2021-02-16 15:32:43 +01:00

2020-12-27 12:58:48 +01:00
2020-11-02 20:03:22 +01:00
< p >
< a href = "https://github.com/deepset-ai/haystack/actions" >
< img alt = "Build" src = "https://github.com/deepset-ai/haystack/workflows/Build/badge.svg?branch=master" >
< / a >
< a href = "http://mypy-lang.org/" >
< img alt = "Checked with MyPy" src = "https://camo.githubusercontent.com/34b3a249cd6502d0a521ab2f42c8830b7cfd03fa/687474703a2f2f7777772e6d7970792d6c616e672e6f72672f7374617469632f6d7970795f62616467652e737667" >
< / a >
< a href = "https://haystack.deepset.ai/docs/intromd" >
< img alt = "Documentation" src = "https://img.shields.io/website/http/haystack.deepset.ai/docs/intromd.svg?down_color=red&down_message=offline&up_message=online" >
< / a >
< a href = "https://github.com/deepset-ai/haystack/releases" >
< img alt = "Release" src = "https://img.shields.io/github/release/deepset-ai/haystack" >
< / a >
< a href = "https://github.com/deepset-ai/haystack/blob/master/LICENSE" >
< img alt = "License" src = "https://img.shields.io/github/license/deepset-ai/haystack.svg?color=blue" >
< / a >
< a href = "https://github.com/deepset-ai/haystack/commits/master" >
< img alt = "Last commit" src = "https://img.shields.io/github/last-commit/deepset-ai/haystack" >
< / a >
2021-01-10 06:26:17 +01:00
< a href = "https://pepy.tech/project/farm-haystack" >
< img alt = "Downloads" src = "https://pepy.tech/badge/farm-haystack/month" >
2020-12-27 12:58:48 +01:00
< / a >
2020-11-02 20:03:22 +01:00
< / p >
2021-02-16 15:32:43 +01:00
Haystack is an end-to-end framework that enables you to build powerful and production-ready pipelines for different search use cases.
Whether you want to perform Question Answering or semantic document search, you can use the State-of-the-Art NLP models in Haystack to provide unique search experiences and allow your users to query in natural language.
2021-03-16 11:00:57 -04:00
Haystack is built in a modular fashion so that you can combine the best technology from other open-source projects like Huggingface's Transformers, Elasticsearch, or Milvus.
2020-11-02 20:03:22 +01:00
2021-02-16 15:32:43 +01:00
< p align = "center" > < img src = "https://raw.githubusercontent.com/deepset-ai/haystack/master/docs/_src/img/main_example.gif" > < / p >
## What to build with Haystack
2021-03-16 11:00:57 -04:00
- **Ask questions in natural language** and find granular answers in your documents.
- Perform **semantic search** and retrieve documents according to meaning, not keywords
- Use **off-the-shelf models** or **fine-tune** them to your domain.
- Use **user feedback** to evaluate, benchmark, and continuously improve your live models.
2021-02-16 15:32:43 +01:00
- Leverage existing **knowledge bases** and better handle the long tail of queries that **chatbots** receive.
- **Automate processes** by automatically applying a list of questions to new documents and using the extracted answers.
## Core Features
2021-03-16 11:00:57 -04:00
- **Latest models** : Utilize all latest transformer-based models (e.g., BERT, RoBERTa, MiniLM) for extractive QA, generative QA, and document retrieval.
- **Modular** : Multiple choices to fit your tech stack and use case. Pick your favorite database, file converter, or modeling framework.
- **Open** : 100% compatible with HuggingFace's model hub. Tight interfaces to other frameworks (e.g., Transformers, FARM, sentence-transformers)
- **Scalable** : Scale to millions of docs via retrievers, production-ready backends like Elasticsearch / FAISS, and a fastAPI REST API
- **End-to-End** : All tooling in one place: file conversion, cleaning, splitting, training, eval, inference, labeling, etc.
2021-02-16 15:32:43 +01:00
- **Developer friendly** : Easy to debug, extend and modify.
2021-03-16 11:00:57 -04:00
- **Customizable** : Fine-tune models to your domain or implement your custom DocumentStore.
