mirror of
https://github.com/datahub-project/datahub.git
synced 2025-07-07 01:00:41 +00:00
307 lines
11 KiB
Markdown
307 lines
11 KiB
Markdown
### dbt meta automated mappings
|
|
|
|
dbt allows authors to define meta properties for datasets. Checkout this link to know more - [dbt meta](https://docs.getdbt.com/reference/resource-configs/meta). Our dbt source allows users to define
|
|
actions such as add a tag, term or owner. For example if a dbt model has a meta config `"has_pii": True`, we can define an action
|
|
that evaluates if the property is set to true and add, lets say, a `pii` tag.
|
|
To leverage this feature we require users to define mappings as part of the recipe. The following section describes how you can build these mappings. Listed below is a `meta_mapping` and `column_meta_mapping` section that among other things, looks for keys like `business_owner` and adds owners that are listed there.
|
|
|
|
```yaml
|
|
meta_mapping:
|
|
business_owner:
|
|
match: ".*"
|
|
operation: "add_owner"
|
|
config:
|
|
owner_type: user
|
|
owner_category: BUSINESS_OWNER
|
|
has_pii:
|
|
match: True
|
|
operation: "add_tag"
|
|
config:
|
|
tag: "has_pii_test"
|
|
int_property:
|
|
match: 1
|
|
operation: "add_tag"
|
|
config:
|
|
tag: "int_meta_property"
|
|
double_property:
|
|
match: 2.5
|
|
operation: "add_term"
|
|
config:
|
|
term: "double_meta_property"
|
|
data_governance.team_owner:
|
|
match: "Finance"
|
|
operation: "add_term"
|
|
config:
|
|
term: "Finance_test"
|
|
terms_list:
|
|
match: ".*"
|
|
operation: "add_terms"
|
|
config:
|
|
separator: ","
|
|
documentation_link:
|
|
match: "(?:https?)?\:\/\/\w*[^#]*"
|
|
operation: "add_doc_link"
|
|
config:
|
|
link: {{ $match }}
|
|
description: "Documentation Link"
|
|
column_meta_mapping:
|
|
terms_list:
|
|
match: ".*"
|
|
operation: "add_terms"
|
|
config:
|
|
separator: ","
|
|
is_sensitive:
|
|
match: True
|
|
operation: "add_tag"
|
|
config:
|
|
tag: "sensitive"
|
|
```
|
|
|
|
We support the following operations:
|
|
|
|
1. add_tag - Requires `tag` property in config.
|
|
2. add_term - Requires `term` property in config.
|
|
3. add_terms - Accepts an optional `separator` property in config.
|
|
4. add_owner - Requires `owner_type` property in config which can be either `user` or `group`. Optionally accepts the `owner_category` config property which can be set to either a [custom ownership type](../../../../docs/ownership/ownership-types.md) urn like `urn:li:ownershipType:architect` or one of `['TECHNICAL_OWNER', 'BUSINESS_OWNER', 'DATA_STEWARD', 'DATAOWNER'` (defaults to `DATAOWNER`).
|
|
|
|
- The `owner_type` property will be ignored if the owner is a fully qualified urn.
|
|
- You can use commas to specify multiple owners - e.g. `business_owner: "jane,john,urn:li:corpGroup:data-team"`.
|
|
|
|
5. add_doc_link - Requires `link` and `description` properties in config. Upon ingestion run, this will overwrite current links in the institutional knowledge section with this new link. The anchor text is defined here in the meta_mappings as `description`.
|
|
|
|
Note:
|
|
|
|
1. The dbt `meta_mapping` config works at the model level, while the `column_meta_mapping` config works at the column level. The `add_owner` operation is not supported at the column level.
