import glob
import html
import json
import logging
import os
import re
import sys
import textwrap
from importlib.metadata import metadata, requires
from typing import Any, Dict, Iterable, List, Optional
import click
from pydantic import BaseModel, Field
from datahub.configuration.common import ConfigModel
from datahub.ingestion.api.decorators import (
CapabilitySetting,
SourceCapability,
SupportStatus,
)
from datahub.ingestion.source.source_registry import source_registry
from datahub.metadata.schema_classes import SchemaFieldClass
logger = logging.getLogger(__name__)
DEFAULT_VALUE_MAX_LENGTH = 50
DEFAULT_VALUE_TRUNCATION_MESSAGE = "..."
def _truncate_default_value(value: str) -> str:
if len(value) > DEFAULT_VALUE_MAX_LENGTH:
return value[:DEFAULT_VALUE_MAX_LENGTH] + DEFAULT_VALUE_TRUNCATION_MESSAGE
return value
def _format_path_component(path: str) -> str:
"""
Given a path like 'a.b.c', adds css tags to the components.
"""
path_components = path.rsplit(".", maxsplit=1)
if len(path_components) == 1:
return f'{path_components[0]}'
return (
f'{path_components[0]}.'
f'{path_components[1]}'
)
def _format_type_name(type_name: str) -> str:
return f'{type_name}'
def _format_default_line(default_value: str, has_desc_above: bool) -> str:
default_value = _truncate_default_value(default_value)
escaped_value = (
html.escape(default_value)
# Replace curly braces to avoid JSX issues.
.replace("{", "{")
.replace("}", "}")
# We also need to replace markdown special characters.
.replace("*", "*")
.replace("_", "_")
.replace("[", "[")
.replace("]", "]")
.replace("|", "|")
.replace("`", "`")
)
value_elem = f'{escaped_value}'
return f'Default: {value_elem}
'
class FieldRow(BaseModel):
path: str
parent: Optional[str]
type_name: str
required: bool
has_default: bool
default: str
description: str
inner_fields: List["FieldRow"] = Field(default_factory=list)
discriminated_type: Optional[str] = None
class Component(BaseModel):
type: str
field_name: Optional[str]
# matches any [...] style section inside a field path
_V2_FIELD_PATH_TOKEN_MATCHER = r"\[[\w.]*[=]*[\w\(\-\ \_\).]*\][\.]*"
# matches a .?[...] style section inside a field path anchored to the beginning
_V2_FIELD_PATH_TOKEN_MATCHER_PREFIX = rf"^[\.]*{_V2_FIELD_PATH_TOKEN_MATCHER}"
_V2_FIELD_PATH_FIELD_NAME_MATCHER = r"^\w+"
@staticmethod
def map_field_path_to_components(field_path: str) -> List[Component]:
m = re.match(FieldRow._V2_FIELD_PATH_TOKEN_MATCHER_PREFIX, field_path)
v = re.match(FieldRow._V2_FIELD_PATH_FIELD_NAME_MATCHER, field_path)
components: List[FieldRow.Component] = []
while m or v:
token = m.group() if m else v.group() # type: ignore
if v:
if components:
if components[-1].field_name is None:
components[-1].field_name = token
else:
components.append(
FieldRow.Component(type="non_map_type", field_name=token)
)
else:
components.append(
FieldRow.Component(type="non_map_type", field_name=token)
)
if m:
if token.startswith("[version="):
pass
elif "[type=" in token:
type_match = re.match(r"[\.]*\[type=(.*)\]", token)
if type_match:
type_string = type_match.group(1)
if components and components[-1].type == "map":
if components[-1].field_name is None:
pass
else:
new_component = FieldRow.Component(
type="map_key", field_name="`key`"
)
components.append(new_component)
new_component = FieldRow.Component(
type=type_string, field_name=None
)
components.append(new_component)
if type_string == "map":
new_component = FieldRow.Component(
type=type_string, field_name=None
)
components.append(new_component)
field_path = field_path[m.span()[1] :] if m else field_path[v.span()[1] :] # type: ignore
m = re.match(FieldRow._V2_FIELD_PATH_TOKEN_MATCHER_PREFIX, field_path)
v = re.match(FieldRow._V2_FIELD_PATH_FIELD_NAME_MATCHER, field_path)
return components
@staticmethod
def field_path_to_components(field_path: str) -> List[str]:
"""
Inverts the field_path v2 format to get the canonical field path
[version=2.0].[type=x].foo.[type=string(format=uri)].bar => ["foo","bar"]
"""
if "type=map" not in field_path:
return re.sub(FieldRow._V2_FIELD_PATH_TOKEN_MATCHER, "", field_path).split(
"."