2021-02-16 15:32:43 +01:00
- **Continuous Learning** : Collect new training data via user feedback in production & improve your models continuously
2020-11-02 20:03:22 +01:00
| | |
|-|-|
| :ledger: [Docs ](https://haystack.deepset.ai/docs/intromd ) | Usage, Guides, API documentation ...|
2021-02-16 18:38:04 +03:00
| :beginner: [Quick Demo ](https://github.com/deepset-ai/haystack/#quick-demo ) | Quickly see what Haystack offers |
2021-02-16 15:32:43 +01:00
| :floppy_disk: [Installation ](https://github.com/deepset-ai/haystack/#installation ) | How to install Haystack |
| :art: [Key Components ](https://github.com/deepset-ai/haystack/#key-components ) | Overview of core concepts |
2020-11-02 20:03:22 +01:00
| :mortar_board: [Tutorials ](https://github.com/deepset-ai/haystack/#tutorials ) | Jupyter/Colab Notebooks & Scripts |
2021-02-16 15:32:43 +01:00
| :eyes: [How to use Haystack ](https://github.com/deepset-ai/haystack/#how-to-use-haystack ) | Basic explanation of concepts, options and usage |
| :heart: [Contributing ](https://github.com/deepset-ai/haystack/#heart-contributing ) | We welcome all contributions! |
2020-11-02 20:03:22 +01:00
| :bar_chart: [Benchmarks ](https://haystack.deepset.ai/bm/benchmarks ) | Speed & Accuracy of Retriever, Readers and DocumentStores |
2020-11-26 14:01:05 +01:00
| :telescope: [Roadmap ](https://haystack.deepset.ai/docs/latest/roadmapmd ) | Public roadmap of Haystack |
2021-01-19 13:30:26 +03:00
| :pray: [Slack ](https://haystack.deepset.ai/community/join ) | Join our community on Slack |
| :bird: [Twitter ](https://twitter.com/deepset_ai ) | Follow us on Twitter for news and updates |
| :newspaper: [Blog ](https://medium.com/deepset-ai ) | Read our articles on Medium |
2020-11-02 20:03:22 +01:00
2021-02-16 15:32:43 +01:00
## Quick Demo
2020-11-02 20:03:22 +01:00
2021-02-16 15:32:43 +01:00
The quickest way to see what Haystack offers is to start a [Docker Compose ](https://docs.docker.com/compose/ ) demo application:
2020-11-02 20:03:22 +01:00
2021-02-16 15:32:43 +01:00
**1. Update/install Docker and Docker Compose, then launch Docker**
```
# apt-get update & & apt-get install docker & & apt-get install docker-compose
# service docker start
```
**2. Clone Haystack repository**
```
# git clone https://github.com/deepset-ai/haystack.git
```
**3. Launch demo app**
```
# cd haystack
# docker-compose up
```
2021-03-16 11:00:57 -04:00
You should be able to see the following in your terminal window as part of the log output:
2021-02-16 15:32:43 +01:00
```
..
ui_1 | You can now view your Streamlit app in your browser.
..
ui_1 | External URL: http://192.168.108.218:8501
..
haystack-api_1 | [2021-01-01 10:21:58 +0000] [17] [INFO] Application startup complete.
```
**4. Open the Streamlit UI for Haystack by pointing your browser to the "External URL" from above.**
You should see the following:
2021-02-16 17:05:15 +01:00

2021-02-16 15:32:43 +01:00
You can then try different queries against a pre-defined set of indexed articles related to Game of Thrones.
2021-03-16 11:00:57 -04:00
**Note**: The following containers are started as a part of this demo:
2021-02-16 15:32:43 +01:00
* Haystack API: listens on port 8000
* DocumentStore (Elasticsearch): listens on port 9200
* Streamlit UI: listens on port 8501
Please note that the demo will [publish ](https://docs.docker.com/config/containers/container-networking/ ) the container ports to the outside world. *We suggest that you review the firewall settings depending on your system setup and the security guidelines.*
2020-11-02 20:03:22 +01:00
## Installation
2021-02-16 15:32:43 +01:00
If you're interested in learning more about Haystack and using it as part of your application, we offer several options.
**1. Installing from a package**
2020-11-02 20:03:22 +01:00
2021-03-16 11:00:57 -04:00
You can install Haystack by using [pip ](https://github.com/pypa/pip ).
