mirror of
https://github.com/deepset-ai/haystack.git
synced 2025-11-03 03:09:28 +00:00
refactor: remove haystack demo along with deprecated Dockerfiles (#3829)
* remove haystack demo from the repo * remove install step from the action
This commit is contained in:
parent
fa78e2b0e4
commit
d728dc2210
1
.github/actions/python_cache/action.yml
vendored
1
.github/actions/python_cache/action.yml
vendored
@ -52,4 +52,3 @@ runs:
|
||||
python -m pip install --upgrade pip
|
||||
pip install .[all]
|
||||
pip install rest_api/
|
||||
pip install ui/
|
||||
|
||||
1
.github/workflows/compliance.yml
vendored
1
.github/workflows/compliance.yml
vendored
@ -30,7 +30,6 @@ jobs:
|
||||
pip install --upgrade pip
|
||||
pip install .[docstores,crawler,preprocessing,ocr,ray,onnx,beir]
|
||||
pip install rest_api/
|
||||
pip install ui/
|
||||
|
||||
- name: Create file with full dependency list
|
||||
run: |
|
||||
|
||||
87
.github/workflows/demo.yaml
vendored
87
.github/workflows/demo.yaml
vendored
@ -1,87 +0,0 @@
|
||||
name: Demo
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
|
||||
env:
|
||||
AWS_REGION: eu-west-1
|
||||
STACK_NAME: haystack-demo-production-instance
|
||||
ENVIRONMENT: production
|
||||
TEMPLATE_FILE: .github/workflows/demo/ec2-autoscaling-group.yaml
|
||||
VPC_STACK: haystack-demo-production-vpc
|
||||
INSTANCE_TYPE: g4dn.2xlarge
|
||||
|
||||
permissions:
|
||||
id-token: write
|
||||
contents: read
|
||||
|
||||
jobs:
|
||||
deploy:
|
||||
runs-on: ubuntu-20.04
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
|
||||
- name: AWS Authentication
|
||||
uses: aws-actions/configure-aws-credentials@67fbcbb121271f7775d2e7715933280b06314838
|
||||
with:
|
||||
aws-region: ${{ env.AWS_REGION }}
|
||||
role-to-assume: ${{ secrets.DEMO_AWS_DEPLOY_ROLE }}
|
||||
|
||||
- name: Deploy demo
|
||||
env:
|
||||
CF_KEY_NAME: ${{ secrets.DEMO_CF_KEY_NAME }}
|
||||
CF_IMAGE_ID: ${{ secrets.DEMO_CF_IMAGE_ID }}
|
||||
CF_IAM_INSTANCE_PROFILE: ${{ secrets.DEMO_CF_IAM_INSTANCE_PROFILE }}
|
||||
run: |
|
||||
echo -e "\n* Deploying CloudFormation Stack ${STACK_NAME}"
|
||||
|
||||
start_ts=$(date +"%s")
|
||||
|
||||
# Deploy the CloudFormation stack as a background process
|
||||
aws cloudformation deploy \
|
||||
--template-file "${TEMPLATE_FILE}" \
|
||||
--stack-name ${STACK_NAME} \
|
||||
--parameter-overrides \
|
||||
"Environment=${ENVIRONMENT}" \
|
||||
"VPCStack=${VPC_STACK}" \
|
||||
"GitRepositoryURL=${GITHUB_SERVER_URL}/${GITHUB_REPOSITORY}.git" \
|
||||
"GitBranchName=${GITHUB_REF_NAME}" \
|
||||
"GitCommitHash=${{ github.sha }}" \
|
||||
"InstanceType=${INSTANCE_TYPE}" \
|
||||
"KeyName=${CF_KEY_NAME}" \
|
||||
"ImageId=${CF_IMAGE_ID}" \
|
||||
"IamInstanceProfile=${CF_IAM_INSTANCE_PROFILE}" \
|
||||
--capabilities CAPABILITY_IAM > /dev/null &
|
||||
|
||||
# Save the pid for the background deploy process
|
||||
deploy_pid=$!
|
||||
|
||||
echo -e "\n** Progress of deployment for CloudFormation Stack ${STACK_NAME}"
|
||||
|
||||
# Show stack events while the background deploy process is still running
|
||||
touch stack-events.prev
|
||||
while kill -0 $deploy_pid 2>/dev/null
|
||||
do
|
||||
sleep 2
|
||||
|
||||
aws cloudformation describe-stack-events --stack-name ${STACK_NAME} 2>/dev/null \
|
||||
| jq -r --arg start_ts ${start_ts} '.StackEvents[] | (.Timestamp | sub("(?<x>T\\d+:\\d+:\\d+).*$"; "\(.x)Z") | fromdate) as $dt | select($dt >= ($start_ts|tonumber)) | "\($dt|todateiso8601)\t\(.LogicalResourceId)\t\(.ResourceStatus)\t\(.ResourceStatusReason // "")"' \
|
||||
| column -t -s $'\t' \
|
||||
| tac > stack-events.new
|
||||
|
||||
# describe-stack-events dumps all the events history but
|
||||
# we are only interested in printing only the new ones on each iteration
|
||||
tail -n $(($(wc -l < stack-events.new) - $(wc -l < stack-events.prev))) stack-events.new
|
||||
mv stack-events.new stack-events.prev
|
||||
done
|
||||
|
||||
LogGroupName=$(aws cloudformation describe-stacks \
|
||||
--stack-name ${STACK_NAME} \
|
||||
--query 'Stacks[0].Outputs[?OutputKey==`LogGroupName`].OutputValue' \
|
||||
--output text)
|
||||
LogGroupURL="https://${AWS_REGION}.console.aws.amazon.com/cloudwatch/home?region=${AWS_REGION}#logsV2:log-groups/log-group/$(echo ${LogGroupName} | sed 's#/#$252F#g')"
|
||||
echo -e "\n* EC2 instance CloudWatch logs can be found at ${LogGroupURL}"
|
||||
|
||||
# wait will exit whith the same exit code as the background deploy process
|
||||
# so we pass or fail the CI job based on the result of the deployment
|
||||
wait $deploy_pid
|
||||
17
.github/workflows/demo/docker-compose.demo.yml
vendored
17
.github/workflows/demo/docker-compose.demo.yml
vendored
@ -1,17 +0,0 @@
|
||||
version: "3"
|
||||
services:
|
||||
haystack-api:
|
||||
restart: always
|
||||
environment:
|
||||
CONCURRENT_REQUEST_PER_WORKER: 16
|
||||
HAYSTACK_EXECUTION_CONTEXT: "public_demo"
|
||||
command: "/bin/bash -c 'sleep 10 && gunicorn rest_api.application:app -b 0.0.0.0 -k uvicorn.workers.UvicornWorker --workers 3 --timeout 180'"
|
||||
|
||||
elasticsearch:
|
||||
restart: always
|
||||
ui:
|
||||
restart: always
|
||||
environment:
|
||||
DEFAULT_DOCS_FROM_RETRIEVER: 7
|
||||
DEFAULT_NUMBER_OF_ANSWERS: 5
|
||||
DISABLE_FILE_UPLOAD: 1
|
||||
316
.github/workflows/demo/ec2-autoscaling-group.yaml
vendored
316
.github/workflows/demo/ec2-autoscaling-group.yaml
vendored
@ -1,316 +0,0 @@
|
||||
# yaml-language-server: $schema=https://raw.githubusercontent.com/awslabs/goformation/v5.2.11/schema/cloudformation.schema.json
|
||||
|
||||
Parameters:
|
||||
Project:
|
||||
Description: A project name that is used for resource names
|
||||
Type: String
|
||||
Default: haystack-demo
|
||||
|
||||
Environment:
|
||||
Description: An environment name that is suffixed to resource names
|
||||
Type: String
|
||||
Default: production
|
||||
|
||||
VPCStack:
|
||||
Description: VPC stack name
|
||||
Type: String
|
||||
Default: haystack-demo-production-vpc
|
||||
|
||||
GitRepositoryURL:
|
||||
Description: Git repository to clone
|
||||
Type: String
|
||||
|
||||
GitBranchName:
|
||||
Description: Name of the branch from the git repository to checkout on instance
|
||||
Type: String
|
||||
|
||||
GitCommitHash:
|
||||