)
else:
# fields with maps in them need special handling to insert the `key` fragment
return [
c.field_name
for c in FieldRow.map_field_path_to_components(field_path)
if c.field_name
]
@classmethod
def from_schema_field(cls, schema_field: SchemaFieldClass) -> "FieldRow":
path_components = FieldRow.field_path_to_components(schema_field.fieldPath)
parent = path_components[-2] if len(path_components) >= 2 else None
if parent == "`key`":
# the real parent node is one index above
parent = path_components[-3]
json_props = (
json.loads(schema_field.jsonProps) if schema_field.jsonProps else {}
)
required = json_props.get("required", True)
has_default = "default" in json_props
default_value = str(json_props.get("default"))
field_path = ".".join(path_components)
return FieldRow(
path=field_path,
parent=parent,
type_name=str(schema_field.nativeDataType),
required=required,
has_default=has_default,
default=default_value,
description=schema_field.description,
inner_fields=[],
discriminated_type=schema_field.nativeDataType,
)
def get_checkbox(self) -> str:
if self.required and not self.has_default:
# Using a non-breaking space to prevent the checkbox from being
# broken into a new line.
if not self.parent: # None and empty string both count
return ' ✅'
else:
return f' ❓'
else:
return ""
def to_md_line(self) -> str:
if self.inner_fields:
if len(self.inner_fields) == 1:
type_name = self.inner_fields[0].type_name or self.type_name
else:
# To deal with unions that have essentially the same simple field path,
# we combine the type names into a single string.
type_name = "One of " + ", ".join(
[x.type_name for x in self.inner_fields if x.discriminated_type]
)
else:
type_name = self.type_name
description = self.description.strip()
description = self.description.replace(
"\n", "
"
) # descriptions with newlines in them break markdown rendering
md_line = (
f'| {_format_path_component(self.path)}'
f"{self.get_checkbox()}
"
f' {_format_type_name(type_name)}
'
f"| {description} "
f"{_format_default_line(self.default, bool(description)) if self.has_default else ''} |\n"
)
return md_line
class FieldHeader(FieldRow):
def to_md_line(self) -> str:
return "\n".join(
[
"| Field | Description |",
"|:--- |:--- |",
"",
]
)
def __init__(self):
pass
def get_prefixed_name(field_prefix: Optional[str], field_name: Optional[str]) -> str:
assert (
field_prefix or field_name
), "One of field_prefix or field_name should be present"
return (
f"{field_prefix}.{field_name}" # type: ignore
if field_prefix and field_name
else field_name
if not field_prefix
else field_prefix
)
def custom_comparator(path: str) -> str:
"""
Projects a string onto a separate space
Low_prio string will start with Z else start with A
Number of field paths will add the second set of letters: 00 - 99
"""
opt1 = path
prio_value = priority_value(opt1)
projection = f"{prio_value}"
projection = f"{projection}{opt1}"
return projection
class FieldTree:
"""
A helper class that re-constructs the tree hierarchy of schema fields
to help sort fields by importance while keeping nesting intact
"""
def __init__(self, field: Optional[FieldRow] = None):
self.field = field
self.fields: Dict[str, "FieldTree"] = {}
def add_field(self, row: FieldRow, path: Optional[str] = None) -> "FieldTree":
# logger.warn(f"Add field: path:{path}, row:{row}")
if self.field and self.field.path == row.path:
# we have an incoming field with the same path as us, this is probably a union variant
# attach to existing field
self.field.inner_fields.append(row)
else:
path = path if path is not None else row.path
top_level_field = path.split(".")[0]
if top_level_field in self.fields:
self.fields[top_level_field].add_field(
row, ".".join(path.split(".")[1:])
)
else:
self.fields[top_level_field] = FieldTree(field=row)
# logger.warn(f"{self}")
return self
def sort(self):
# Required fields before optionals
required_fields = {
k: v for k, v in self.fields.items() if v.field and v.field.required
}
optional_fields = {
k: v for k, v in self.fields.items() if v.field and not v.field.required
}
self.sorted_fields = []
for field_map in [required_fields, optional_fields]:
# Top-level fields before fields with nesting
self.sorted_fields.extend(
sorted(
[f for f, val in field_map.items() if val.fields == {}],
key=custom_comparator,
)
)
self.sorted_fields.extend(
sorted(
[f for f, val in field_map.items() if val.fields != {}],
key=custom_comparator,
)
)
for field_tree in self.fields.values():
field_tree.sort()
def get_fields(self) -> Iterable[FieldRow]:
if self.field:
yield self.field
for key in self.sorted_fields:
yield from self.fields[key].get_fields()
def __repr__(self) -> str:
result = {}
if self.field:
result["_self"] = json.loads(json.dumps(self.field.dict()))
for f in self.fields:
result[f] = json.loads(str(self.fields[f]))
return json.dumps(result, indent=2)
def priority_value(path: str) -> str:
# A map of low value tokens to their relative importance
low_value_token_map = {"env": "X", "profiling": "Y", "stateful_ingestion": "Z"}
tokens = path.split(".")
for low_value_token in low_value_token_map:
if low_value_token in tokens:
return low_value_token_map[low_value_token]
# everything else high-prio
return "A"
def gen_md_table_from_struct(schema_dict: Dict[str, Any]) -> List[str]:
from datahub.ingestion.extractor.json_schema_util import JsonSchemaTranslator
# we don't want default field values to be injected into the description of the field
JsonSchemaTranslator._INJECT_DEFAULTS_INTO_DESCRIPTION = False
schema_fields = list(JsonSchemaTranslator.get_fields_from_schema(schema_dict))
result: List[str] = [FieldHeader().to_md_line()]
field_tree = FieldTree(field=None)
for field in schema_fields:
row: FieldRow = FieldRow.from_schema_field(field)
field_tree.add_field(row)
field_tree.sort()
for row in field_tree.get_fields():
result.append(row.to_md_line())