2020-11-02 20:03:22 +01:00
2021-02-16 15:32:43 +01:00
```
pip3 install farm-haystack
```
Please check our page [on PyPi ](https://pypi.org/project/farm-haystack/ ) for more information.
2020-11-02 20:03:22 +01:00
2021-02-16 15:32:43 +01:00
**2. Installing from GitHub**
2021-03-16 11:00:57 -04:00
You can also clone it from GitHub — in case you'd like to work with the master branch and check the latest features:
2021-02-16 15:32:43 +01:00
```
2020-11-02 20:03:22 +01:00
git clone https://github.com/deepset-ai/haystack.git
cd haystack
pip install --editable .
2021-02-16 15:32:43 +01:00
```
2021-03-16 11:00:57 -04:00
To update your installation, do a ``git pull``. The ``--editable` ` flag will update changes immediately.
2020-11-02 20:03:22 +01:00
2021-02-16 15:32:43 +01:00
**3. Installing on Windows**
2020-11-02 20:03:22 +01:00
2021-03-16 11:00:57 -04:00
On Windows, you might need:
2021-02-16 15:32:43 +01:00
2020-11-02 20:03:22 +01:00
```
2021-02-16 15:32:43 +01:00
pip install farm-haystack -f https://download.pytorch.org/whl/torch_stable.html
2020-11-02 20:03:22 +01:00
```
## Key Components
2021-02-16 17:05:15 +01:00

2020-11-02 20:03:22 +01:00
2021-03-16 11:00:57 -04:00
1. **FileConverter** : Extracts pure text from files (pdf, docx, pptx, html, and many more).
2. **PreProcessor** : Cleans and splits the text into smaller chunks.
3. **DocumentStore** : Database storing the documents, metadata, and vectors for our search.
We recommend Elasticsearch or FAISS but also have more light-weight options for fast prototyping (SQL or In-Memory).
2021-02-16 15:32:43 +01:00
4. **Retriever** : Fast algorithms that identify candidate documents for a given query from a large collection of documents.
2021-03-16 11:00:57 -04:00
Retrievers narrow down the search space significantly and are therefore crucial for scalable QA.
2020-11-02 20:03:22 +01:00
Haystack supports sparse methods (TF-IDF, BM25, custom Elasticsearch queries)
2021-03-16 11:00:57 -04:00
and state of the art dense methods (e.g., sentence-transformers and Dense Passage Retrieval)
5. **Reader** : Neural network (e.g., BERT or RoBERTA) that reads through texts in detail
to find an answer. The Reader takes multiple passages of text as input and returns top-n answers. Models are trained via [FARM ](https://github.com/deepset-ai/FARM ) or [Transformers ](https://github.com/huggingface/transformers ) on SQuAD like tasks. You can load a pre-trained model from [Hugging Face's model hub ](https://huggingface.co/models ) or fine-tune it on your domain data.
6. **Generator** : Neural network (e.g., RAG) that *generates* an answer for a given question conditioned on the retrieved documents from the retriever.
2020-12-22 13:34:28 +01:00
6. **Pipeline** : Stick building blocks together to highly custom pipelines that are represented as Directed Acyclic Graphs (DAG). Think of it as "Apache Airflow for search".
2021-03-16 11:00:57 -04:00
7. **REST API** : Exposes a simple API based on fastAPI for running QA search, uploading files, and collecting user feedback for continuous learning.
8. **Haystack Annotate** : Create custom QA labels to improve the performance of your domain-specific models. [Hosted version ](https://annotate.deepset.ai/login ) or [Docker images ](https://github.com/deepset-ai/haystack/tree/master/annotation_tool ).
2020-11-02 20:03:22 +01:00
2021-03-16 11:00:57 -04:00
It's quite simple to begin experimenting with Haystack. We'd recommend going through the [Tutorials ](https://github.com/deepset-ai/haystack/#tutorials ) section below, but here's an example code structure describing how to approach Haystack with the DocumentStore based on Elasticsearch.
