mirror of
https://github.com/deepset-ai/haystack.git
synced 2026-01-06 12:07:04 +00:00
refactor: update package metadata (#3079)
* Update package metadata * fix yaml * remove Python version cap * address review
This commit is contained in:
parent
6d4031d8f6
commit
f6a4a14790
4
.github/actions/python_cache/action.yml
vendored
4
.github/actions/python_cache/action.yml
vendored
@ -39,7 +39,7 @@ runs:
|
||||
with:
|
||||
path: ${{ env.pythonLocation }}
|
||||
# The cache will be rebuild every day and at every change of the dependency files
|
||||
key: ${{ inputs.prefix }}-py${{ inputs.pythonVersion }}-${{ env.date }}-${{ hashFiles('**/setup.py') }}-${{ hashFiles('**/setup.cfg') }}-${{ hashFiles('**/pyproject.toml') }}
|
||||
key: ${{ inputs.prefix }}-py${{ inputs.pythonVersion }}-${{ env.date }}-${{ hashFiles('**/pyproject.toml') }}
|
||||
|
||||
- name: Install dependencies
|
||||
# NOTE: this action runs only on cache miss to refresh the dependencies and make sure the next Haystack install will be faster.
|
||||
@ -53,4 +53,4 @@ runs:
|
||||
pip install .[all]
|
||||
pip install rest_api/
|
||||
pip install ui/
|
||||
pip install torch-scatter -f https://data.pyg.org/whl/torch-1.12.0+cpu.html
|
||||
pip install torch-scatter -f https://data.pyg.org/whl/torch-1.12.0+cpu.html
|
||||
|
||||
@ -17,7 +17,7 @@ repos:
|
||||
#- id: pretty-format-json # indents and sorts JSON files # FIXME: JSON schema generator conflicts with this
|
||||
|
||||
- repo: https://github.com/psf/black
|
||||
rev: 22.6.0 # IMPORTANT: keep this aligned with the black version in setup.cfg
|
||||
rev: 22.6.0 # IMPORTANT: keep this aligned with the black version in pyproject.toml
|
||||
hooks:
|
||||
- id: black-jupyter
|
||||
|
||||
|
||||
@ -54,7 +54,7 @@ pip install --upgrade pip
|
||||
# Install Haystack in editable mode
|
||||
pip install -e '.[dev]'
|
||||
```
|
||||
Note that the `.[dev]` part is enough in many development scenarios when adding minor code fixes. However, if your changes require a schema change, then you'll need to install all dependencies with `pip install -e '.[all]' ` command. Introducing new components or changing their interface requires a schema change.
|
||||
Note that the `.[dev]` part is enough in many development scenarios when adding minor code fixes. However, if your changes require a schema change, then you'll need to install all dependencies with `pip install -e '.[all]' ` command. Introducing new components or changing their interface requires a schema change.
|
||||
This will install all the dependencies you need to work on the codebase, plus testing and formatting dependencies.
|
||||
|
||||
Last, install the pre-commit hooks with:
|
||||
@ -287,7 +287,7 @@ You can run it with `python -m black .` from the root folder.
|
||||
|
||||
### Mypy
|
||||
|
||||
Mypy currently runs with limited configuration options that can be found at the bottom of `setup.cfg`.
|
||||
Mypy currently runs with limited configuration options that can be found at the bottom of `pyproject.toml`.
|
||||
|
||||
You can run it with `python -m mypy haystack/ rest_api/ ui/` from the root folder.
|
||||
|
||||
|
||||
@ -20,7 +20,7 @@ RUN wget --no-check-certificate https://dl.xpdfreader.com/xpdf-tools-linux-4.04.