# Wrap with a .config-table div.
result = ["\n\n\n", *result, "\n
\n"]
return result
def get_snippet(long_string: str, max_length: int = 100) -> str:
snippet = ""
if len(long_string) > max_length:
snippet = long_string[:max_length].strip() + "... "
else:
snippet = long_string.strip()
snippet = snippet.replace("\n", " ")
snippet = snippet.strip() + " "
return snippet
def get_support_status_badge(support_status: SupportStatus) -> str:
if support_status == SupportStatus.CERTIFIED:
return ""
if support_status == SupportStatus.INCUBATING:
return ""
if support_status == SupportStatus.TESTING:
return ""
return ""
def get_capability_supported_badge(supported: bool) -> str:
return "✅" if supported else "❌"
def get_capability_text(src_capability: SourceCapability) -> str:
"""
Returns markdown format cell text for a capability, hyperlinked to capability feature page if known
"""
capability_docs_mapping: Dict[SourceCapability, str] = {
SourceCapability.DELETION_DETECTION: "../../../../metadata-ingestion/docs/dev_guides/stateful.md#stale-entity-removal",
SourceCapability.DOMAINS: "../../../domains.md",
SourceCapability.PLATFORM_INSTANCE: "../../../platform-instances.md",
SourceCapability.DATA_PROFILING: "../../../../metadata-ingestion/docs/dev_guides/sql_profiles.md",
SourceCapability.CLASSIFICATION: "../../../../metadata-ingestion/docs/dev_guides/classification.md",
}
capability_doc = capability_docs_mapping.get(src_capability)
return (
src_capability.value
if not capability_doc
else f"[{src_capability.value}]({capability_doc})"
)
def create_or_update(
something: Dict[Any, Any], path: List[str], value: Any
) -> Dict[Any, Any]:
dict_under_operation = something
for p in path[:-1]:
if p not in dict_under_operation:
dict_under_operation[p] = {}
dict_under_operation = dict_under_operation[p]
dict_under_operation[path[-1]] = value
return something
def does_extra_exist(extra_name: str) -> bool:
for key, value in metadata("acryl-datahub").items():
if key == "Provides-Extra" and value == extra_name:
return True
return False
def get_additional_deps_for_extra(extra_name: str) -> List[str]:
all_requirements = requires("acryl-datahub") or []
# filter for base dependencies
base_deps = set([x.split(";")[0] for x in all_requirements if "extra ==" not in x])
# filter for dependencies for this extra
extra_deps = set(
[x.split(";")[0] for x in all_requirements if f"extra == '{extra_name}'" in x]
)
# calculate additional deps that this extra adds
delta_deps = extra_deps - base_deps
return list(delta_deps)
def relocate_path(orig_path: str, relative_path: str, relocated_path: str) -> str:
newPath = os.path.join(os.path.dirname(orig_path), relative_path)
assert os.path.exists(newPath)
newRelativePath = os.path.relpath(newPath, os.path.dirname(relocated_path))
return newRelativePath
def rewrite_markdown(file_contents: str, path: str, relocated_path: str) -> str:
def new_url(original_url: str, file_path: str) -> str:
if original_url.startswith(("http://", "https://", "#")):
return original_url
import pathlib
file_ext = pathlib.Path(original_url).suffix
if file_ext.startswith(".md"):
return original_url
elif file_ext in [".png", ".svg", ".gif", ".pdf"]:
new_url = relocate_path(path, original_url, relocated_path)
return new_url
return original_url
# Look for the [text](url) syntax. Note that this will also capture images.
#
# We do a little bit of parenthesis matching here to account for parens in URLs.
# See https://stackoverflow.com/a/17759264 for explanation of the second capture group.
new_content = re.sub(
r"\[(.*?)\]\(((?:[^)(]+|\((?:[^)(]+|\([^)(]*\))*\))*)\)",
lambda x: f"[{x.group(1)}]({new_url(x.group(2).strip(),path)})", # type: ignore
file_contents,
)