|
|
2. For string meta properties we support regex matching.
|
|
|
|
With regex matching, you can also use the matched value to customize how you populate the tag, term or owner fields. Here are a few advanced examples:
|
|
|
|
#### Data Tier - Bronze, Silver, Gold
|
|
|
|
If your meta section looks like this:
|
|
|
|
```yaml
|
|
meta:
|
|
data_tier: Bronze # chosen from [Bronze,Gold,Silver]
|
|
```
|
|
|
|
and you wanted to attach a glossary term like `urn:li:glossaryTerm:Bronze` for all the models that have this value in the meta section attached to them, the following meta_mapping section would achieve that outcome:
|
|
|
|
```yaml
|
|
meta_mapping:
|
|
data_tier:
|
|
match: "Bronze|Silver|Gold"
|
|
operation: "add_term"
|
|
config:
|
|
term: "{{ $match }}"
|
|
```
|
|
|
|
to match any data_tier of Bronze, Silver or Gold and maps it to a glossary term with the same name.
|
|
|
|
#### Case Numbers - create tags
|
|
|
|
If your meta section looks like this:
|
|
|
|
```yaml
|
|
meta:
|
|
case: PLT-4678 # internal Case Number
|
|
```
|
|
|
|
and you want to generate tags that look like `case_4678` from this, you can use the following meta_mapping section:
|
|
|
|
```yaml
|
|
meta_mapping:
|
|
case:
|
|
match: "PLT-(.*)"
|
|
operation: "add_tag"
|
|
config:
|
|
tag: "case_{{ $match }}"
|
|
```
|
|
|
|
#### Stripping out leading @ sign
|
|
|
|
You can also match specific groups within the value to extract subsets of the matched value. e.g. if you have a meta section that looks like this:
|
|
|
|
```yaml
|
|
meta:
|
|
owner: "@finance-team"
|
|
business_owner: "@janet"
|
|
```
|
|
|
|
and you want to mark the finance-team as a group that owns the dataset (skipping the leading @ sign), while marking janet as an individual user (again, skipping the leading @ sign) that owns the dataset, you can use the following meta-mapping section.
|
|
|
|
```yaml
|
|
meta_mapping:
|
|
owner:
|
|
match: "^@(.*)"
|
|
operation: "add_owner"
|
|
config:
|
|
owner_type: group
|
|
business_owner:
|
|
match: "^@(?P<owner>(.*))"
|
|
operation: "add_owner"
|
|
config:
|
|
owner_type: user
|
|
owner_category: BUSINESS_OWNER
|
|
```
|
|
|
|
In the examples above, we show two ways of writing the matching regexes. In the first one, `^@(.*)` the first matching group (a.k.a. match.group(1)) is automatically inferred. In the second example, `^@(?P<owner>(.*))`, we use a named matching group (called owner, since we are matching an owner) to capture the string we want to provide to the ownership urn.
|
|
|
|
### dbt query_tag automated mappings
|
|
|
|
This works similarly as the dbt meta mapping but for the query tags
|
|
|
|
We support the below actions -
|
|
|
|
1. add_tag - Requires `tag` property in config.
|
|
|
|
The below example set as global tag the query tag `tag` key's value.
|
|
|
|
```json
|
|
"query_tag_mapping":
|
|
{
|
|
"tag":
|
|
"match": ".*"
|
|
"operation": "add_tag"
|
|
"config":
|
|
"tag": "{{ $match }}"
|
|
}
|
|
```
|
|
|
|
### Integrating with dbt test
|
|
|
|
To integrate with dbt tests, the `dbt` source needs access to the `run_results.json` file generated after a `dbt test` or `dbt build` execution. Typically, this is written to the `target` directory. A common pattern you can follow is:
|
|
|
|
1. Run `dbt build`
|
|
2. Copy the `target/run_results.json` file to a separate location. This is important, because otherwise subsequent `dbt` commands will overwrite the run results.
|
|
3. Run `dbt docs generate` to generate the `manifest.json` and `catalog.json` files
|
|
4. The dbt source makes use of the manifest, catalog, and run results file, and hence will need to be moved to a location accessible to the `dbt` source (e.g. s3 or local file system). In the ingestion recipe, the `run_results_paths` config must be set to the location of the `run_results.json` file from the `dbt build` or `dbt test` run.
|
|
|
|
The connector will produce the following things:
|
|
|
|
- Assertion definitions that are attached to the dataset (or datasets)
|
|
- Results from running the tests attached to the timeline of the dataset
|
|
|
|
:::note Missing test results?