2020-11-02 20:03:22 +01:00
2020-12-22 13:34:28 +01:00
```python
2021-02-16 15:32:43 +01:00
# Run elasticsearch, e.g. via docker run -d -p 9200:9200 -e "discovery.type=single-node" elasticsearch:7.6.2
2020-12-22 13:34:28 +01:00
# DB to store your docs
document_store = ElasticsearchDocumentStore(host="localhost", username="", password="",
2020-12-26 12:14:52 +01:00
index="document", embedding_dim=768,
embedding_field="embedding")
2020-12-22 13:34:28 +01:00
# Index your docs
# (Options: Convert text from PDFs etc. via FileConverter; Split and clean docs with the PreProcessor)
2021-02-16 15:32:43 +01:00
docs = [Document(text="Arya accompanies her father Ned and her sister Sansa to King's Landing. Before their departure ...", meta={}),
2020-12-26 12:14:52 +01:00
...]
2020-12-22 13:34:28 +01:00
document_store.write_documents([doc])
# Init Retriever: Fast algorithm to identify most promising candidate docs
# (Options: DPR, TF-IDF, Elasticsearch, Plain Embeddings ..)
2021-02-16 15:32:43 +01:00
retriever = DensePassageRetriever(document_store=document_store,
2020-12-22 13:34:28 +01:00
query_embedding_model="facebook/dpr-question_encoder-single-nq-base",
passage_embedding_model="facebook/dpr-ctx_encoder-single-nq-base",
)
document_store.update_embeddings(retriever)
2021-03-16 11:00:57 -04:00
# Init Reader: Powerful but slower neural model
2020-12-22 13:34:28 +01:00
# (Options: FARM or Transformers Framework; Extractive or generative models)
reader = FARMReader(model_name_or_path="deepset/roberta-base-squad2", use_gpu=True)
# The Pipeline sticks together Reader + Retriever to a DAG
2021-03-16 11:00:57 -04:00
# There are many different pipeline types, and you can easily build your own
2020-12-22 13:34:28 +01:00
pipeline = ExtractiveQAPipeline(reader, retriever)
# Voilá! Ask a question!
2020-12-26 12:14:52 +01:00
prediction = pipeline.run(query="Who is the father of Arya Stark?", top_k_retriever=10,top_k_reader=3)
2020-12-22 13:34:28 +01:00
print_answers(prediction, details="minimal")
[ { 'answer': 'Eddard',
2021-02-16 15:32:43 +01:00
'context': """... She travels with her father, Eddard, to
2020-12-22 13:34:28 +01:00
King's Landing when he is made Hand of the King ..."""},
{ 'answer': 'Ned',
2021-02-16 15:32:43 +01:00
'context': """... girl disguised as a boy all along and is surprised
2020-12-22 13:34:28 +01:00
to learn she is Arya, Ned Stark's daughter ..."""},
{ 'answer': 'Ned',
'context': """... Arya accompanies her father Ned and her sister Sansa to
King's Landing. Before their departure ..."""}
]
2021-02-16 15:32:43 +01:00
```
2020-11-02 20:03:22 +01:00
## Tutorials
2021-02-16 15:32:43 +01:00
If you'd like to learn more about Haystack, feel free to go through the tutorials below. All tutorials include both ``.ipynb`` and ``.py` ` code.
2020-11-02 20:03:22 +01:00
- Tutorial 1 - Basic QA Pipeline: [Jupyter notebook ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial1_Basic_QA_Pipeline.ipynb )
2021-02-16 15:32:43 +01:00
|
2020-11-02 20:03:22 +01:00
[Colab ](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial1_Basic_QA_Pipeline.ipynb )
2021-02-16 15:32:43 +01:00
|
[Python ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial1_Basic_QA_Pipeline.py )
2020-11-02 20:03:22 +01:00
- Tutorial 2 - Fine-tuning a model on own data: [Jupyter notebook ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial2_Finetune_a_model_on_your_data.ipynb )
2021-02-16 15:32:43 +01:00
|
2020-11-02 20:03:22 +01:00
[Colab ](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial2_Finetune_a_model_on_your_data.ipynb )
2021-02-16 15:32:43 +01:00
|
[Python ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial2_Finetune_a_model_on_your_data.py )
2020-11-02 20:03:22 +01:00
- Tutorial 3 - Basic QA Pipeline without Elasticsearch: [Jupyter notebook ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.ipynb )
2021-02-16 15:32:43 +01:00
|
2020-11-02 20:03:22 +01:00
[Colab ](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.ipynb )