Description: Git commit hash that triggered this deployment
|
||||
Type: String
|
||||
|
||||
InstanceType:
|
||||
Description: EC2 instance type
|
||||
Type: String
|
||||
Default: p3.2xlarge
|
||||
|
||||
ImageId:
|
||||
Description: AMI to use for the EC2 instance
|
||||
Type: String
|
||||
|
||||
IamInstanceProfile:
|
||||
Description: IAM instance profile to attach to the EC2 instance
|
||||
Type: String
|
||||
|
||||
KeyName:
|
||||
Description: EC2 key pair to add to the EC2 instance
|
||||
Type: String
|
||||
|
||||
Resources:
|
||||
AutoScalingGroup:
|
||||
Type: AWS::AutoScaling::AutoScalingGroup
|
||||
CreationPolicy:
|
||||
ResourceSignal:
|
||||
Count: "1"
|
||||
Timeout: PT45M
|
||||
UpdatePolicy:
|
||||
AutoScalingRollingUpdate:
|
||||
MinInstancesInService: "1"
|
||||
MaxBatchSize: "1"
|
||||
PauseTime: PT45M
|
||||
WaitOnResourceSignals: true
|
||||
SuspendProcesses:
|
||||
- HealthCheck
|
||||
- ReplaceUnhealthy
|
||||
- AZRebalance
|
||||
- AlarmNotification
|
||||
- ScheduledActions
|
||||
Properties:
|
||||
LaunchTemplate:
|
||||
LaunchTemplateId: !Ref InstanceLaunchTemplate
|
||||
Version: !GetAtt InstanceLaunchTemplate.LatestVersionNumber
|
||||
VPCZoneIdentifier:
|
||||
- !ImportValue
|
||||
"Fn::Sub": "${VPCStack}-PublicSubnet1"
|
||||
- !ImportValue
|
||||
"Fn::Sub": "${VPCStack}-PublicSubnet2"
|
||||
MaxSize: "2"
|
||||
DesiredCapacity: "1"
|
||||
MinSize: "1"
|
||||
TargetGroupARNs:
|
||||
- !ImportValue
|
||||
"Fn::Sub": "${VPCStack}-DefaultTargetGroup"
|
||||
Tags:
|
||||
- Key: Name
|
||||
Value: !Sub ${Project}-${Environment}
|
||||
PropagateAtLaunch: true
|
||||
- Key: Project
|
||||
Value: !Ref Project
|
||||
PropagateAtLaunch: true
|
||||
- Key: Environment
|
||||
Value: !Ref Environment
|
||||
PropagateAtLaunch: true
|
||||
- Key: GitCommitHash
|
||||
Value: !Ref GitCommitHash
|
||||
PropagateAtLaunch: true
|
||||
|
||||
ParameterAmazonAgentConfig:
|
||||
Type: AWS::SSM::Parameter
|
||||
Properties:
|
||||
Name: !Sub /deepset/${Project}/${Environment}/ec2/amazon-cloudwatch-agent-config
|
||||
Type: String
|
||||
Tags:
|
||||
Name: !Sub /deepset/${Project}/${Environment}/ec2/amazon-cloudwatch-agent-config
|
||||
Project: !Ref Project
|
||||
Environment: !Ref Environment
|
||||
GitCommitHash: !Ref GitCommitHash
|
||||
Value: !Sub |
|
||||
{
|
||||
"agent": {
|
||||
"metrics_collection_interval": 60,
|
||||
"logfile": "/var/log/amazon-cloudwatch-agent.log",
|
||||
"debug": true
|
||||
},
|
||||
"logs": {
|
||||
"logs_collected": {
|
||||
"files": {
|
||||
"collect_list": [
|
||||
{
|
||||
"file_path": "/var/log/cloud-init-output.log",
|
||||
"log_group_name": "/deepset/${Project}/${Environment}/instance",
|
||||
"log_stream_name": "{instance_id}_/var/log/cloud-init-output.log"
|
||||
},
|
||||
{
|
||||
"file_path": "/var/log/cloud-init.log",
|
||||
"log_group_name": "/deepset/${Project}/${Environment}/instance",
|
||||
"log_stream_name": "{instance_id}_/var/log/cloud-init.log"
|
||||
},
|
||||
{
|
||||
"file_path": "/var/log/syslog",
|
||||
"log_group_name": "/deepset/${Project}/${Environment}/instance",
|
||||
"log_stream_name": "{instance_id}_/var/log/syslog"
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
},
|
||||
"metrics": {
|
||||
"append_dimensions": {
|
||||
"AutoScalingGroupName": "${!aws:AutoScalingGroupName}",
|
||||
"InstanceId": "${!aws:InstanceId}"
|
||||
},
|
||||
"aggregation_dimensions": [
|
||||
[
|
||||
"AutoScalingGroupName"
|
||||
]
|
||||
],
|
||||
"metrics_collected": {
|
||||
"collectd": {
|
||||
"metrics_aggregation_interval": 60
|
||||
},
|
||||
"statsd": {
|
||||
"metrics_aggregation_interval": 60,
|
||||
"metrics_collection_interval": 1,
|
||||
"service_address": ":8125"
|
||||
},
|
||||
"cpu": {
|
||||
"measurement": [
|
||||
"cpu_usage_idle",
|
||||
"cpu_usage_iowait",
|
||||
"cpu_usage_user",
|
||||
"cpu_usage_system"
|
||||
],
|
||||
"totalcpu": true
|
||||
},
|
||||
"disk": {
|
||||
"measurement": [
|
||||
"used_percent",
|
||||
"inodes_free"
|
||||
],
|
||||
"resources": [
|
||||
"/dev/xvda"
|
||||
]
|
||||
},
|
||||
"diskio": {
|
||||
"measurement": [
|
||||
"io_time",
|
||||
"write_bytes",
|
||||
"read_bytes",
|
||||
"writes",
|
||||
"reads"
|
||||
],
|
||||
"resources": [
|
||||
"/dev/xvda"
|
||||
]
|
||||
},
|
||||
"mem": {
|
||||
"measurement": [
|
||||
"mem_used_percent"
|
||||
]
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
InstanceLaunchTemplate:
|
||||
Type: AWS::EC2::LaunchTemplate
|
||||
Properties:
|
||||
LaunchTemplateName: !Sub ${Project}-${Environment}-${GitCommitHash}
|
||||
LaunchTemplateData:
|
||||
InstanceType: !Ref InstanceType
|
||||
ImageId: !Ref ImageId
|
||||
IamInstanceProfile:
|
||||
Arn: !Ref IamInstanceProfile
|
||||
KeyName: !Ref KeyName
|
||||
SecurityGroupIds:
|
||||
- !ImportValue
|
||||
"Fn::Sub": "${VPCStack}-InstanceSecurityGroup"
|
||||
Monitoring:
|
||||
Enabled: true
|
||||
EbsOptimized: true
|
||||
BlockDeviceMappings:
|
||||
- DeviceName: /dev/sda1
|
||||
Ebs:
|
||||
VolumeSize: 200
|
||||
TagSpecifications:
|
||||
- ResourceType: instance
|
||||
Tags:
|
||||
- Key: Name
|
||||
Value: !Sub ${Project}-${Environment}
|
||||
- Key: Project
|
||||
Value: !Ref Project
|
||||
- Key: Environment
|
||||
Value: !Ref Environment
|
||||
- Key: GitCommitHash
|
||||
Value: !Ref GitCommitHash
|
||||
- ResourceType: volume
|
||||
Tags:
|
||||
- Key: Name
|
||||
Value: !Sub ${Project}-${Environment}
|
||||
- Key: Project
|
||||
Value: !Ref Project
|
||||
- Key: Environment
|
||||
Value: !Ref Environment
|
||||
- Key: GitCommitHash
|
||||
Value: !Ref GitCommitHash
|
||||
- ResourceType: network-interface
|
||||
Tags:
|
||||
- Key: Name
|
||||
Value: !Sub ${Project}-${Environment}
|
||||
- Key: Project
|
||||
Value: !Ref Project
|
||||
- Key: Environment
|
||||
Value: !Ref Environment
|
||||
- Key: GitCommitHash
|
||||
Value: !Ref GitCommitHash
|
||||
|
||||
UserData:
|
||||
Fn::Base64: !Sub |
|
||||
#!/bin/bash -x
|
||||
|
||||
echo 'APT::Periodic::Update-Package-Lists "0";
|
||||
APT::Periodic::Unattended-Upgrade "0";' > /etc/apt/apt.conf.d/20auto-upgrades
|
||||
|
||||
export DEBIAN_FRONTEND=noninteractive
|
||||
apt-get update -q
|
||||
|
||||
apt-get install -yq collectd
|
||||