new_content = re.sub(
# Also look for the [text]: url syntax.
r"^\[(.+?)\]\s*:\s*(.+?)\s*$",
lambda x: f"[{x.group(1)}]: {new_url(x.group(2), path)}",
new_content,
)
return new_content
@click.command()
@click.option("--out-dir", type=str, required=True)
@click.option("--extra-docs", type=str, required=False)
@click.option("--source", type=str, required=False)
def generate(
out_dir: str, extra_docs: Optional[str] = None, source: Optional[str] = None
) -> None: # noqa: C901
source_documentation: Dict[str, Any] = {}
metrics = {}
metrics["source_platforms"] = {"discovered": 0, "generated": 0, "warnings": []}
metrics["plugins"] = {"discovered": 0, "generated": 0, "failed": 0}
if extra_docs:
for path in glob.glob(f"{extra_docs}/**/*[.md|.yaml|.yml]", recursive=True):
m = re.search("/docs/sources/(.*)/(.*).md", path)
if m:
platform_name = m.group(1).lower()
file_name = m.group(2)
destination_md: str = (
f"../docs/generated/ingestion/sources/{platform_name}.md"
)
with open(path, "r") as doc_file:
file_contents = doc_file.read()
final_markdown = rewrite_markdown(
file_contents, path, destination_md
)
if file_name == "README":
# README goes as platform level docs
# all other docs are assumed to be plugin level
create_or_update(
source_documentation,
[platform_name, "custom_docs"],
final_markdown,
)
else:
if "_" in file_name:
plugin_doc_parts = file_name.split("_")
if len(plugin_doc_parts) != 2 or plugin_doc_parts[
1
] not in ["pre", "post"]:
raise Exception(
f"{file_name} needs to be of the form _pre.md or _post.md"
)
docs_key_name = f"custom_docs_{plugin_doc_parts[1]}"
create_or_update(
source_documentation,
[
platform_name,
"plugins",
plugin_doc_parts[0],
docs_key_name,
],
final_markdown,
)
else:
create_or_update(
source_documentation,
[
platform_name,
"plugins",
file_name,
"custom_docs_post",
],
final_markdown,
)
else:
yml_match = re.search("/docs/sources/(.*)/(.*)_recipe.yml", path)
if yml_match:
platform_name = yml_match.group(1).lower()
plugin_name = yml_match.group(2)
with open(path, "r") as doc_file:
file_contents = doc_file.read()
create_or_update(
source_documentation,
[platform_name, "plugins", plugin_name, "recipe"],
file_contents,
)
for plugin_name in sorted(source_registry.mapping.keys()):
if source and source != plugin_name:
continue
metrics["plugins"]["discovered"] = metrics["plugins"]["discovered"] + 1 # type: ignore
# We want to attempt to load all plugins before printing a summary.
source_type = None
try:
# output = subprocess.check_output(
# ["/bin/bash", "-c", f"pip install -e '.[{key}]'"]
# )
class_or_exception = source_registry._ensure_not_lazy(plugin_name)
if isinstance(class_or_exception, Exception):
raise class_or_exception
logger.debug(f"Processing {plugin_name}")
source_type = source_registry.get(plugin_name)
logger.debug(f"Source class is {source_type}")
extra_plugin = plugin_name if does_extra_exist(plugin_name) else None
extra_deps = (
get_additional_deps_for_extra(extra_plugin) if extra_plugin else []
)
except Exception as e:
logger.warning(
f"Failed to process {plugin_name} due to exception {e}", exc_info=e
)
metrics["plugins"]["failed"] = metrics["plugins"].get("failed", 0) + 1 # type: ignore
if source_type and hasattr(source_type, "get_config_class"):
try:
source_config_class: ConfigModel = source_type.get_config_class()
support_status = SupportStatus.UNKNOWN
capabilities = []
if hasattr(source_type, "__doc__"):
source_doc = textwrap.dedent(source_type.__doc__ or "")
if hasattr(source_type, "get_platform_name"):
platform_name = source_type.get_platform_name()
else:
platform_name = (
plugin_name.title()
) # we like platform names to be human readable
if hasattr(source_type, "get_platform_id"):
platform_id = source_type.get_platform_id()
if hasattr(source_type, "get_platform_doc_order"):
platform_doc_order = source_type.get_platform_doc_order()
create_or_update(
source_documentation,
[platform_id, "plugins", plugin_name, "doc_order"],
platform_doc_order,
)
source_documentation[platform_id] = (
source_documentation.get(platform_id) or {}
)
create_or_update(
source_documentation,
[platform_id, "plugins", plugin_name, "classname"],
".".join([source_type.__module__, source_type.__name__]),
)
plugin_file_name = "src/" + "/".join(source_type.__module__.split("."))
if os.path.exists(plugin_file_name) and os.path.isdir(plugin_file_name):
plugin_file_name = plugin_file_name + "/__init__.py"
else:
plugin_file_name = plugin_file_name + ".py"
if os.path.exists(plugin_file_name):
create_or_update(
source_documentation,
[platform_id, "plugins", plugin_name, "filename"],
plugin_file_name,
)
else:
logger.info(
f"Failed to locate filename for {plugin_name}. Guessed {plugin_file_name}"
)
if hasattr(source_type, "get_support_status"):
support_status = source_type.get_support_status()
if hasattr(source_type, "get_capabilities"):
capabilities = list(source_type.get_capabilities())
capabilities.sort(key=lambda x: x.capability.value)
create_or_update(
source_documentation,
[platform_id, "plugins", plugin_name, "capabilities"],
capabilities,
)
create_or_update(
source_documentation, [platform_id, "name"], platform_name
)
create_or_update(
source_documentation,
[platform_id, "plugins", plugin_name, "extra_deps"],
extra_deps,
)
config_dir = f"{out_dir}/config_schemas"
os.makedirs(config_dir, exist_ok=True)
with open(f"{config_dir}/{plugin_name}_config.json", "w") as f:
f.write(source_config_class.schema_json(indent=2))
create_or_update(
source_documentation,
[platform_id, "plugins", plugin_name, "config_schema"],
source_config_class.schema_json(indent=2) or "",
)
table_md = gen_md_table_from_struct(source_config_class.schema())
create_or_update(
source_documentation,
[platform_id, "plugins", plugin_name, "source_doc"],
source_doc or "",
)
create_or_update(
source_documentation,
[platform_id, "plugins", plugin_name, "config"],
table_md,
)
create_or_update(
source_documentation,
[platform_id, "plugins", plugin_name, "support_status"],
support_status,
)
except Exception as e:
raise e
sources_dir = f"{out_dir}/sources"
os.makedirs(sources_dir, exist_ok=True)
i = 0
for platform_id, platform_docs in sorted(
source_documentation.items(),
key=lambda x: (x[1]["name"].casefold(), x[1]["name"])
if "name" in x[1]
else (x[0].casefold(), x[0]),
):
if source and platform_id != source:
continue
metrics["source_platforms"]["discovered"] = (
metrics["source_platforms"]["discovered"] + 1 # type: ignore
)
platform_doc_file = f"{sources_dir}/{platform_id}.md"
if "name" not in platform_docs:
# We seem to have discovered written docs that corresponds to a platform, but haven't found linkage to it from the source classes
warning_msg = f"Failed to find source classes for platform {platform_id}. Did you remember to annotate your source class with @platform_name({platform_id})?"