2021-02-16 15:32:43 +01:00
|
[Python ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.py )
2020-11-02 20:03:22 +01:00
- Tutorial 4 - FAQ-style QA: [Jupyter notebook ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial4_FAQ_style_QA.ipynb )
2021-02-16 15:32:43 +01:00
|
2020-11-02 20:03:22 +01:00
[Colab ](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial4_FAQ_style_QA.ipynb )
2021-02-16 15:32:43 +01:00
|
[Python ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial4_FAQ_style_QA.py )
2020-11-02 20:03:22 +01:00
- Tutorial 5 - Evaluation of the whole QA-Pipeline: [Jupyter noteboook ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial5_Evaluation.ipynb )
2021-02-16 15:32:43 +01:00
|
2020-11-02 20:03:22 +01:00
[Colab ](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial5_Evaluation.ipynb )
2021-02-16 15:32:43 +01:00
|
[Python ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial5_Evaluation.py )
2020-11-02 20:03:22 +01:00
- Tutorial 6 - Better Retrievers via "Dense Passage Retrieval":
[Jupyter noteboook ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial6_Better_Retrieval_via_DPR.ipynb )
2021-02-16 15:32:43 +01:00
|
2020-11-02 20:03:22 +01:00
[Colab ](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial6_Better_Retrieval_via_DPR.ipynb )
2021-02-16 15:32:43 +01:00
|
[Python ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial6_Better_Retrieval_via_DPR.py )
2020-11-19 14:58:27 +01:00
- Tutorial 7 - Generative QA via "Retrieval-Augmented Generation":
[Jupyter noteboook ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial7_RAG_Generator.ipynb )
2021-02-16 15:32:43 +01:00
|
2020-11-19 14:58:27 +01:00
[Colab ](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial7_RAG_Generator.ipynb )
2021-02-16 15:32:43 +01:00
|
[Python ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial7_RAG_Generator.py )
2021-01-13 10:33:55 +01:00
- Tutorial 8 - Preprocessing:
[Jupyter noteboook ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial8_Preprocessing.ipynb )
2021-02-16 15:32:43 +01:00
|
2021-01-13 10:33:55 +01:00
[Colab ](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial8_Preprocessing.ipynb )
2021-02-16 15:32:43 +01:00
|
[Python ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial8_Preprocessing.py )
2021-01-13 10:33:55 +01:00
- Tutorial 9 - DPR Training:
[Jupyter noteboook ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial9_DPR_training.ipynb )
2021-02-16 15:32:43 +01:00
|
2021-01-13 10:33:55 +01:00
[Colab ](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial9_DPR_training.ipynb )
2021-02-16 15:32:43 +01:00
|
[Python ](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial9_DPR_training.py )
## How to use Haystack
2020-11-19 14:58:27 +01:00
2021-02-16 15:32:43 +01:00
Below you'll find more detailed descriptions of various Haystack components along with quick examples.
2020-11-02 20:03:22 +01:00
2021-02-16 15:32:43 +01:00
[File Conversion ](https://github.com/deepset-ai/haystack/blob/master/README.md#1-file-conversion ) | [Preprocessing ](https://github.com/deepset-ai/haystack/blob/master/README.md#2-preprocessing ) | [DocumentStores ](https://github.com/deepset-ai/haystack/blob/master/README.md#3-documentstores ) | [Retrievers ](https://github.com/deepset-ai/haystack/blob/master/README.md#4-retrievers ) | [Readers ](https://github.com/deepset-ai/haystack/blob/master/README.md#5-readers ) | [Pipelines ](https://github.com/deepset-ai/haystack/blob/master/README.md#6-pipelines ) | [REST API ](https://github.com/deepset-ai/haystack/blob/master/README.md#7-rest-api ) | [Labeling Tool ](https://github.com/deepset-ai/haystack/blob/master/README.md#8-labeling-tool )
Please also refer to our [documentation ](https://haystack.deepset.ai/docs/intromd ).
2020-11-02 20:03:22 +01:00
### 1) File Conversion
2021-02-16 15:32:43 +01:00
**What**
2020-11-02 20:03:22 +01:00
Different converters to extract text from your original files (pdf, docx, txt, html).