curl https://s3.amazonaws.com/amazoncloudwatch-agent/ubuntu/amd64/latest/amazon-cloudwatch-agent.deb -O
|
||||
dpkg -i -E ./amazon-cloudwatch-agent.deb
|
||||
/opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -s -c ssm:${ParameterAmazonAgentConfig}
|
||||
systemctl enable amazon-cloudwatch-agent.service
|
||||
systemctl restart amazon-cloudwatch-agent
|
||||
|
||||
mkdir -p /opt/aws/bin
|
||||
wget https://s3.amazonaws.com/cloudformation-examples/aws-cfn-bootstrap-py3-latest.tar.gz
|
||||
python3 -m easy_install --script-dir /opt/aws/bin aws-cfn-bootstrap-py3-latest.tar.gz
|
||||
|
||||
set -e
|
||||
trap '/opt/aws/bin/cfn-signal --exit-code 1 --stack ${AWS::StackId} --resource AutoScalingGroup --region ${AWS::Region}' ERR
|
||||
|
||||
echo "Deploying Haystack demo, commit ${GitCommitHash}"
|
||||
|
||||
apt-get install -yq curl git ca-certificates curl gnupg lsb-release
|
||||
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
|
||||
echo \
|
||||
"deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \
|
||||
$(lsb_release -cs) stable" | tee /etc/apt/sources.list.d/docker.list > /dev/null
|
||||
apt-get update -q
|
||||
apt-get install -yq docker-ce docker-ce-cli containerd.io
|
||||
|
||||
# Install Docker compose
|
||||
curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/bin/docker-compose
|
||||
chmod +x /usr/bin/docker-compose
|
||||
|
||||
# Install Nvidia container runtime
|
||||
curl -s -L https://nvidia.github.io/nvidia-container-runtime/gpgkey | \
|
||||
apt-key add -
|
||||
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
|
||||
curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.list | \
|
||||
tee /etc/apt/sources.list.d/nvidia-container-runtime.list
|
||||
apt-get update -q
|
||||
apt-get install -yq nvidia-container-runtime
|
||||
|
||||
# Setup and start Docker
|
||||
groupadd docker || true
|
||||
usermod -aG docker $USER || true
|
||||
newgrp docker || true
|
||||
systemctl unmask docker
|
||||
systemctl restart docker
|
||||
|
||||
# Exposes the GPUs to Docker
|
||||
docker run --rm --gpus all ubuntu nvidia-smi
|
||||
|
||||
# Clone and start Haystack
|
||||
git clone --branch "${GitBranchName}" "${GitRepositoryURL}" /opt/haystack
|
||||
cd /opt/haystack
|
||||
export COMPOSE_FILE=docker-compose-gpu.yml:.github/workflows/demo/docker-compose.demo.yml
|
||||
export COMPOSE_HTTP_TIMEOUT=300
|
||||
docker-compose pull
|
||||
docker-compose up -d
|
||||
|
||||
/opt/aws/bin/cfn-signal --exit-code $? --stack ${AWS::StackId} --resource AutoScalingGroup --region ${AWS::Region}
|
||||
|
||||
Outputs:
|
||||
LogGroupName:
|
||||
Description: CloudWatch log group to send instance logs
|
||||
Value: !Sub /deepset/${Project}/${Environment}/instance
|
||||
68
.github/workflows/docker_build.yml
vendored
68
.github/workflows/docker_build.yml
vendored
@ -1,68 +0,0 @@
|
||||
name: docker-build
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
tags:
|
||||
- v*
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-20.04
|
||||
timeout-minutes: 45
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
include:
|
||||
- dockerfile: Dockerfile
|
||||
repository: deepset/haystack-cpu
|
||||
tagprefix: ''
|
||||
default: true
|
||||
|
||||
- dockerfile: Dockerfile-GPU
|
||||
repository: deepset/haystack-gpu
|
||||
tagprefix: 'demo-'
|
||||
default: true
|
||||
|
||||
- dockerfile: Dockerfile-GPU-minimal
|
||||
repository: deepset/haystack-gpu
|
||||
tagprefix: 'minimal-'
|
||||
default: false
|
||||
|
||||
steps:
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v3
|
||||
|
||||
- name: Docker meta
|
||||
id: meta
|
||||
uses: docker/metadata-action@v4
|
||||
with:
|
||||
images: |
|
||||
${{ matrix.repository }}
|
||||
tags: |
|
||||
type=semver,pattern={{version}},prefix=${{ matrix.tagprefix }}
|
||||
type=sha,format=long,prefix=${{ matrix.tagprefix }}
|
||||
type=sha,format=long,prefix=,enable=${{ matrix.default }}
|
||||
type=raw,value=latest,prefix=${{ matrix.tagprefix }}
|
||||
type=raw,value=latest,prefix=,enable=${{ matrix.default }}
|
||||
|
||||
- name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v1
|
||||
|
||||
- name: Login to DockerHub
|
||||
uses: docker/login-action@v1
|
||||
with:
|
||||
username: ${{ secrets.DOCKER_HUB_USER }}
|
||||
password: ${{ secrets.DOCKER_HUB_TOKEN }}
|
||||
|
||||
- name: Build and push docker image
|
||||
uses: docker/build-push-action@v3
|
||||
with:
|
||||
file: ${{ matrix.dockerfile }}
|
||||
tags: ${{ steps.meta.outputs.tags }}
|
||||
push: true
|
||||
cache-from: type=registry,ref=${{ matrix.repository }}:${{ matrix.tagprefix }}latest
|
||||
cache-to: type=inline
|
||||
13
.github/workflows/tests.yml
vendored
13
.github/workflows/tests.yml
vendored
@ -94,7 +94,6 @@ jobs:
|
||||
# a lot of errors which were never detected before!
|
||||
# pip install .
|
||||
# pip install rest_api/
|
||||
# pip install ui/
|
||||
# FIXME --install-types does not work properly yet, see https://github.com/python/mypy/issues/10600
|
||||
# Hotfixing by installing type packages explicitly.
|
||||
# Run mypy --install-types haystack locally to ensure the list is still up to date
|
||||
@ -107,8 +106,6 @@ jobs:
|
||||
mypy haystack
|
||||
echo "=== rest_api/ ==="
|
||||
mypy rest_api --exclude=rest_api/build/ --exclude=rest_api/test/
|
||||
echo "=== ui/ ==="
|
||||
mypy ui --exclude=ui/build/ --exclude=ui/test/
|
||||
|
||||
- uses: act10ns/slack@v1
|
||||
with:
|
||||
@ -129,7 +126,7 @@ jobs:
|
||||
|
||||
- name: Pylint
|
||||
run: |
|
||||
pylint -ry -j 0 haystack/ rest_api/rest_api ui/ui
|
||||
pylint -ry -j 0 haystack/ rest_api/rest_api
|
||||
|
||||
- uses: act10ns/slack@v1
|
||||
with:
|
||||
@ -552,7 +549,7 @@ jobs:
|
||||
channel: '#haystack'
|
||||
if: failure() && github.repository_owner == 'deepset-ai' && github.ref == 'refs/heads/main'
|
||||
|
||||
rest-and-ui:
|
||||
rest_api:
|
||||
needs: [mypy, pylint, black]
|
||||
|
||||
strategy:
|
||||
@ -566,16 +563,14 @@ jobs:
|
||||
- name: Setup Python
|
||||
uses: ./.github/actions/python_cache/
|
||||
|
||||
- name: Install REST API and UI
|
||||
- name: Install REST API
|
||||
run: |
|
||||
pip install -U "./rest_api[dev]"
|
||||
pip install -U ui/
|
||||
pip install . # -U prevents the schema generation
|
||||
pip install .