|
|
|
|
The most common reason for missing test results is that the `run_results.json` with the test result information is getting overwritten by a subsequent `dbt` command. We recommend copying the `run_results.json` file before running other `dbt` commands.
|
|
|
|
```sh
|
|
dbt source snapshot-freshness
|
|
dbt build
|
|
cp target/run_results.json target/run_results_backup.json
|
|
dbt docs generate
|
|
cp target/run_results_backup.json target/run_results.json
|
|
```
|
|
|
|
:::
|
|
|
|
#### View of dbt tests for a dataset
|
|
|
|
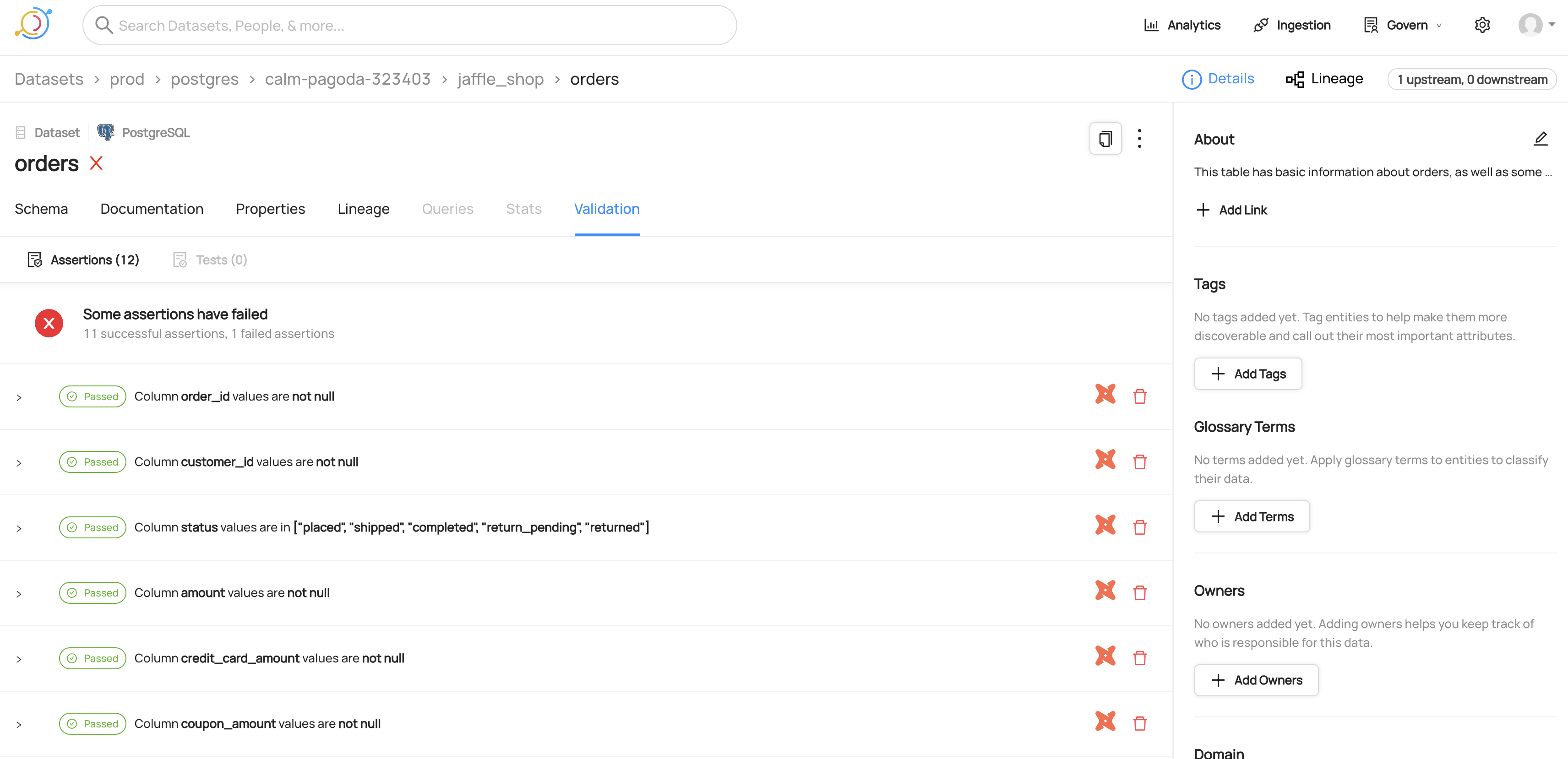
|
|
|
|
#### Viewing the SQL for a dbt test
|
|
|
|
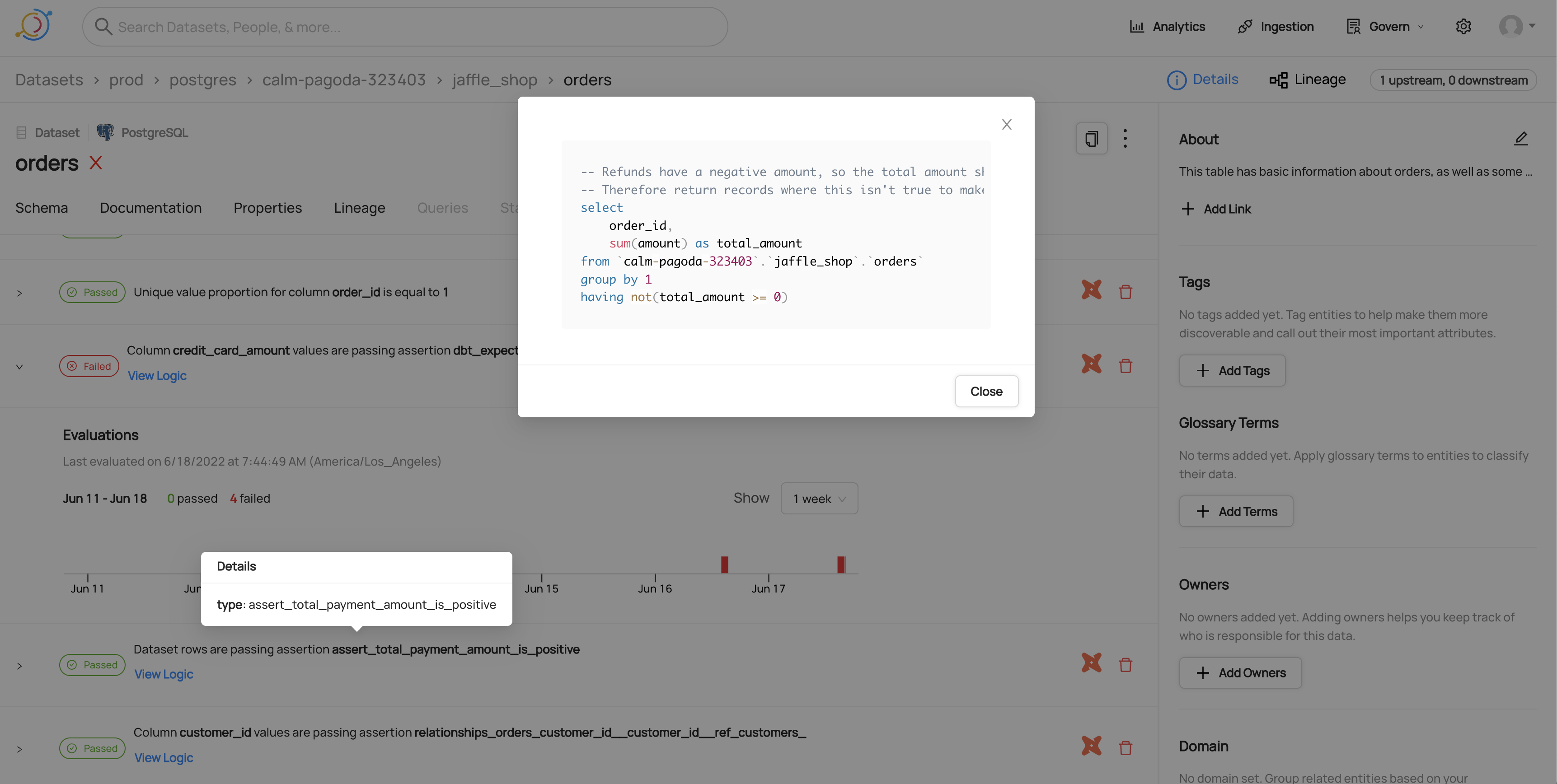