2021-03-16 11:00:57 -04:00
While it's almost impossible to cover all types, layouts, and special cases (especially in PDFs), we cover the most common formats (incl. multi-column) and extract meta-information (e.g., page splits). The converters are easily extendable so that you can customize them for your files if needed.
2020-11-02 20:03:22 +01:00
2021-02-16 15:32:43 +01:00
**Available options**
2020-11-02 20:03:22 +01:00
- Txt
2021-02-16 15:32:43 +01:00
- PDF
2020-11-02 20:03:22 +01:00
- Docx
- Apache Tika (Supports > 340 file formats)
2021-02-16 15:32:43 +01:00
**Example**
2020-11-02 20:03:22 +01:00
```python
#PDF
from haystack.file_converter.pdf import PDFToTextConverter
converter = PDFToTextConverter(remove_numeric_tables=True, valid_languages=["de","en"])
doc = converter.convert(file_path=file, meta=None)
# => {"text": "text first page \f text second page ...", "meta": None}
#DOCX
from haystack.file_converter.docx import DocxToTextConverter
converter = DocxToTextConverter(remove_numeric_tables=True, valid_languages=["de","en"])
doc = converter.convert(file_path=file, meta=None)
# => {"text": "some text", "meta": None}
```
### 2) Preprocessing
2021-02-16 15:32:43 +01:00
**What**
2021-03-16 11:00:57 -04:00
Cleaning and splitting your texts are crucial steps that will directly impact the speed and accuracy of your search.
2021-02-16 15:32:43 +01:00
The splitting of larger texts is especially important for achieving fast query speed. The longer the texts that the retriever passes to the reader, the slower your queries.
**Available Options**
2020-11-02 20:03:22 +01:00
2021-02-16 15:32:43 +01:00
We provide a basic `PreProcessor` class that allows:
2021-03-16 11:00:57 -04:00
- clean whitespace, headers, footer, and empty lines
- split by words, sentences, or passages
2021-02-16 15:32:43 +01:00
- option for "overlapping" splits
2020-11-02 20:03:22 +01:00
- option to never split within a sentence
2021-03-16 11:00:57 -04:00
You can easily extend this class to your custom requirements.
2020-11-02 20:03:22 +01:00
2021-02-16 15:32:43 +01:00
**Example**
```python
2020-11-02 20:03:22 +01:00
converter = PDFToTextConverter(remove_numeric_tables=True, valid_languages=["en"])
processor = PreProcessor(clean_empty_lines=True,
clean_whitespace=True,
clean_header_footer=True,
split_by="word",
split_length=200,
split_respect_sentence_boundary=True)
docs = []
for f_name, f_path in zip(filenames, filepaths):
# Optional: Supply any meta data here
# the "name" field will be used by DPR if embed_title=True, rest is custom and can be named arbitrarily
cur_meta = {"name": f_name, "category": "a" ...}
2021-02-16 15:32:43 +01:00
2020-11-02 20:03:22 +01:00
# Run the conversion on each file (PDF -> 1x doc)
d = converter.convert(f_path, meta=cur_meta)
2021-02-16 15:32:43 +01:00
2020-11-02 20:03:22 +01:00
# clean and split each dict (1x doc -> multiple docs)
d = processor.process(d)
docs.extend(d)
# at this point docs will be [{"text": "some", "meta":{"name": "myfilename", "category":"a"}},...]
document_store.write_documents(docs)
```
### 3) DocumentStores
2021-02-16 15:32:43 +01:00
**What**
2021-03-16 11:00:57 -04:00
- Store your texts, metadata, and optionally embeddings
- Documents should be chunked into smaller units (e.g., paragraphs)
2020-11-02 20:03:22 +01:00
before indexing to make the results returned by the Retriever more
granular and accurate.