|
||||
|
||||
- name: Run tests
|
||||
run: |
|
||||
pytest ${{ env.PYTEST_PARAMS }} rest_api/
|
||||
pytest ${{ env.PYTEST_PARAMS }} ui/
|
||||
|
||||
- uses: act10ns/slack@v1
|
||||
with:
|
||||
|
||||
56
Dockerfile
56
Dockerfile
@ -1,56 +0,0 @@
|
||||
#
|
||||
# DEPRECATION NOTICE
|
||||
#
|
||||
# This Dockerfile and the relative image deepset/haystack-cpu
|
||||
# have been deprecated in 1.9.0 in favor of:
|
||||
# https://github.com/deepset-ai/haystack/tree/main/docker
|
||||
#
|
||||
FROM python:3.7.4-stretch
|
||||
|
||||
WORKDIR /home/user
|
||||
|
||||
RUN apt-get update && apt-get install -y \
|
||||
curl \
|
||||
git \
|
||||
pkg-config \
|
||||
cmake \
|
||||
libpoppler-cpp-dev \
|
||||
tesseract-ocr \
|
||||
libtesseract-dev \
|
||||
poppler-utils && \
|
||||
rm -rf /var/lib/apt/lists/*
|
||||
|
||||
# Install PDF converter
|
||||
RUN wget --no-check-certificate https://dl.xpdfreader.com/xpdf-tools-linux-4.04.tar.gz && \
|
||||
tar -xvf xpdf-tools-linux-4.04.tar.gz && cp xpdf-tools-linux-4.04/bin64/pdftotext /usr/local/bin
|
||||
|
||||
# Copy Haystack code
|
||||
COPY haystack /home/user/haystack/
|
||||
# Copy package files & models
|
||||
COPY pyproject.toml VERSION.txt LICENSE README.md models* /home/user/
|
||||
# Copy REST API code
|
||||
COPY rest_api /home/user/rest_api/
|
||||
|
||||
# Install package
|
||||
RUN pip install --upgrade pip
|
||||
RUN pip install --no-cache-dir .[docstores,crawler,preprocessing,ocr,ray]
|
||||
RUN pip install --no-cache-dir rest_api/
|
||||
RUN ls /home/user
|
||||
RUN pip freeze
|
||||
RUN python3 -c "from haystack.utils.docker import cache_models;cache_models()"
|
||||
|
||||
# create folder for /file-upload API endpoint with write permissions, this might be adjusted depending on FILE_UPLOAD_PATH
|
||||
RUN mkdir -p /home/user/rest_api/file-upload
|
||||
RUN chmod 777 /home/user/rest_api/file-upload
|
||||
|
||||
# optional : copy sqlite db if needed for testing
|
||||
#COPY qa.db /home/user/
|
||||
|
||||
# optional: copy data directory containing docs for ingestion
|
||||
#COPY data /home/user/data
|
||||
|
||||
EXPOSE 8000
|
||||
ENV HAYSTACK_DOCKER_CONTAINER="HAYSTACK_CPU_CONTAINER"
|
||||
|
||||
# cmd for running the API
|
||||
CMD ["gunicorn", "rest_api.application:app", "-b", "0.0.0.0", "-k", "uvicorn.workers.UvicornWorker", "--workers", "1", "--timeout", "180"]
|
||||
@ -1,73 +0,0 @@
|
||||
#
|
||||
# DEPRECATION NOTICE
|
||||
#
|
||||
# This Dockerfile and the relative image deepset/haystack-gpu
|
||||
# have been deprecated in 1.9.0 in favor of:
|
||||
# https://github.com/deepset-ai/haystack/tree/main/docker
|
||||
#
|
||||
FROM nvidia/cuda:11.1.1-runtime-ubuntu20.04
|
||||
|
||||
WORKDIR /home/user
|
||||
|
||||
ENV LC_ALL=C.UTF-8
|
||||
ENV LANG=C.UTF-8
|
||||
|
||||
# Install software dependencies
|
||||
RUN apt-get update && apt-get install -y software-properties-common && \
|
||||
add-apt-repository ppa:deadsnakes/ppa && \
|
||||
apt-get install -y \
|
||||
cmake \
|
||||
curl \
|
||||
git \
|
||||
libpoppler-cpp-dev \
|
||||
libtesseract-dev \
|
||||
pkg-config \
|
||||
poppler-utils \
|
||||
python3-pip \
|
||||
python3.7 \
|
||||
python3.7-dev \
|
||||
python3.7-distutils \
|
||||
swig \
|
||||
tesseract-ocr \
|
||||
wget && \
|
||||
rm -rf /var/lib/apt/lists/*
|
||||
|
||||
# Install PDF converter
|
||||
RUN curl -s https://dl.xpdfreader.com/xpdf-tools-linux-4.04.tar.gz | tar -xvzf - -C /usr/local/bin --strip-components=2 xpdf-tools-linux-4.04/bin64/pdftotext
|
||||
|
||||
# Set default Python version
|
||||
RUN update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.7 1 && \
|
||||
update-alternatives --set python3 /usr/bin/python3.7
|
||||
|
||||
# Copy Haystack code
|
||||
COPY haystack /home/user/haystack/
|
||||
# Copy package files & models
|
||||
COPY pyproject.toml VERSION.txt LICENSE README.md models* /home/user/
|
||||
# Copy REST API code
|
||||
COPY rest_api /home/user/rest_api/
|
||||
|
||||
# Install package
|
||||
RUN pip install --upgrade pip
|
||||
RUN pip install --no-cache-dir .[docstores-gpu,crawler,preprocessing,ocr,ray]
|
||||
RUN pip install --no-cache-dir rest_api/
|
||||
# Install PyTorch for CUDA 11
|
||||
RUN pip3 install --no-cache-dir torch==1.10.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html
|
||||
|
||||
# Cache Roberta and NLTK data
|
||||
RUN python3 -c "from haystack.utils.docker import cache_models;cache_models()"
|
||||
|
||||
# create folder for /file-upload API endpoint with write permissions, this might be adjusted depending on FILE_UPLOAD_PATH
|
||||
RUN mkdir -p /home/user/rest_api/file-upload
|
||||
RUN chmod 777 /home/user/rest_api/file-upload
|
||||
|
||||
# optional : copy sqlite db if needed for testing
|
||||
#COPY qa.db /home/user/
|
||||
|
||||
# optional: copy data directory containing docs for ingestion
|
||||
#COPY data /home/user/data
|
||||
|
||||
EXPOSE 8000
|
||||
ENV HAYSTACK_DOCKER_CONTAINER="HAYSTACK_GPU_CONTAINER"
|
||||
|
||||
# cmd for running the API (note: "--preload" is not working with cuda)
|
||||
CMD ["gunicorn", "rest_api.application:app", "-b", "0.0.0.0", "-k", "uvicorn.workers.UvicornWorker", "--workers", "1", "--timeout", "180"]
|
||||
@ -1,44 +0,0 @@
|
||||
#
|
||||
# DEPRECATION NOTICE
|
||||
#
|
||||
# This Dockerfile and the relative image deepset/haystack-gpu:minimal
|
||||
# have been deprecated in 1.9.0 in favor of:
|
||||
# https://github.com/deepset-ai/haystack/tree/main/docker
|
||||
#
|
||||
FROM nvidia/cuda:11.3.1-runtime-ubuntu20.04
|
||||
|
||||
WORKDIR /home/user
|
||||
|
||||
ENV LC_ALL=C.UTF-8
|
||||
ENV LANG=C.UTF-8
|
||||
ENV HAYSTACK_DOCKER_CONTAINER="HAYSTACK_MINIMAL_GPU_CONTAINER"
|
||||
|
||||
# Install software dependencies
|
||||
RUN apt-get update && apt-get install -y software-properties-common && \
|
||||
add-apt-repository ppa:deadsnakes/ppa && \
|
||||
DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \
|
||||
curl \
|
||||
git \
|
||||
poppler-utils \
|
||||
python3-pip \
|
||||
python3.8 \
|
||||
python3.8-distutils \
|
||||
swig \
|
||||
tesseract-ocr && \
|
||||
# Cleanup apt cache
|
||||
rm -rf /var/lib/apt/lists/* && \
|
||||
# Install PDF converter
|
||||
curl -s https://dl.xpdfreader.com/xpdf-tools-linux-4.04.tar.gz \
|
||||
| tar -xvzf - -C /usr/local/bin --strip-components=2 xpdf-tools-linux-4.04/bin64/pdftotext
|
||||
|
||||
# Copy Haystack source code
|
||||
COPY pyproject.toml VERSION.txt LICENSE README.md /home/user/
|
||||
COPY haystack /home/user/haystack/
|
||||
|
||||
# Install all the dependencies, including ocr component
|
||||
RUN pip3 install --upgrade pip requests six idna certifi setuptools
|
||||
RUN pip3 install .[ocr]
|
||||
RUN pip3 install --no-cache-dir torch==1.10.2+cu113 -f https://download.pytorch.org/whl/torch_stable.html
|
||||
|
||||
# Cleanup copied files after installation is completed
|
||||
RUN rm -rf /home/user/*
|
||||
@ -1,62 +0,0 @@
|
||||
version: "3"
|
||||
services:
|
||||
|
||||
haystack-api:
|
||||
build:
|
||||
context: .
|
||||
dockerfile: Dockerfile-GPU
|
||||
image: "deepset/haystack-gpu:latest"
|
||||
# in recent docker-compose version you can enable GPU resources. Make sure to fulfill the prerequisites listed here: https://docs.docker.com/compose/gpu-support/
|
||||
deploy:
|
||||
resources:
|
||||
reservations:
|
||||
devices:
|
||||
- driver: nvidia
|
||||
count: 1
|
||||
capabilities: [gpu]
|
||||
# # Mount custom Pipeline YAML and custom Components.
|
||||
# volumes:
|
||||
# - ./rest_api/rest_api/pipeline:/home/user/rest_api/rest_api/pipeline
|
||||
ports:
|
||||
- 8000:8000
|
||||
restart: on-failure
|
||||
environment:
|
||||
# See rest_api/rest_api/pipeline/pipelines.haystack-pipeline.yml for configurations of Search & Indexing Pipeline.
|
||||
- DOCUMENTSTORE_PARAMS_HOST=elasticsearch
|
||||
- PIPELINE_YAML_PATH=/home/user/rest_api/rest_api/pipeline/pipelines_dpr.haystack-pipeline.yml
|
||||
- CONCURRENT_REQUEST_PER_WORKER
|
||||
depends_on:
|
||||
- elasticsearch
|
||||
command: "/bin/bash -c 'sleep 10 && gunicorn rest_api.application:app -b 0.0.0.0 -k uvicorn.workers.UvicornWorker --workers 1 --timeout 180'"
|
||||
|
||||
elasticsearch:
|
||||
# This will start an empty elasticsearch instance (so you have to add your documents yourself)
|
||||
#image: "elasticsearch:7.9.2"
|
||||
# If you want a demo image instead that is "ready-to-query" with some indexed articles
|
||||
# about countries and capital cities from Wikipedia:
|
||||
image: "deepset/elasticsearch-countries-and-capitals"
|
||||
ports:
|
||||
- 9200:9200
|
||||
restart: on-failure
|
||||
environment:
|
||||
- discovery.type=single-node
|
||||
|
||||
ui:
|
||||
build:
|
||||
context: ui
|
||||
dockerfile: Dockerfile
|
||||
image: "deepset/haystack-streamlit-ui:latest"
|
||||
ports:
|
||||
- 8501:8501
|
||||
restart: on-failure
|
||||
environment:
|
||||
- API_ENDPOINT=http://haystack-api:8000
|
||||
- EVAL_FILE=eval_labels_example.csv
|
||||
# The value fot the following variables will be read from the host, if present.
|
||||
# They can also be temporarily set for docker-compose, for example:
|
||||
# DISABLE_FILE_UPLOAD=1 DEFAULT_DOCS_FROM_RETRIEVER=5 docker-compose up
|
||||
- DISABLE_FILE_UPLOAD
|
||||
- DEFAULT_QUESTION_AT_STARTUP
|
||||
- DEFAULT_DOCS_FROM_RETRIEVER
|
||||
- DEFAULT_NUMBER_OF_ANSWERS
|
||||
command: "/bin/bash -c 'sleep 15 && python -m streamlit run ui/webapp.py'"
|
||||
@ -1,34 +0,0 @@
|
||||
# docker-compose override file to enable HTTP traffic monitoring between ui, haystack-api and elasticsearch using mitmproxy.
|
||||
# After startup you can find mitmweb under localhost:8081 in your browser.
|
||||
# Usage: docker-compose -f docker-compose[-gpu].yml -f docker-compose.mitm.yml up
|
||||
version: "3"
|
||||
services:
|
||||
haystack-api:
|
||||
environment:
|
||||
- HTTP_PROXY=http://mitmproxy:8080
|
||||
- HTTPS_PROXY=https://mitmproxy:8080
|
||||
- REQUESTS_CA_BUNDLE=/etc/ssl/certs/ca-certificates.crt
|
||||
- DOCUMENTSTORE_PARAMS_USE_SYSTEM_PROXY=true
|
||||
command: "/bin/bash -c 'sleep 10
|
||||
&& wget -e http_proxy=mitmproxy:8080 -O /usr/local/share/ca-certificates/mitmproxy.crt http://mitm.it/cert/pem
|
||||
&& update-ca-certificates
|
||||
&& gunicorn rest_api.application:app -b 0.0.0.0 -k uvicorn.workers.UvicornWorker --workers 2 --timeout 180'"
|
||||
depends_on:
|
||||
- mitmproxy
|
||||
ui:
|
||||
environment:
|
||||
- HTTP_PROXY=http://mitmproxy:8080
|
||||
- HTTPS_PROXY=https://mitmproxy:8080
|
||||
- REQUESTS_CA_BUNDLE=/etc/ssl/certs/ca-certificates.crt
|
||||
command: "/bin/bash -c 'sleep 15
|
||||
&& wget -e http_proxy=mitmproxy:8080 -O /usr/local/share/ca-certificates/mitmproxy.crt http://mitm.it/cert/pem
|
||||
&& update-ca-certificates
|
||||
&& python -m streamlit run ui/webapp.py'"
|
||||
depends_on:
|
||||
- mitmproxy
|
||||
mitmproxy:
|
||||
image: "mitmproxy/mitmproxy:latest"
|
||||
ports:
|
||||
- 8080:8080
|
||||
- 8081:8081
|
||||
command: "mitmweb --web-host 0.0.0.0 --set block_global=false"
|
||||
@ -1,16 +0,0 @@
|
||||
FROM python:3.7.4-stretch
|
||||
|
||||
# RUN apt-get update && apt-get install -y curl git pkg-config cmake
|
||||
|
||||
# copy code
|
||||
COPY . /ui
|
||||
|
||||
# install as a package
|
||||
RUN pip install --upgrade pip && \
|
||||
pip install /ui/
|
||||
|
||||
WORKDIR /ui
|
||||
EXPOSE 8501
|
||||
|
||||
# cmd for running the API
|
||||
CMD ["python", "-m", "streamlit", "run", "ui/webapp.py"]
|
||||
202
ui/LICENSE
202
ui/LICENSE
@ -1,202 +0,0 @@
|
||||
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
|
||||
1. Definitions.
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
APPENDIX: How to apply the Apache License to your work.
|
||||
|
||||
To apply the Apache License to your work, attach the following
|
||||
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||
replaced with your own identifying information. (Don't include
|
||||
the brackets!) The text should be enclosed in the appropriate
|
||||
comment syntax for the file format. We also recommend that a
|
||||
file or class name and description of purpose be included on the
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright 2021 deepset GmbH
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
43
ui/README.md
43
ui/README.md
@ -1,43 +0,0 @@
|
||||
## Demo UI
|
||||
|
||||
This is a minimal UI that can spin up to test Haystack for your prototypes. It's based on streamlit and is very easy to extend for your purposes.
|
||||
|
||||
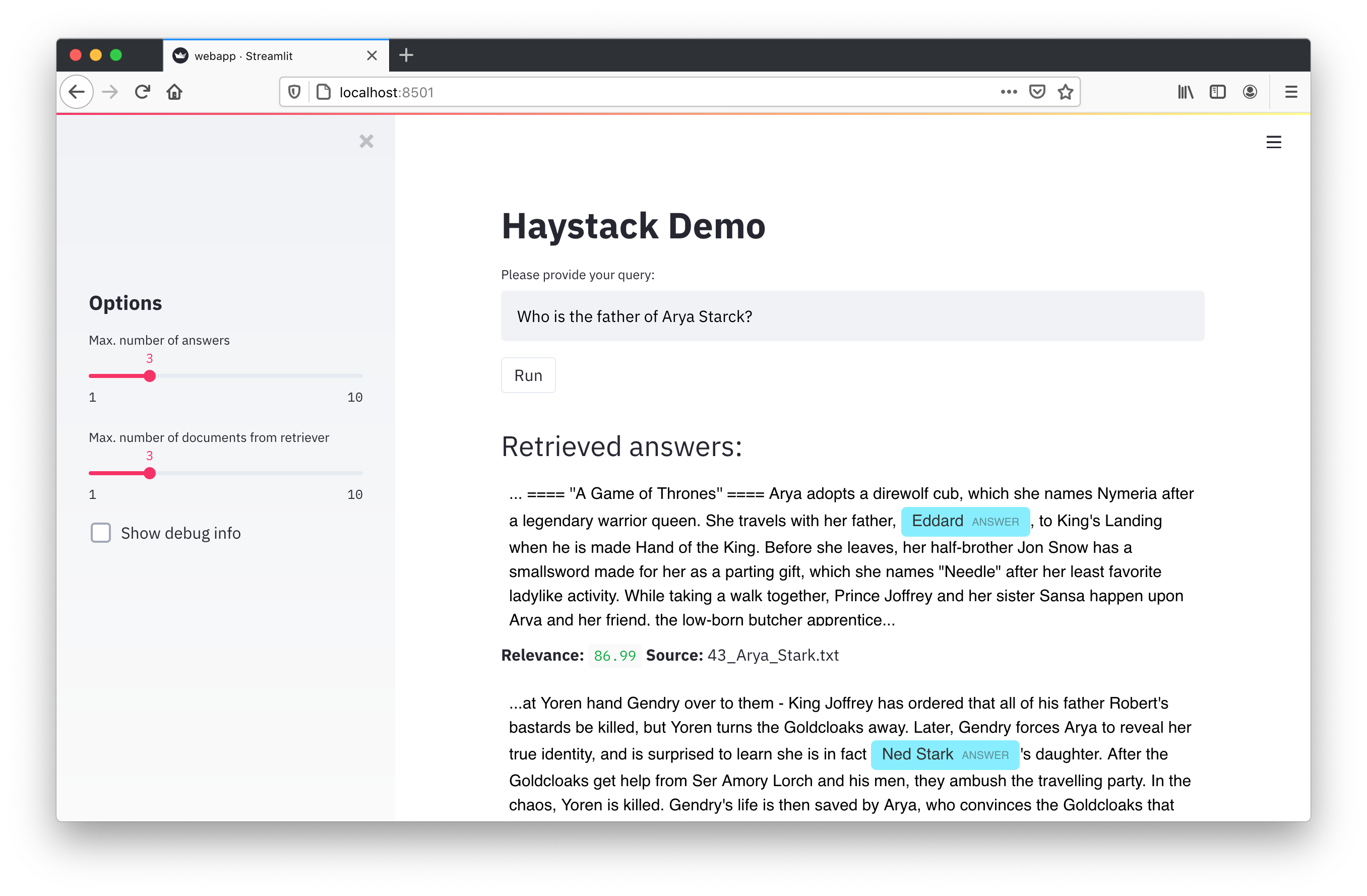
|
||||
|
||||
## Usage
|
||||
|
||||
### Get started with Haystack
|
||||
|
||||
The UI interacts with the Haystack REST API. To get started with Haystack please visit the [README](https://github.com/deepset-ai/haystack/tree/main#key-components) or checko out our [tutorials](https://haystack.deepset.ai/tutorials/first-qa-system).
