspect_v1 rk22mIsDQ02-52MpWLm1DA 1 1 0 0 208b 208b yellow open mlmodelindex_v2_1643510675399 gk-WSTVjRZmkDU5ggeFSqg 1 1 1 0 10.3kb 10.3kb yellow open dashboardindex_v2_1643510691686 PQjSaGhTRqWW6zYjcqXo6Q 1 1 1 0 8.7kb 8.7kb yellow open datahubpolicyindex_v2_1643510671774 ZyTrYx3-Q1e-7dYq1kn5Gg 1 1 0 0 208b 208b yellow open datajobindex_v2_1643510682977 K-rbEyjBS6ew5uOQQS4sPw 1 1 2 0 11.3kb 11.3kb yellow open datahubretentionindex_v2 8XrQTPwRTX278mx1SrNwZA 1 1 0 0 208b 208b yellow open glossarynodeindex_v2_1643510678826 Y3_bCz0YR2KPwCrrVngDdA 1 1 1 0 7.4kb 7.4kb yellow open system_metadata_service_v1 36spEDbDTdKgVlSjE8t-Jw 1 1 387 8 63.2kb 63.2kb yellow open schemafieldindex_v2_1643510684410 tZ1gC3haTReRLmpCxirVxQ 1 1 0 0 208b 208b yellow open mlfeatureindex_v2_1643510680246 aQO5HF0mT62Znn-oIWBC8A 1 1 20 0 17.4kb 17.4kb yellow open tagindex_v2_1643510684785 PfnUdCUORY2fnF3I3W7HwA 1 1 3 1 18.6kb 18.6kb ``` The index name will vary from instance to instance. Indexed information about Datasets can be found in: `curl http://localhost:9200/datasetindex_v2_1643510688970/_search?=pretty` example information of a dataset: ``` { "_index" : "datasetindex_v2_1643510688970", "_type" : "_doc", "_id" : "urn%3Ali%3Adataset%3A%28urn%3Ali%3AdataPlatform%3Akafka%2CSampleKafkaDataset%2CPROD%29", "_score" : 1.0, "_source" : { "urn" : "urn:li:dataset:(urn:li:dataPlatform:kafka,SampleKafkaDataset,PROD)", "name" : "SampleKafkaDataset", "browsePaths" : [ "/prod/kafka/SampleKafkaDataset" ], "origin" : "PROD", "customProperties" : [ "prop2=pikachu", "prop1=fakeprop" ], "hasDescription" : false, "hasOwners" : true, "owners" : [ "urn:li:corpuser:jdoe", "urn:li:corpuser:datahub" ], "fieldPaths" : [ "[version=2.0].[type=boolean].field_foo_2", "[version=2.0].[type=boolean].field_bar", "[version=2.0].[key=True].[type=int].id" ], "fieldGlossaryTerms" : [ ], "fieldDescriptions" : [ "Foo field description", "Bar field description", "Id specifying which partition the message should go to" ], "fieldTags" : [ "urn:li:tag:NeedsDocumentation" ], "platform" : "urn:li:dataPlatform:kafka" } }, ``` *Need more help? Join the conversation in [Slack](http://slack.datahubproject.io)!* ### Related Features * [Metadata ingestion framework](../../metadata-ingestion/README.md)