2021-02-16 15:32:43 +01:00
**Available Options**
2020-11-02 20:03:22 +01:00
- Elasticsearch
- FAISS
- SQL
- InMemory
2021-02-16 15:32:43 +01:00
**Example**
2020-11-02 20:03:22 +01:00
2021-02-16 15:32:43 +01:00
```python
2020-11-02 20:03:22 +01:00
# Run elasticsearch, e.g. via docker run -d -p 9200:9200 -e "discovery.type=single-node" elasticsearch:7.6.2
2021-02-16 15:32:43 +01:00
# Connect
2020-11-02 20:03:22 +01:00
document_store = ElasticsearchDocumentStore(host="localhost", username="", password="", index="document")
# Get all documents
document_store.get_all_documents()
# Query
document_store.query(query="What is the meaning of life?", filters=None, top_k=5)
document_store.query_by_embedding(query_emb, filters=None, top_k=5)
2021-02-16 15:32:43 +01:00
```
2020-11-24 11:11:20 +01:00
-> See [docs ](https://haystack.deepset.ai/docs/latest/documentstoremd ) for details
2020-11-02 20:03:22 +01:00
### 4) Retrievers
2021-02-16 15:32:43 +01:00
**What**
2021-03-16 11:00:57 -04:00
The Retriever is a fast "filter" that can quickly go through the entire document store and pass a set of candidate documents to the Reader. It is a tool for sifting out the obvious negative cases, saving the Reader from doing more work than it needs to, and speeding up the querying process. There are two fundamentally different categories of retrievers: sparse (e.g., TF-IDF, BM25) and dense (e.g., DPR, sentence-transformers).
2020-11-02 20:03:22 +01:00
2021-02-16 15:32:43 +01:00
**Available Options**
2020-11-02 20:03:22 +01:00
- DensePassageRetriever
- ElasticsearchRetriever
- EmbeddingRetriever
- TfidfRetriever
2021-02-16 15:32:43 +01:00
**Example**
2020-11-02 20:03:22 +01:00
```python
retriever = DensePassageRetriever(document_store=document_store,
query_embedding_model="facebook/dpr-question_encoder-single-nq-base",
passage_embedding_model="facebook/dpr-ctx_encoder-single-nq-base",
use_gpu=True,
batch_size=16,
embed_title=True)
retriever.retrieve(query="Why did the revenue increase?")
# returns: [Document, Document]
```
-> See [docs ](https://haystack.deepset.ai/docs/latest/retrievermd ) for details
### 5) Readers
2021-02-16 15:32:43 +01:00
**What**
2021-03-16 11:00:57 -04:00
Neural networks (i.e., mostly Transformer-based) that read through texts in detail to find an answer. Use diverse models like BERT, RoBERTa or
2020-11-02 20:03:22 +01:00
XLNet trained via [FARM ](https://github.com/deepset-ai/FARM ) or on SQuAD-like datasets. The Reader takes multiple passages of text as input
and returns top-n answers with corresponding confidence scores. Both readers can load either a local model or any public model from [Hugging
Face's model hub](https://huggingface.co/models)
2021-02-16 15:32:43 +01:00
**Available Options**
2020-11-02 20:03:22 +01:00
- FARMReader: Reader based on [FARM ](https://github.com/deepset-ai/FARM ) incl. extensive configuration options and speed optimizations
2021-02-16 15:32:43 +01:00
- TransformersReader: Reader based on the `pipeline` class of HuggingFace's [Transformers ](https://github.com/huggingface/transformers ).
2020-11-02 20:03:22 +01:00
**Both** Readers can load models directly from HuggingFace's model hub.
2021-02-16 15:32:43 +01:00
**Example**
2020-11-02 20:03:22 +01:00
```python
reader = FARMReader(model_name_or_path="deepset/roberta-base-squad2",
use_gpu=False, no_ans_boost=-10, context_window_size=500,
top_k_per_candidate=3, top_k_per_sample=1,
num_processes=8, max_seq_len=256, doc_stride=128)
# Optional: Training & eval
reader.train(...)
reader.eval(...)
# Predict
reader.predict(question="Who is the father of Arya Starck?", documents=documents, top_k=3)
```
-> See [docs ](https://haystack.deepset.ai/docs/latest/readermd ) for details
2020-12-22 13:34:28 +01:00
### 6) Pipelines
2021-02-16 15:32:43 +01:00
**What**
2021-03-16 11:00:57 -04:00
To build modern search pipelines, you need two things: powerful building blocks and a flexible way to stick them together.
The `Pipeline` class is built exactly for this purpose and enables many search scenarios beyond QA. The core idea: you can make a Directed Acyclic Graph (DAG) where each node is one "building block" (Reader, Retriever, Generator, and so on).
2020-12-22 13:34:28 +01:00
2021-02-16 15:32:43 +01:00
**Available Options**
2021-03-16 11:00:57 -04:00
- Standard nodes: Reader, Retriever, Generator, etc.