|
||||
|
||||
### Option 1: Local
|
||||
|
||||
Execute in this folder:
|
||||
```
|
||||
streamlit run ui/webapp.py
|
||||
```
|
||||
|
||||
Requirements: This expects a running Haystack REST API at `http://localhost:8000`
|
||||
|
||||
### Option 2: Container
|
||||
|
||||
Just run
|
||||
```
|
||||
docker-compose up -d
|
||||
```
|
||||
in the root folder of the Haystack repository. This will start three containers (Elasticsearch, Haystack API, Haystack UI).
|
||||
You can find the UI at `http://localhost:8501`
|
||||
|
||||
## Evaluation Mode
|
||||
|
||||
The evaluation mode leverages the feedback REST API endpoint of haystack. The user has the options "Wrong answer", "Wrong answer and wrong passage" and "Wrong answer and wrong passage" to give feedback.
|
||||
|
||||
In order to use the UI in evaluation mode, you need an ElasticSearch instance with pre-indexed files and the Haystack REST API. You can set the environment up via docker images. For ElasticSearch, you can check out our [documentation](https://haystack.deepset.ai/usage/document-store#initialisation) and for setting up the REST API this [link](https://github.com/deepset-ai/haystack/blob/main/README.md#7-rest-api).
|
||||
|
||||
To enter the evaluation mode, select the checkbox "Evaluation mode" in the sidebar. The UI will load the predefined questions from the file [`eval_labels_examples`](https://raw.githubusercontent.com/deepset-ai/haystack/main/ui/ui/eval_labels_example.csv). The file needs to be prefilled with your data. This way, the user will get a random question from the set and can give his feedback with the buttons below the questions. To load a new question, click the button "Get random question".
|
||||
|
||||
The file just needs to have two columns separated by semicolon. You can add more columns but the UI will ignore them. Every line represents a questions answer pair. The columns with the questions needs to be named “Question Text” and the answer column “Answer” so that they can be loaded correctly. Currently, the easiest way to create the file is manually by adding question answer pairs.
|
||||
|
||||
The feedback can be exported with the API endpoint `export-doc-qa-feedback`. To learn more about finetuning a model with user feedback, please check out our [docs](https://haystack.deepset.ai/usage/domain-adaptation#user-feedback).
|
||||
|
||||

|
||||
@ -1,71 +0,0 @@
|
||||
[build-system]
|
||||
requires = ["hatchling"]
|
||||
build-backend = "hatchling.build"
|
||||
|
||||
[project]
|
||||
name = "ui"
|
||||
description = 'Minimal UI for Haystack (https://github.com/deepset-ai/haystack)'
|
||||
readme = "README.md"
|
||||
requires-python = ">=3.7"
|
||||
license = "Apache-2.0"
|
||||
keywords = []
|
||||
authors = [
|
||||
{ name = "deepset.ai", email = "malte.pietsch@deepset.ai" },
|
||||
]
|
||||
classifiers = [
|
||||
"Development Status :: 5 - Production/Stable",
|
||||
"Intended Audience :: Science/Research",
|
||||
"Topic :: Scientific/Engineering :: Artificial Intelligence",
|
||||
"Operating System :: OS Independent",
|
||||
"Programming Language :: Python",
|
||||
"Programming Language :: Python :: 3.7",
|
||||
"Programming Language :: Python :: 3.8",
|
||||
"Programming Language :: Python :: 3.9",
|
||||
"Programming Language :: Python :: 3.10",
|
||||
"Programming Language :: Python :: Implementation :: CPython",
|
||||
]
|
||||
dependencies = [
|
||||
"streamlit >= 1.9.0, < 2",
|
||||
"st-annotated-text >= 2.0.0, < 3",
|
||||
"markdown >= 3.3.4, < 4"
|
||||
]
|
||||
dynamic = ["version"]
|
||||
|
||||
[project.urls]
|
||||
Documentation = "https://github.com/deepset-ai/haystack/tree/main/ui#readme"
|
||||
Issues = "https://github.com/deepset-ai/haystack/issues"
|
||||
Source = "https://github.com/deepset-ai/haystack/tree/main/ui"
|
||||
|
||||
[tool.hatch.version]
|
||||
path = "ui/__about__.py"
|
||||
|
||||
[tool.hatch.build.targets.sdist]
|
||||
[tool.hatch.build.targets.wheel]
|
||||
|
||||
[tool.hatch.envs.default]
|
||||
dependencies = [
|
||||
"pytest",
|
||||
"pytest-cov",
|
||||
]
|
||||
[tool.hatch.envs.default.scripts]
|
||||
cov = "pytest --cov-report=term-missing --cov-config=pyproject.toml --cov=ui --cov=tests"
|
||||
no-cov = "cov --no-cov"
|
||||
|
||||
[[tool.hatch.envs.test.matrix]]
|
||||
python = ["37", "38", "39", "310"]
|
||||
|
||||
[tool.coverage.run]
|
||||
branch = true
|
||||
parallel = true
|
||||
omit = ["ui/__about__.py"]
|
||||
|
||||
[tool.coverage.report]
|
||||
exclude_lines = [
|
||||
"no cov",
|
||||
"if __name__ == .__main__.:",
|
||||
"if TYPE_CHECKING:",
|
||||
]
|
||||
|
||||
[tool.black]
|
||||
line-length = 120
|
||||
skip_magic_trailing_comma = true # For compatibility with pydoc>=4.6, check if still needed.
|
||||
@ -1,15 +0,0 @@
|
||||
from unittest.mock import patch
|
||||
|
||||
from ui.utils import haystack_is_ready
|
||||
|
||||
|
||||
def test_haystack_is_ready():
|
||||
with patch("requests.get") as mocked_get:
|
||||
mocked_get.return_value.status_code = 200
|
||||
assert haystack_is_ready()
|
||||
|
||||
|
||||
def test_haystack_is_ready_fail():
|
||||
with patch("requests.get") as mocked_get:
|
||||
mocked_get.return_value.status_code = 400
|
||||
assert not haystack_is_ready()
|
||||
@ -1,10 +0,0 @@
|
||||
import logging
|
||||
|
||||
from pathlib import Path
|
||||
|
||||
|
||||
__version__ = "0.0.0"
|
||||
try:
|
||||
__version__ = open(Path(__file__).parent.parent / "VERSION.txt", "r").read()
|
||||
except Exception as e:
|
||||
logging.exception("No VERSION.txt found!")
|
||||
@ -1,14 +0,0 @@
|
||||
"Question Text";"Answer"
|
||||
"What is the capital of France?";"Paris"
|
||||
"What's the tallest mountain in Africa?";"Mount Kilimanjaro"
|
||||
"What's the climate of Beijing?";"monsoon-influenced humid continental"
|
||||
"What's the longest river of Europe?";"The Volga"
|
||||
"What's the deepest lake in the world?";"Lake Bajkal"
|
||||
"How many people live in the capital of the US?";"689,545"
|
||||
"Which Chinese city is the largest?";"Shanghai"
|
||||
"What's the type of government of the UK?";"unitary parliamentary democracy and constitutional monarchy"
|
||||
"What currency is used in Hungary?";"Hungarian forint"
|
||||
"In which city is the Louvre?";"Paris"
|
||||
"Who is the current king of Spain?";"Felipe VI"
|
||||
"Which countries border with Mongolia?";"Russia and China"
|
||||
"What's the current name of Swaziland?";"Eswatini"
|
||||
|
124
ui/ui/utils.py
124
ui/ui/utils.py
@ -1,124 +0,0 @@
|
||||
# pylint: disable=missing-timeout
|
||||
|
||||
from typing import List, Dict, Any, Tuple, Optional
|
||||
|
||||
import os
|
||||
import logging
|
||||
from time import sleep
|
||||
|
||||
import requests
|
||||
import streamlit as st
|
||||
|
||||
|
||||
API_ENDPOINT = os.getenv("API_ENDPOINT", "http://localhost:8000")
|
||||
STATUS = "initialized"
|
||||
HS_VERSION = "hs_version"
|
||||
DOC_REQUEST = "query"
|
||||
DOC_FEEDBACK = "feedback"
|
||||
DOC_UPLOAD = "file-upload"
|
||||
|
||||
|
||||
def haystack_is_ready():
|
||||
"""
|
||||
Used to show the "Haystack is loading..." message
|
||||
"""
|
||||
url = f"{API_ENDPOINT}/{STATUS}"
|
||||
try:
|
||||
if requests.get(url).status_code < 400:
|
||||
return True
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
sleep(1) # To avoid spamming a non-existing endpoint at startup
|
||||
return False
|
||||
|
||||
|
||||
@st.cache
|
||||
def haystack_version():
|
||||
"""
|
||||
Get the Haystack version from the REST API
|
||||
"""
|
||||
url = f"{API_ENDPOINT}/{HS_VERSION}"
|
||||
return requests.get(url, timeout=0.1).json()["hs_version"]
|
||||
|
||||
|
||||
def query(query, filters={}, top_k_reader=5, top_k_retriever=5) -> Tuple[List[Dict[str, Any]], Dict[str, str]]:
|
||||
"""
|
||||
Send a query to the REST API and parse the answer.