|
|
|
|
#### Viewing timeline for a failed dbt test
|
|
|
|
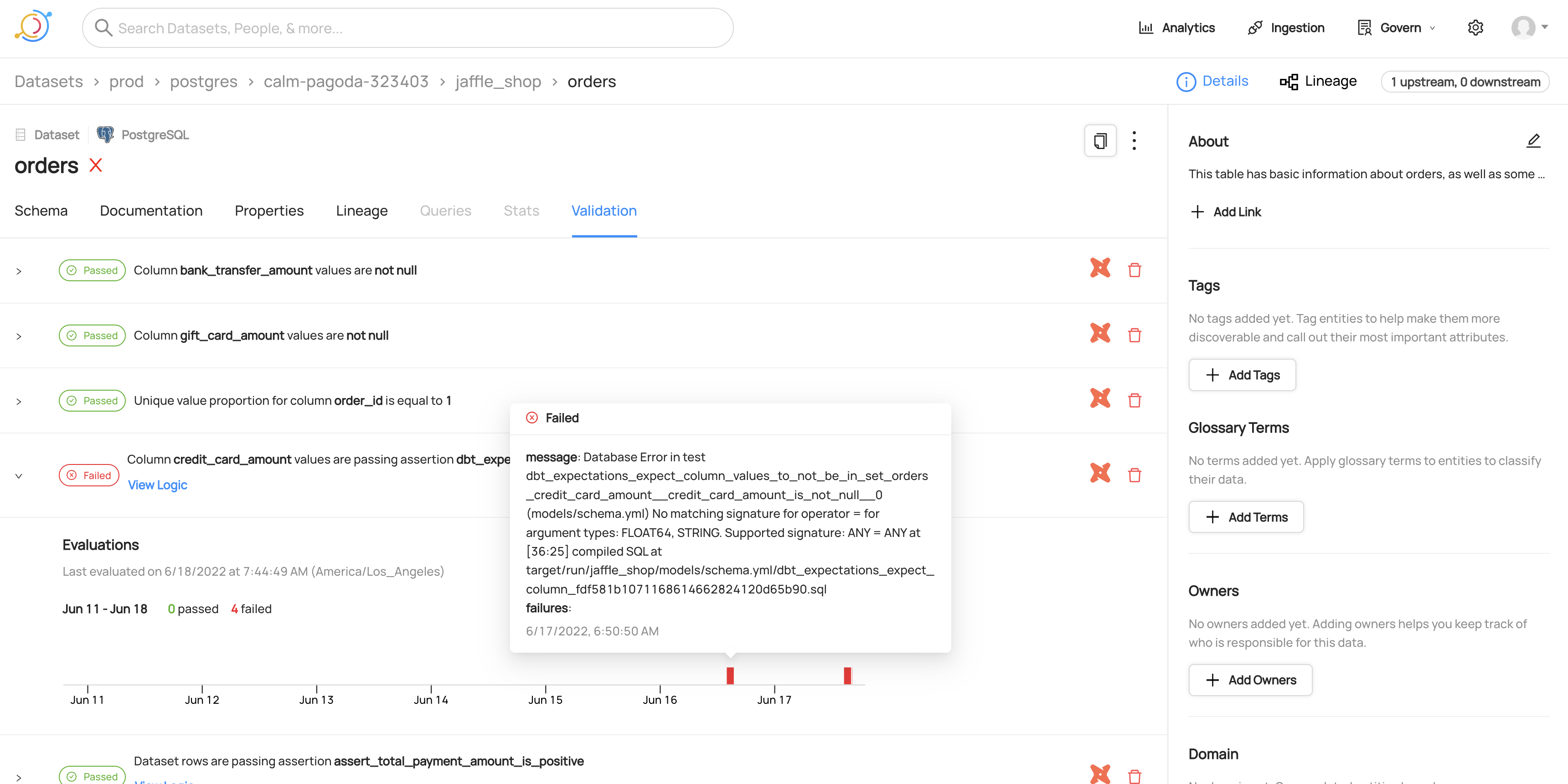
|
|
|
|
#### Separating test result emission from other metadata emission
|
|
|
|
You can segregate emission of test results from the emission of other dbt metadata using the `entities_enabled` config flag.