logger.error(warning_msg)
metrics["source_platforms"]["warnings"].append(warning_msg) # type: ignore
continue
with open(platform_doc_file, "w") as f:
i += 1
f.write(f"---\nsidebar_position: {i}\n---\n\n")
f.write(
"import Tabs from '@theme/Tabs';\nimport TabItem from '@theme/TabItem';\n\n"
)
f.write(f"# {platform_docs['name']}\n")
if len(platform_docs["plugins"].keys()) > 1:
# More than one plugin used to provide integration with this platform
f.write(
f"There are {len(platform_docs['plugins'].keys())} sources that provide integration with {platform_docs['name']}\n"
)
f.write("\n")
f.write("\n")
f.write("")
for col_header in ["Source Module", "Documentation"]:
f.write(f"| {col_header} | ")
f.write("
")
# f.write("| Source Module | Documentation |\n")
# f.write("| ------ | ---- |\n")
for plugin, plugin_docs in sorted(
platform_docs["plugins"].items(),
key=lambda x: str(x[1].get("doc_order"))
if x[1].get("doc_order")
else x[0],
):
f.write("\n")
f.write(f"| \n\n`{plugin}`\n\n | \n")
f.write(
f"\n\n\n{platform_docs['plugins'][plugin].get('source_doc') or ''} [Read more...](#module-{plugin})\n\n\n | \n"
)
f.write("
\n")
# f.write(
# f"| `{plugin}` | {get_snippet(platform_docs['plugins'][plugin]['source_doc'])}[Read more...](#module-{plugin}) |\n"
# )
f.write("
\n\n")
# insert platform level custom docs before plugin section
f.write(platform_docs.get("custom_docs") or "")
# all_plugins = platform_docs["plugins"].keys()
for plugin, plugin_docs in sorted(
platform_docs["plugins"].items(),
key=lambda x: str(x[1].get("doc_order"))
if x[1].get("doc_order")
else x[0],
):
if len(platform_docs["plugins"].keys()) > 1:
# We only need to show this if there are multiple modules.
f.write(f"\n\n## Module `{plugin}`\n")
if "support_status" in plugin_docs:
f.write(
get_support_status_badge(plugin_docs["support_status"]) + "\n\n"
)
if "capabilities" in plugin_docs and len(plugin_docs["capabilities"]):
f.write("\n### Important Capabilities\n")
f.write("| Capability | Status | Notes |\n")
f.write("| ---------- | ------ | ----- |\n")
plugin_capabilities: List[CapabilitySetting] = plugin_docs[
"capabilities"
]
for cap_setting in plugin_capabilities:
f.write(
f"| {get_capability_text(cap_setting.capability)} | {get_capability_supported_badge(cap_setting.supported)} | {cap_setting.description} |\n"
)
f.write("\n")
f.write(f"{plugin_docs.get('source_doc') or ''}\n")
# Insert custom pre section
f.write(plugin_docs.get("custom_docs_pre", ""))
f.write("\n### CLI based Ingestion\n")
if "extra_deps" in plugin_docs:
f.write("\n#### Install the Plugin\n")
if plugin_docs["extra_deps"] != []:
f.write("```shell\n")
f.write(f"pip install 'acryl-datahub[{plugin}]'\n")
f.write("```\n")
else:
f.write(
f"The `{plugin}` source works out of the box with `acryl-datahub`.\n"
)
if "recipe" in plugin_docs:
f.write("\n### Starter Recipe\n")
f.write(
"Check out the following recipe to get started with ingestion! See [below](#config-details) for full configuration options.\n\n\n"
)
f.write(
"For general pointers on writing and running a recipe, see our [main recipe guide](../../../../metadata-ingestion/README.md#recipes).\n"
)
f.write("```yaml\n")
f.write(plugin_docs["recipe"])
f.write("\n```\n")
if "config" in plugin_docs:
f.write("\n### Config Details\n")
f.write(
"""
\n\n"""
)
f.write(
"Note that a `.` is used to denote nested fields in the YAML recipe.\n\n"
)
# f.write(
# "\n\nView All Configuration Options
\n\n"
# )
for doc in plugin_docs["config"]:
f.write(doc)
# f.write("\n \n\n")
f.write(
f"""
The [JSONSchema](https://json-schema.org/) for this configuration is inlined below.\n\n
```javascript
{plugin_docs['config_schema']}
```\n\n
\n\n"""
)
# insert custom plugin docs after config details
f.write(plugin_docs.get("custom_docs_post", ""))
if "classname" in plugin_docs:
f.write("\n### Code Coordinates\n")
f.write(f"- Class Name: `{plugin_docs['classname']}`\n")
if "filename" in plugin_docs:
f.write(
f"- Browse on [GitHub](../../../../metadata-ingestion/{plugin_docs['filename']})\n\n"
)
metrics["plugins"]["generated"] = metrics["plugins"]["generated"] + 1 # type: ignore