|
||||
# Copy Haystack code
|
||||
COPY haystack /home/user/haystack/
|
||||
# Copy package files & models
|
||||
COPY setup.py setup.cfg pyproject.toml VERSION.txt LICENSE README.md models* /home/user/
|
||||
COPY pyproject.toml VERSION.txt LICENSE README.md models* /home/user/
|
||||
# Copy REST API code
|
||||
COPY rest_api /home/user/rest_api/
|
||||
|
||||
|
||||
@ -35,7 +35,7 @@ RUN update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.7 1
|
||||
# Copy Haystack code
|
||||
COPY haystack /home/user/haystack/
|
||||
# Copy package files & models
|
||||
COPY setup.py setup.cfg pyproject.toml VERSION.txt LICENSE README.md models* /home/user/
|
||||
COPY pyproject.toml VERSION.txt LICENSE README.md models* /home/user/
|
||||
# Copy REST API code
|
||||
COPY rest_api /home/user/rest_api/
|
||||
|
||||
|
||||
@ -25,7 +25,7 @@ RUN apt-get update && apt-get install -y software-properties-common && \
|
||||
| tar -xvzf - -C /usr/local/bin --strip-components=2 xpdf-tools-linux-4.04/bin64/pdftotext
|
||||
|
||||
# Copy Haystack package files but not the source code
|
||||
COPY setup.py setup.cfg pyproject.toml VERSION.txt LICENSE README.md /home/user/
|
||||
COPY pyproject.toml VERSION.txt LICENSE README.md /home/user/
|
||||
|
||||
# Install all the dependencies, including ocr component
|
||||
RUN pip3 install --upgrade --no-cache-dir pip && \
|
||||
|
||||
23
README.md
23
README.md
@ -26,7 +26,7 @@
|
||||
</a>
|
||||
<a href="https://twitter.com/intent/follow?screen_name=deepset_ai">
|
||||
<img alt="Twitter" src="https://img.shields.io/twitter/follow/deepset_ai?style=social">
|
||||
</a>
|
||||
</a>
|
||||
</p>
|
||||
|
||||
Haystack is an end-to-end framework that enables you to build powerful and production-ready pipelines for different search use cases.
|
||||
@ -99,7 +99,7 @@ If you cannot upgrade `pip` to version 21.3 or higher, you will need to replace:
|
||||
- `'.[all]'` with `'.[sql,only-faiss,only-milvus1,weaviate,graphdb,crawler,preprocessing,ocr,onnx,ray,dev]'`
|
||||
- `'.[all-gpu]'` with `'.[sql,only-faiss-gpu,only-milvus1,weaviate,graphdb,crawler,preprocessing,ocr,onnx-gpu,ray,dev]'`
|
||||
|
||||
For an complete list of the dependency groups available, have a look at the `haystack/setup.cfg` file.
|
||||
For an complete list of the dependency groups available, have a look at the `haystack/pyproject.toml` file.
|
||||
|
||||
To install the REST API and UI, run the following from the root directory of the Haystack repo
|
||||
|
||||
@ -130,15 +130,15 @@ GRPC_PYTHON_BUILD_SYSTEM_ZLIB=true pip install git+https://github.com/deepset-ai
|
||||
|
||||
**5. Learn More**
|
||||
|
||||
See our [installation guide](https://haystack.deepset.ai/overview/get-started) for more options.
|
||||
You can find out more about our PyPi package on our [PyPi page](https://pypi.org/project/farm-haystack/).
|
||||
See our [installation guide](https://haystack.deepset.ai/overview/get-started) for more options.
|
||||
You can find out more about our PyPi package on our [PyPi page](https://pypi.org/project/farm-haystack/).