|
|
The following recipe shows you how to emit only test results.
|
|
|
|
```yaml
|
|
source:
|
|
type: dbt
|
|
config:
|
|
manifest_path: _path_to_manifest_json
|
|
catalog_path: _path_to_catalog_json
|
|
run_results_paths:
|
|
- _path_to_run_results_json
|
|
target_platform: postgres
|
|
entities_enabled:
|
|
test_results: Only
|
|
```
|
|
|
|
Similarly, the following recipe shows you how to emit everything (i.e. models, sources, seeds, test definitions) but not test results:
|
|
|
|
```yaml
|
|
source:
|
|
type: dbt
|
|
config:
|
|
manifest_path: _path_to_manifest_json
|
|
catalog_path: _path_to_catalog_json
|
|
run_results_paths:
|
|
- _path_to_run_results_json
|
|
target_platform: postgres
|
|
entities_enabled:
|
|
test_results: No
|
|
```
|
|
|
|
### Multiple dbt projects
|
|
|
|
In more complex dbt setups, you may have multiple dbt projects, where models from one project are used as sources in another project.
|
|
DataHub supports this setup natively.
|
|
|
|
Each dbt project should have its own dbt ingestion recipe, and the `platform_instance` field in the recipe should be set to the dbt project name.
|
|
|
|
For example, if you have two dbt projects `analytics` and `data_mart`, you would have two ingestion recipes.
|
|
If you have models in the `data_mart` project that are used as sources in the `analytics` project, the lineage will be automatically captured.
|
|
|
|
```yaml
|
|
# Analytics dbt project
|
|
source:
|
|
type: dbt
|
|
config:
|
|
platform_instance: analytics
|
|
target_platform: postgres
|
|
manifest_path: analytics/target/manifest.json
|
|
catalog_path: analytics/target/catalog.json
|
|
# ... other configs
|
|
```
|
|
|
|
```yaml
|
|
# Data Mart dbt project
|
|
source:
|
|
type: dbt
|
|
config:
|
|
platform_instance: data_mart
|
|
target_platform: postgres
|
|
manifest_path: data_mart/target/manifest.json
|
|
catalog_path: data_mart/target/catalog.json
|
|
# ... other configs
|
|
```
|
|
|
|
If you have models that have tons of sources from other projects listed in the "Composed Of" section, it may also make sense to hide sources.
|
|
|
|
### Reducing "composed of" sprawl by hiding sources
|
|
|
|
When many dbt projects use a single table as a source, the "Composed Of" relationships can become very large and difficult to navigate
|
|
and extra source nodes can clutter the lineage graph.
|
|
|
|
This is particularly useful for multi-project setups, but can be useful in single-project setups as well.
|
|
|
|
The benefit is that your entire dbt estate becomes much easier to navigate, and the borders between projects less noticeable.
|
|
The downside is that we will not pick up any documentation or meta mappings applied to dbt sources.
|
|
|
|
To enable this, set `entities_enabled.sources: No` and `skip_sources_in_lineage: true` in your dbt source config:
|
|
|
|
```yaml
|
|
source:
|
|
type: dbt
|
|
config:
|
|
platform_instance: analytics
|
|
target_platform: postgres
|
|
manifest_path: analytics/target/manifest.json
|
|
catalog_path: analytics/target/catalog.json
|
|
# ... other configs
|
|
entities_enabled:
|
|
sources: No
|
|
skip_sources_in_lineage: true
|
|
```
|
|
|
|
[Experimental] It's also possible to use `skip_sources_in_lineage: true` without disabling sources entirely. If you do this, sources will not participate in the lineage graph - they'll have upstreams but no downstreams. However, they will still contribute to docs, tags, etc to the warehouse entity.
|