# Using an h2 tag to prevent this from showing up in page's TOC sidebar.
f.write("\nQuestions
\n\n")
f.write(
f"If you've got any questions on configuring ingestion for {platform_docs.get('name',platform_id)}, feel free to ping us on [our Slack](https://slack.datahubproject.io).\n"
)
metrics["source_platforms"]["generated"] = (
metrics["source_platforms"]["generated"] + 1 # type: ignore
)
print("Ingestion Documentation Generation Complete")
print("############################################")
print(json.dumps(metrics, indent=2))
print("############################################")
if metrics["plugins"].get("failed", 0) > 0: # type: ignore
sys.exit(1)
### Create Lineage doc
source_dir = "../docs/generated/lineage"
os.makedirs(source_dir, exist_ok=True)
doc_file = f"{source_dir}/lineage-feature-guide.md"
with open(doc_file, "w+") as f:
f.write("import FeatureAvailability from '@site/src/components/FeatureAvailability';\n\n")
f.write(f"# About DataHub Lineage\n\n")
f.write("\n")
f.write("""
Data Lineage is used to capture data dependencies within an organization. It allows you to track the inputs from which a data asset is derived, along with the data assets that depend on it downstream.
## Viewing Lineage
You can view lineage under **Lineage** tab or **Lineage Visualization** screen.
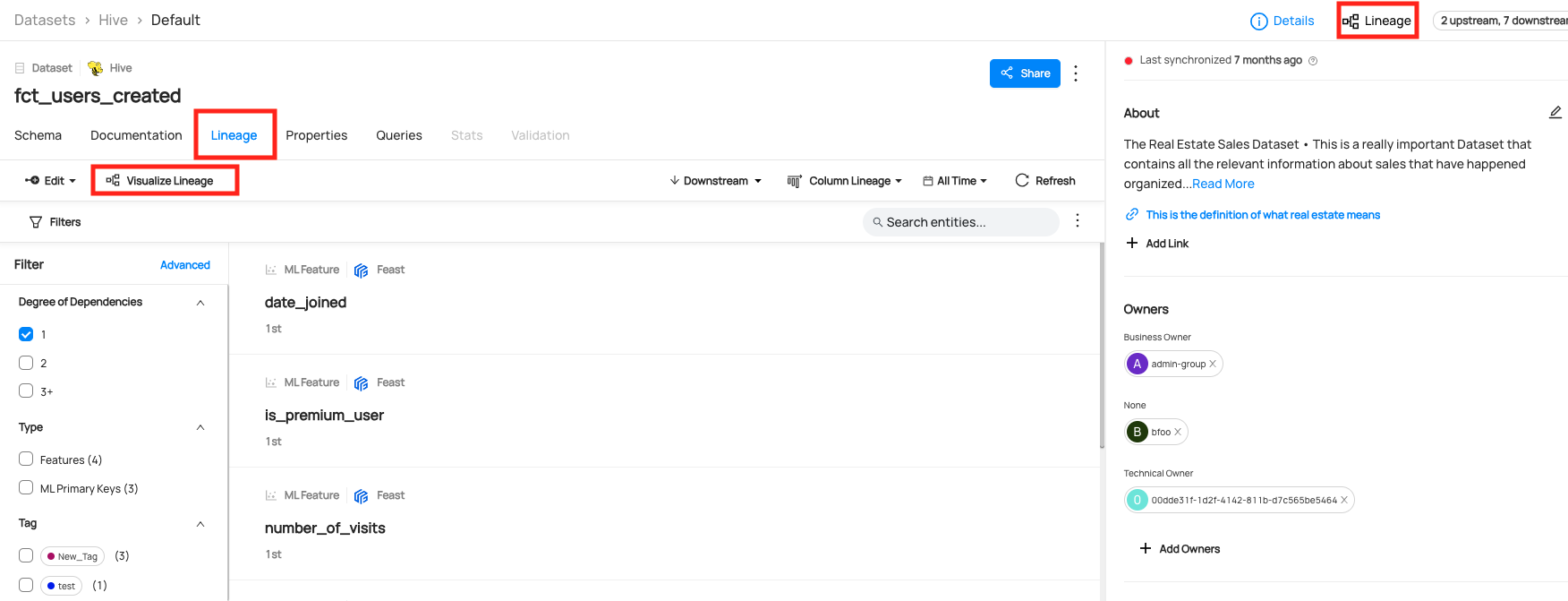
The UI shows the latest version of the lineage. The time picker can be used to filter out edges within the latest version to exclude those that were last updated outside of the time window. Selecting time windows in the patch will not show you historical lineages. It will only filter the view of the latest version of the lineage.