|
||||
|
||||
## :mortar_board: Tutorials
|
||||
|
||||
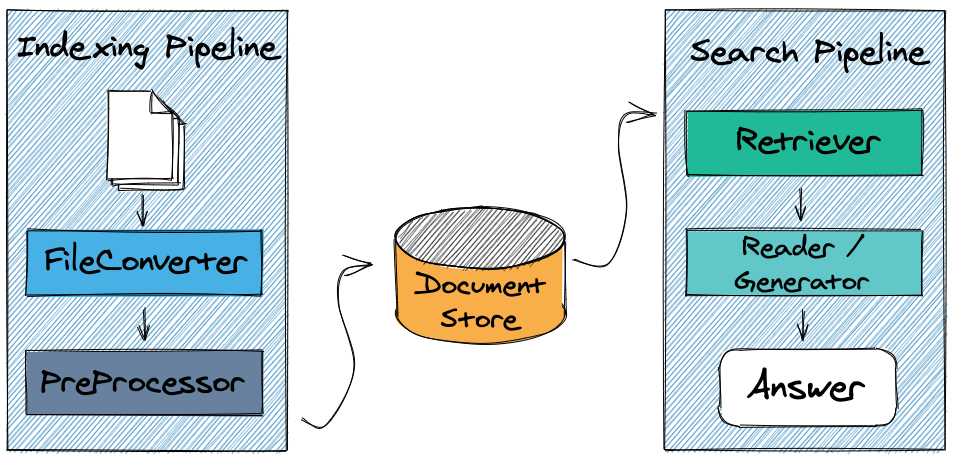
|
||||
|
||||
Follow our [introductory tutorial](https://haystack.deepset.ai/tutorials/first-qa-system)
|
||||
to setup a question answering system using Python and start performing queries!
|
||||
Follow our [introductory tutorial](https://haystack.deepset.ai/tutorials/first-qa-system)
|
||||
to setup a question answering system using Python and start performing queries!
|
||||
Explore the rest of our tutorials to learn how to tweak pipelines, train models and perform evaluation.
|
||||
|
||||
- Tutorial 1 - Basic QA Pipeline: [Jupyter notebook](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial1_Basic_QA_Pipeline.ipynb)
|
||||
@ -251,7 +251,7 @@ Explore the rest of our tutorials to learn how to tweak pipelines, train models
|
||||
**Hosted**
|
||||
|
||||
Try out our hosted [Explore The World](https://haystack-demo.deepset.ai/) live demo here!
|
||||
Ask any question on countries or capital cities and let Haystack return the answers to you.
|
||||
Ask any question on countries or capital cities and let Haystack return the answers to you.
|
||||
|
||||
**Local**
|
||||
|
||||
@ -280,7 +280,7 @@ With this you can begin calling it directly via the REST API or even interact wi
|
||||
cd haystack
|
||||
docker-compose pull
|
||||
docker-compose up
|
||||
|
||||
|
||||
# Or on a GPU machine: docker-compose -f docker-compose-gpu.yml up
|
||||
```
|
||||
|
||||
@ -318,15 +318,15 @@ Please note that the demo will [publish](https://docs.docker.com/config/containe
|
||||
There is a very vibrant and active community around Haystack which we are regularly interacting with!
|
||||
If you have a feature request or a bug report, feel free to open an [issue in Github](https://github.com/deepset-ai/haystack/issues).
|
||||
We regularly check these and you can expect a quick response.
|
||||
If you'd like to discuss a topic, or get more general advice on how to make Haystack work for your project,
|
||||
If you'd like to discuss a topic, or get more general advice on how to make Haystack work for your project,
|
||||
you can start a thread in [Github Discussions](https://github.com/deepset-ai/haystack/discussions) or our [Discord channel](https://haystack.deepset.ai/community/join).
|
||||
We also check [Twitter](https://twitter.com/deepset_ai) and [Stack Overflow](https://stackoverflow.com/questions/tagged/haystack).
|
||||
|
||||
|
||||
## :heart: Contributing
|
||||
|
||||
We are very open to the community's contributions - be it a quick fix of a typo, or a completely new feature!
|
||||
You don't need to be a Haystack expert to provide meaningful improvements.
|
||||
We are very open to the community's contributions - be it a quick fix of a typo, or a completely new feature!
|
||||
You don't need to be a Haystack expert to provide meaningful improvements.
|
||||
To learn how to get started, check out our [Contributor Guidelines](https://github.com/deepset-ai/haystack/blob/master/CONTRIBUTING.md) first.
|
||||
You can also find instructions to run the tests locally there.