|
||||
Returns both a ready-to-use representation of the results and the raw JSON.
|
||||
"""
|
||||
|
||||
url = f"{API_ENDPOINT}/{DOC_REQUEST}"
|
||||
params = {"filters": filters, "Retriever": {"top_k": top_k_retriever}, "Reader": {"top_k": top_k_reader}}
|
||||
req = {"query": query, "params": params}
|
||||
response_raw = requests.post(url, json=req)
|
||||
|
||||
if response_raw.status_code >= 400 and response_raw.status_code != 503:
|
||||
raise Exception(f"{vars(response_raw)}")
|
||||
|
||||
response = response_raw.json()
|
||||
if "errors" in response:
|
||||
raise Exception(", ".join(response["errors"]))
|
||||
|
||||
# Format response
|
||||
results = []
|
||||
answers = response["answers"]
|
||||
for answer in answers:
|
||||
if answer.get("answer", None):
|
||||
results.append(
|
||||
{
|
||||
"context": "..." + answer["context"] + "...",
|
||||
"answer": answer.get("answer", None),
|
||||
"source": answer["meta"]["name"],
|
||||
"relevance": round(answer["score"] * 100, 2),
|
||||
"document": [doc for doc in response["documents"] if doc["id"] == answer["document_id"]][0],
|
||||
"offset_start_in_doc": answer["offsets_in_document"][0]["start"],
|
||||
"_raw": answer,
|
||||
}
|
||||
)
|
||||
else:
|
||||
results.append(
|
||||
{
|
||||
"context": None,
|
||||
"answer": None,
|
||||
"document": None,
|
||||
"relevance": round(answer["score"] * 100, 2),
|
||||
"_raw": answer,
|
||||
}
|
||||
)
|
||||
return results, response
|
||||
|
||||
|
||||
def send_feedback(query, answer_obj, is_correct_answer, is_correct_document, document) -> None:
|
||||
"""
|
||||
Send a feedback (label) to the REST API
|
||||
"""
|
||||
url = f"{API_ENDPOINT}/{DOC_FEEDBACK}"
|
||||
req = {
|
||||
"query": query,
|
||||
"document": document,
|
||||
"is_correct_answer": is_correct_answer,
|
||||
"is_correct_document": is_correct_document,
|
||||
"origin": "user-feedback",
|
||||
"answer": answer_obj,
|
||||
}
|
||||
response_raw = requests.post(url, json=req)
|
||||
if response_raw.status_code >= 400:
|
||||
raise ValueError(f"An error was returned [code {response_raw.status_code}]: {response_raw.json()}")
|
||||
|
||||
|
||||
def upload_doc(file):
|
||||
url = f"{API_ENDPOINT}/{DOC_UPLOAD}"
|
||||
files = [("files", file)]
|
||||
response = requests.post(url, files=files).json()
|
||||
return response
|
||||
|
||||
|
||||
def get_backlink(result) -> Tuple[Optional[str], Optional[str]]:
|
||||
if result.get("document", None):
|
||||
doc = result["document"]
|
||||
if isinstance(doc, dict):
|
||||
if doc.get("meta", None):
|
||||
if isinstance(doc["meta"], dict):
|
||||
if doc["meta"].get("url", None) and doc["meta"].get("title", None):
|
||||
return doc["meta"]["url"], doc["meta"]["title"]
|
||||
return None, None
|
||||
294
ui/ui/webapp.py
294
ui/ui/webapp.py
@ -1,294 +0,0 @@
|
||||
import os
|
||||
import sys
|
||||
import logging
|
||||
from pathlib import Path
|
||||
from json import JSONDecodeError
|
||||
|
||||
import pandas as pd
|
||||
import streamlit as st
|
||||
from annotated_text import annotation
|
||||
from markdown import markdown
|
||||
|
||||
from ui.utils import haystack_is_ready, query, send_feedback, upload_doc, haystack_version, get_backlink
|
||||
|
||||
|
||||
# Adjust to a question that you would like users to see in the search bar when they load the UI:
|
||||
DEFAULT_QUESTION_AT_STARTUP = os.getenv("DEFAULT_QUESTION_AT_STARTUP", "What's the capital of France?")
|
||||
DEFAULT_ANSWER_AT_STARTUP = os.getenv("DEFAULT_ANSWER_AT_STARTUP", "Paris")
|
||||
|
||||
# Sliders
|
||||
DEFAULT_DOCS_FROM_RETRIEVER = int(os.getenv("DEFAULT_DOCS_FROM_RETRIEVER", "3"))
|
||||
DEFAULT_NUMBER_OF_ANSWERS = int(os.getenv("DEFAULT_NUMBER_OF_ANSWERS", "3"))
|
||||
|
||||
# Labels for the evaluation
|
||||
EVAL_LABELS = os.getenv("EVAL_FILE", str(Path(__file__).parent / "eval_labels_example.csv"))
|
||||
|
||||
# Whether the file upload should be enabled or not
|
||||
DISABLE_FILE_UPLOAD = bool(os.getenv("DISABLE_FILE_UPLOAD"))
|
||||
|
||||
|
||||
def set_state_if_absent(key, value):
|
||||
if key not in st.session_state:
|
||||
st.session_state[key] = value
|
||||
|
||||
|
||||
def main():
|
||||
|
||||
st.set_page_config(page_title="Haystack Demo", page_icon="https://haystack.deepset.ai/img/HaystackIcon.png")
|
||||
|
||||
# Persistent state
|
||||
set_state_if_absent("question", DEFAULT_QUESTION_AT_STARTUP)
|
||||
set_state_if_absent("answer", DEFAULT_ANSWER_AT_STARTUP)
|
||||
set_state_if_absent("results", None)
|
||||
set_state_if_absent("raw_json", None)
|
||||
set_state_if_absent("random_question_requested", False)
|
||||
|
||||
# Small callback to reset the interface in case the text of the question changes
|
||||
def reset_results(*args):
|
||||
st.session_state.answer = None
|
||||
st.session_state.results = None
|
||||
st.session_state.raw_json = None
|
||||
|
||||
# Title
|
||||
st.write("# Haystack Demo - Explore the world")
|
||||
st.markdown(
|
||||
"""
|
||||
This demo takes its data from a selection of Wikipedia pages crawled in November 2021 on the topic of
|
||||
|
||||
<h3 style='text-align:center;padding: 0 0 1rem;'>Countries and capital cities</h3>
|
||||
|
||||
Ask any question on this topic and see if Haystack can find the correct answer to your query!
|
||||
|
||||
*Note: do not use keywords, but full-fledged questions.* The demo is not optimized to deal with keyword queries and might misunderstand you.