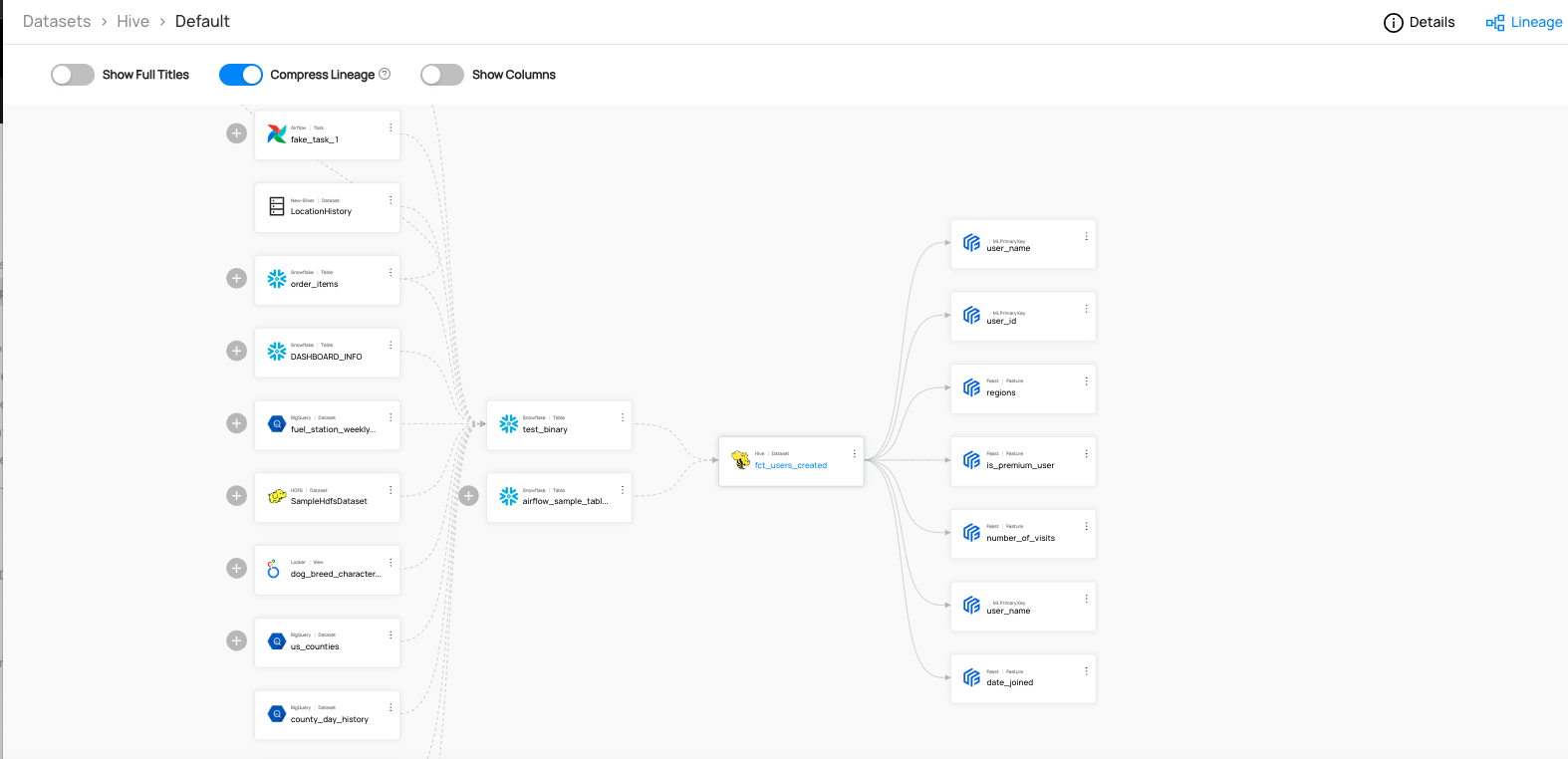
:::tip The Lineage Tab is greyed out - why can’t I click on it?
This means you have not yet ingested lineage metadata for that entity. Please ingest lineage to proceed.
:::
## Adding Lineage
### Ingestion Source
If you're using an ingestion source that supports extraction of Lineage (e.g. **Table Lineage Capability**), then lineage information can be extracted automatically.
For detailed instructions, refer to the [source documentation](https://datahubproject.io/integrations) for the source you are using.
### UI
As of `v0.9.5`, DataHub supports the manual editing of lineage between entities. Data experts are free to add or remove upstream and downstream lineage edges in both the Lineage Visualization screen as well as the Lineage tab on entity pages. Use this feature to supplement automatic lineage extraction or establish important entity relationships in sources that do not support automatic extraction. Editing lineage by hand is supported for Datasets, Charts, Dashboards, and Data Jobs.
Please refer to our [UI Guides on Lineage](../../features/feature-guides/ui-lineage.md) for more information.
:::caution Recommendation on UI-based lineage
Lineage added by hand and programmatically may conflict with one another to cause unwanted overwrites.
It is strongly recommend that lineage is edited manually in cases where lineage information is not also extracted in automated fashion, e.g. by running an ingestion source.
:::
### API
If you are not using a Lineage-support ingestion source, you can programmatically emit lineage edges between entities via API.
Please refer to [API Guides on Lineage](../../api/tutorials/lineage.md) for more information.