2020-12-22 13:34:28 +01:00
- Join nodes: For example, combine results of multiple retrievers via the `JoinDocuments` node
2021-03-16 11:00:57 -04:00
- Decision Nodes: For example, classify an incoming query and, depending on the results, execute only a particular branch of your graph
2021-02-16 15:32:43 +01:00
**Example**
2020-12-22 13:34:28 +01:00
A minimal Open-Domain QA Pipeline:
```python
p = Pipeline()
p.add_node(component=retriever, name="ESRetriever1", inputs=["Query"])
p.add_node(component=reader, name="QAReader", inputs=["ESRetriever1"])
res = p.run(query="What did Einstein work on?", top_k_retriever=1)
```
2021-03-16 11:00:57 -04:00
You can **draw the DAG** to inspect better what you are building:
2020-12-22 13:34:28 +01:00
```python
p.draw(path="custom_pipe.png")
```
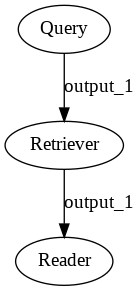
-> See [docs ](https://haystack.deepset.ai/docs/latest/pipelinesmd ) for details and example of more complex pipelines
### 7) REST API
2021-02-16 15:32:43 +01:00
**What**
2021-03-16 11:00:57 -04:00
A simple REST API based on [FastAPI ](https://fastapi.tiangolo.com/ ) to:
2020-11-02 20:03:22 +01:00
- search answers in texts ([extractive QA ](https://github.com/deepset-ai/haystack/blob/master/rest_api/controller/search.py ))
- search answers by comparing user question to existing questions
([FAQ-style QA ](https://github.com/deepset-ai/haystack/blob/master/rest_api/controller/search.py ))
- collect & export user feedback on answers to gain domain-specific
training data
([feedback ](https://github.com/deepset-ai/haystack/blob/master/rest_api/controller/feedback.py ))
- allow basic monitoring of requests (currently via APM in Kibana)
2021-02-16 15:32:43 +01:00
**Example**
2020-11-02 20:03:22 +01:00
To serve the API, adjust the values in `rest_api/config.py` and run:
gunicorn rest_api.application:app -b 0.0.0.0:8000 -k uvicorn.workers.UvicornWorker -t 300
You will find the Swagger API documentation at
< http: / / 127 . 0 . 0 . 1:8000 / docs >
2020-12-22 13:34:28 +01:00
### 8) Labeling Tool
2020-11-02 20:03:22 +01:00
- Use the [hosted version ](https://annotate.deepset.ai/login ) (Beta) or deploy it yourself with the [Docker Images ](https://github.com/deepset-ai/haystack/blob/master/annotation_tool ).
2021-03-16 11:00:57 -04:00
- Create labels with different techniques: Come up with questions (+ answers) while reading passages (SQuAD style) or have a set of pre-defined questions and look for answers in the document (~ Natural Questions).
2020-11-02 20:03:22 +01:00
- Structure your work via organizations, projects, users
- Upload your documents or import labels from an existing SQuAD-style dataset

## :heart: Contributing
2021-03-16 11:00:57 -04:00
We are very open to the community's contributions - be it a quick fix of a typo, or a completely new feature! You don't need to be a Haystack expert to provide meaningful improvements. To avoid any extra work on either side, please check our [Contributor Guidelines ](https://github.com/deepset-ai/haystack/blob/master/CONTRIBUTING.md ) first.
2020-11-02 20:03:22 +01:00
2021-01-19 13:30:26 +03:00
We'd also like to invite you to our Slack community channels. Please join [here ](https://haystack.deepset.ai/community/join )!
2020-11-02 20:03:22 +01:00
Tests will automatically run for every commit you push to your PR. You can also run them locally by executing [pytest ](https://docs.pytest.org/en/stable/ ) in your terminal from the root folder of this repository:
All tests:
``` bash
cd test
pytest
```
2021-02-16 15:32:43 +01:00
You can also only run a subset of tests by specifying a marker and the optional "not" keyword:
2020-11-02 20:03:22 +01:00
``` bash
cd test
pytest -m not elasticsearch
pytest -m elasticsearch
pytest -m generator
pytest -m tika
pytest -m not slow
...
```