|
||||
""",
|
||||
unsafe_allow_html=True,
|
||||
)
|
||||
|
||||
# Sidebar
|
||||
st.sidebar.header("Options")
|
||||
top_k_reader = st.sidebar.slider(
|
||||
"Max. number of answers",
|
||||
min_value=1,
|
||||
max_value=10,
|
||||
value=DEFAULT_NUMBER_OF_ANSWERS,
|
||||
step=1,
|
||||
on_change=reset_results,
|
||||
)
|
||||
top_k_retriever = st.sidebar.slider(
|
||||
"Max. number of documents from retriever",
|
||||
min_value=1,
|
||||
max_value=10,
|
||||
value=DEFAULT_DOCS_FROM_RETRIEVER,
|
||||
step=1,
|
||||
on_change=reset_results,
|
||||
)
|
||||
eval_mode = st.sidebar.checkbox("Evaluation mode")
|
||||
debug = st.sidebar.checkbox("Show debug info")
|
||||
|
||||
# File upload block
|
||||
if not DISABLE_FILE_UPLOAD:
|
||||
st.sidebar.write("## File Upload:")
|
||||
data_files = st.sidebar.file_uploader(
|
||||
"upload", type=["pdf", "txt", "docx"], accept_multiple_files=True, label_visibility="hidden"
|
||||
)
|
||||
for data_file in data_files:
|
||||
# Upload file
|
||||
if data_file:
|
||||
raw_json = upload_doc(data_file)
|
||||
st.sidebar.write(str(data_file.name) + " ✅ ")
|
||||
if debug:
|
||||
st.subheader("REST API JSON response")
|
||||
st.sidebar.write(raw_json)
|
||||
|
||||
hs_version = ""
|
||||
try:
|
||||
hs_version = f" <small>(v{haystack_version()})</small>"
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
st.sidebar.markdown(
|
||||
f"""
|
||||
<style>
|
||||
a {{
|
||||
text-decoration: none;
|
||||
}}
|
||||
.haystack-footer {{
|
||||
text-align: center;
|
||||
}}
|
||||
.haystack-footer h4 {{
|
||||
margin: 0.1rem;
|
||||
padding:0;
|
||||
}}
|
||||
footer {{
|
||||
opacity: 0;
|
||||
}}
|
||||
</style>
|
||||
<div class="haystack-footer">
|
||||
<hr />
|
||||
<h4>Built with <a href="https://www.deepset.ai/haystack">Haystack</a>{hs_version}</h4>
|
||||
<p>Get it on <a href="https://github.com/deepset-ai/haystack/">GitHub</a> - Read the <a href="https://haystack.deepset.ai/overview/intro">Docs</a></p>
|
||||
<small>Data crawled from <a href="https://en.wikipedia.org/wiki/Category:Lists_of_countries_by_continent">Wikipedia</a> in November 2021.<br />See the <a href="https://creativecommons.org/licenses/by-sa/3.0/">License</a> (CC BY-SA 3.0).</small>
|
||||
</div>
|
||||
""",
|
||||
unsafe_allow_html=True,
|
||||
)
|
||||
|
||||
# Load csv into pandas dataframe
|
||||
try:
|
||||
df = pd.read_csv(EVAL_LABELS, sep=";")
|
||||
except Exception:
|
||||
st.error(
|
||||
f"The eval file was not found. Please check the demo's [README](https://github.com/deepset-ai/haystack/tree/main/ui/README.md) for more information."
|
||||
)
|
||||
sys.exit(
|
||||
f"The eval file was not found under `{EVAL_LABELS}`. Please check the README (https://github.com/deepset-ai/haystack/tree/main/ui/README.md) for more information."
|
||||
)
|
||||
|
||||
# Search bar
|
||||
question = st.text_input(
|
||||
value=st.session_state.question,
|
||||
max_chars=100,
|
||||
on_change=reset_results,
|
||||
label="question",
|
||||
label_visibility="hidden",
|
||||
)
|
||||
col1, col2 = st.columns(2)
|
||||
col1.markdown("<style>.stButton button {width:100%;}</style>", unsafe_allow_html=True)
|
||||
col2.markdown("<style>.stButton button {width:100%;}</style>", unsafe_allow_html=True)
|
||||
|
||||
# Run button
|
||||
run_pressed = col1.button("Run")
|
||||
|
||||
# Get next random question from the CSV
|
||||
if col2.button("Random question"):
|
||||
reset_results()
|
||||
new_row = df.sample(1)
|
||||
while (
|
||||
new_row["Question Text"].values[0] == st.session_state.question
|
||||
): # Avoid picking the same question twice (the change is not visible on the UI)
|
||||
new_row = df.sample(1)
|
||||
st.session_state.question = new_row["Question Text"].values[0]
|
||||
st.session_state.answer = new_row["Answer"].values[0]
|
||||
st.session_state.random_question_requested = True
|
||||
# Re-runs the script setting the random question as the textbox value
|
||||
# Unfortunately necessary as the Random Question button is _below_ the textbox
|
||||
if hasattr(st, "scriptrunner"):
|
||||
raise st.scriptrunner.script_runner.RerunException(
|
||||
st.scriptrunner.script_requests.RerunData(widget_states=None)
|
||||
)
|
||||
raise st.runtime.scriptrunner.script_runner.RerunException(
|
||||
st.runtime.scriptrunner.script_requests.RerunData(widget_states=None)
|
||||
)
|
||||
st.session_state.random_question_requested = False
|
||||
|
||||
run_query = (
|
||||
run_pressed or question != st.session_state.question
|
||||
) and not st.session_state.random_question_requested
|
||||
|
||||
# Check the connection
|
||||
with st.spinner("⌛️ Haystack is starting..."):
|
||||
if not haystack_is_ready():
|
||||
st.error("🚫 Connection Error. Is Haystack running?")
|
||||
run_query = False
|
||||
reset_results()
|
||||
|
||||
# Get results for query
|
||||
if run_query and question:
|
||||
reset_results()
|
||||
st.session_state.question = question
|
||||
|
||||
with st.spinner(
|
||||
"🧠 Performing neural search on documents... \n "
|
||||
"Do you want to optimize speed or accuracy? \n"
|
||||
"Check out the docs: https://haystack.deepset.ai/usage/optimization "
|
||||
):
|
||||
try:
|
||||
st.session_state.results, st.session_state.raw_json = query(
|
||||
question, top_k_reader=top_k_reader, top_k_retriever=top_k_retriever
|
||||
)
|
||||
except JSONDecodeError as je:
|
||||
st.error("👓 An error occurred reading the results. Is the document store working?")
|
||||
return
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
if "The server is busy processing requests" in str(e) or "503" in str(e):
|
||||
st.error("🧑🌾 All our workers are busy! Try again later.")
|
||||
else:
|
||||
st.error("🐞 An error occurred during the request.")
|
||||
return
|
||||
|
||||
if st.session_state.results:
|
||||
|
||||
# Show the gold answer if we use a question of the given set
|
||||
if eval_mode and st.session_state.answer:
|
||||
st.write("## Correct answer:")
|
||||
st.write(st.session_state.answer)
|
||||
|
||||
st.write("## Results:")
|
||||
|
||||
for count, result in enumerate(st.session_state.results):
|
||||
if result["answer"]:
|
||||
answer, context = result["answer"], result["context"]
|
||||
start_idx = context.find(answer)
|
||||
end_idx = start_idx + len(answer)
|
||||
# Hack due to this bug: https://github.com/streamlit/streamlit/issues/3190
|
||||
st.write(
|
||||
markdown(context[:start_idx] + str(annotation(answer, "ANSWER", "#8ef")) + context[end_idx:]),
|
||||
unsafe_allow_html=True,
|
||||
)
|
||||
source = ""
|
||||
url, title = get_backlink(result)
|
||||
if url and title:
|
||||
source = f"[{result['document']['meta']['title']}]({result['document']['meta']['url']})"
|
||||
else:
|
||||
source = f"{result['source']}"
|
||||
st.markdown(f"**Relevance:** {result['relevance']} - **Source:** {source}")
|
||||
|
||||
else:
|
||||
st.info(
|
||||
"🤔 Haystack is unsure whether any of the documents contain an answer to your question. Try to reformulate it!"
|
||||
)
|
||||
st.write("**Relevance:** ", result["relevance"])
|
||||
|
||||
if eval_mode and result["answer"]:
|
||||
# Define columns for buttons
|
||||
is_correct_answer = None
|
||||
is_correct_document = None
|
||||
|
||||
button_col1, button_col2, button_col3, _ = st.columns([1, 1, 1, 6])
|
||||
if button_col1.button("👍", key=f"{result['context']}{count}1", help="Correct answer"):
|
||||
is_correct_answer = True
|
||||
is_correct_document = True
|
||||
|
||||
if button_col2.button("👎", key=f"{result['context']}{count}2", help="Wrong answer and wrong passage"):
|
||||
is_correct_answer = False
|
||||
is_correct_document = False
|
||||
|
||||
if button_col3.button(
|
||||
"👎👍", key=f"{result['context']}{count}3", help="Wrong answer, but correct passage"
|
||||
):
|
||||
is_correct_answer = False
|
||||
is_correct_document = True
|
||||
|
||||
if is_correct_answer is not None and is_correct_document is not None:
|
||||
try:
|
||||
send_feedback(
|
||||
query=question,
|
||||
answer_obj=result["_raw"],
|
||||
is_correct_answer=is_correct_answer,
|
||||
is_correct_document=is_correct_document,
|
||||
document=result["document"],
|
||||
)
|
||||
st.success("✨ Thanks for your feedback! ✨")
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
st.error("🐞 An error occurred while submitting your feedback!")
|
||||
|
||||
st.write("___")
|
||||
|
||||
if debug:
|
||||
st.subheader("REST API JSON response")
|
||||
st.write(st.session_state.raw_json)
|
||||
|
||||
|
||||
main()
|
||||
Loading…
x
Reference in New Issue
Block a user