## Lineage Support
### Automatic Lineage Extraction Support
This is a summary of automatic lineage extraciton support in our data source. Please refer to the **Important Capabilities** table in the source documentation. Note that even if the source does not support automatic extraction, you can still add lineage manually using our API & SDKs.\n""")
f.write("\n| Source | Table-Level Lineage | Column-Level Lineage | Related Configs |\n")
f.write("| ---------- | ------ | ----- |----- |\n")
for platform_id, platform_docs in sorted(
source_documentation.items(),
key=lambda x: (x[1]["name"].casefold(), x[1]["name"])
if "name" in x[1]
else (x[0].casefold(), x[0]),
):
for plugin, plugin_docs in sorted(
platform_docs["plugins"].items(),
key=lambda x: str(x[1].get("doc_order"))
if x[1].get("doc_order")
else x[0],
):
platform_name = platform_docs['name']
if len(platform_docs["plugins"].keys()) > 1:
# We only need to show this if there are multiple modules.
platform_name = f"{platform_name} `{plugin}`"
# Initialize variables
table_level_supported = "❌"
column_level_supported = "❌"
config_names = ''
if "capabilities" in plugin_docs:
plugin_capabilities = plugin_docs["capabilities"]
for cap_setting in plugin_capabilities:
capability_text = get_capability_text(cap_setting.capability)
capability_supported = get_capability_supported_badge(cap_setting.supported)
if capability_text == "Table-Level Lineage" and capability_supported == "✅":
table_level_supported = "✅"
if capability_text == "Column-level Lineage" and capability_supported == "✅":
column_level_supported = "✅"
if not (table_level_supported == "❌" and column_level_supported == "❌"):
if "config_schema" in plugin_docs:
config_properties = json.loads(plugin_docs['config_schema']).get('properties', {})
config_names = '
'.join(
[f'- {property_name}' for property_name in config_properties if 'lineage' in property_name])
lineage_not_applicable_sources = ['azure-ad', 'csv', 'demo-data', 'dynamodb', 'iceberg', 'json-schema', 'ldap', 'openapi', 'pulsar', 'sqlalchemy' ]
if platform_id not in lineage_not_applicable_sources :
f.write(
f"| [{platform_name}](../../generated/ingestion/sources/{platform_id}.md) | {table_level_supported} | {column_level_supported} | {config_names}|\n"
)
f.write("""
### Types of Lineage Connections
Types of lineage connections supported in DataHub and the example codes are as follows.
| Connection | Examples | A.K.A |
|---------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------|
| Dataset to Dataset | - [lineage_emitter_mcpw_rest.py](../../../metadata-ingestion/examples/library/lineage_emitter_mcpw_rest.py)
- [lineage_emitter_rest.py](../../../metadata-ingestion/examples/library/lineage_emitter_rest.py)
- [lineage_emitter_kafka.py](../../../metadata-ingestion/examples/library/lineage_emitter_kafka.py)
- [lineage_emitter_dataset_finegrained.py](../../../metadata-ingestion/examples/library/lineage_emitter_dataset_finegrained.py)
- [Datahub BigQuery Lineage](https://github.com/datahub-project/datahub/blob/a1bf95307b040074c8d65ebb86b5eb177fdcd591/metadata-ingestion/src/datahub/ingestion/source/sql/bigquery.py#L229)
- [Datahub Snowflake Lineage](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/src/datahub/ingestion/source/sql/snowflake.py#L249) |
| DataJob to DataFlow | - [lineage_job_dataflow.py](../../../metadata-ingestion/examples/library/lineage_job_dataflow.py) | |
| DataJob to Dataset | - [lineage_dataset_job_dataset.py](../../../metadata-ingestion/examples/library/lineage_dataset_job_dataset.py)
| Pipeline Lineage |
| Chart to Dashboard | - [lineage_chart_dashboard.py](../../../metadata-ingestion/examples/library/lineage_chart_dashboard.py) | |
| Chart to Dataset | - [lineage_dataset_chart.py](../../../metadata-ingestion/examples/library/lineage_dataset_chart.py) | |
:::tip Our Roadmap
We're actively working on expanding lineage support for new data sources.
Visit our [Official Roadmap](https://feature-requests.datahubproject.io/roadmap) for upcoming updates!
:::
## References
- [DataHub Basics: Lineage 101](https://www.youtube.com/watch?v=rONGpsndzRw&t=1s)
- [DataHub November 2022 Town Hall](https://www.youtube.com/watch?v=BlCLhG8lGoY&t=1s) - Including Manual Lineage Demo
- [Acryl Data introduces lineage support and automated propagation of governance information for Snowflake in DataHub](https://blog.datahubproject.io/acryl-data-introduces-lineage-support-and-automated-propagation-of-governance-information-for-339c99536561)
- [Data in Context: Lineage Explorer in DataHub](https://blog.datahubproject.io/data-in-context-lineage-explorer-in-datahub-a53a9a476dc4)
- [Harnessing the Power of Data Lineage with DataHub](https://blog.datahubproject.io/harnessing-the-power-of-data-lineage-with-datahub-ad086358dec4)
- [DataHub Lineage Impact Analysis](../../act-on-metadata/impact-analysis.md)
""")
print("Lineage Documentation Generation Complete")
if __name__ == "__main__":
logger.setLevel("INFO")
generate()