|
||||
|
||||
@ -348,4 +348,3 @@ Here's a list of organizations who use Haystack. Don't hesitate to send a PR to
|
||||
- [Etalab](https://www.etalab.gouv.fr/)
|
||||
- [Infineon](https://www.infineon.com/)
|
||||
- [Sooth.ai](https://sooth.ai/)
|
||||
|
||||
|
||||
@ -18,8 +18,9 @@ logger = logging.getLogger(__name__)
|
||||
def safe_import(import_path: str, classname: str, dep_group: str):
|
||||
"""
|
||||
Method that allows the import of nodes that depend on missing dependencies.
|
||||
These nodes can be installed one by one with extras_require (see setup.cfg)
|
||||
but they need to be all imported in their respective package's __init__()
|
||||
These nodes can be installed one by one with project.optional-dependencies
|
||||
(see pyproject.toml) but they need to be all imported in their respective
|
||||
package's __init__()
|
||||
|
||||
Therefore, in case of an ImportError, the class to import is replaced by
|
||||
a hollow MissingDependency function, which will throw an error when
|
||||
|
||||
294
pyproject.toml
294
pyproject.toml
@ -1,10 +1,256 @@
|
||||
[build-system]
|
||||
requires = [
|
||||
"setuptools",
|
||||
"wheel",
|
||||
"hatchling>=1.8.0",
|
||||
]
|
||||
build-backend = "setuptools.build_meta"
|
||||
build-backend = "hatchling.build"
|
||||
|
||||
[project]
|
||||
name = "farm-haystack"
|
||||
dynamic = [
|
||||
"version",
|
||||
]
|
||||
description = "Neural Question Answering & Semantic Search at Scale. Use modern transformer based models like BERT to find answers in large document collections"
|
||||
readme = "README.md"
|
||||
license = "Apache-2.0"
|
||||
requires-python = ">=3.7"
|
||||
authors = [
|
||||
{ name = "deepset.ai", email = "malte.pietsch@deepset.ai" },
|
||||
]
|
||||
keywords = [
|
||||
"BERT",
|
||||
"QA",
|
||||
"Question-Answering",
|
||||
"Reader",
|
||||
"Retriever",
|
||||
"albert",
|
||||
"language-model",
|
||||
"mrc",
|
||||
"roberta",
|
||||
"search",
|
||||
"semantic-search",
|
||||
"squad",
|
||||
"transfer-learning",
|
||||
"transformer",
|
||||
]
|
||||
classifiers = [
|
||||
"Development Status :: 5 - Production/Stable",
|
||||
"Intended Audience :: Science/Research",
|
||||
"License :: Freely Distributable",
|
||||
"License :: OSI Approved :: Apache Software License",
|
||||
"Operating System :: OS Independent",
|
||||
"Programming Language :: Python",
|
||||
"Programming Language :: Python :: 3",
|
||||
"Programming Language :: Python :: 3.7",
|
||||
"Programming Language :: Python :: 3.8",
|
||||
"Programming Language :: Python :: 3.9",
|
||||
"Programming Language :: Python :: 3.10",
|
||||
"Topic :: Scientific/Engineering :: Artificial Intelligence",
|
||||
]
|
||||
dependencies = [
|
||||
"importlib-metadata; python_version < '3.8'",
|
||||
"torch>1.9,<1.13",
|
||||
"requests",
|
||||
"pydantic",
|
||||
"transformers==4.20.1",
|
||||
"nltk",
|
||||
"pandas",
|
||||
|
||||
# Utils
|
||||
"dill", # pickle extension for (de-)serialization
|
||||
"tqdm", # progress bars in model download and training scripts
|
||||
"networkx", # graphs library
|
||||
"mmh3", # fast hashing function (murmurhash3)
|
||||
"quantulum3", # quantities extraction from text
|
||||
"posthog", # telemetry
|
||||
"azure-ai-formrecognizer==3.2.0b2", # forms reader
|
||||
# audio's espnet-model-zoo requires huggingface-hub version <0.8 while we need >=0.5 to be able to use create_repo in FARMReader
|
||||
"huggingface-hub<0.8.0,>=0.5.0",
|
||||
|
||||
# Preprocessing
|
||||
"more_itertools", # for windowing
|
||||
"python-docx",
|
||||
"langdetect", # for PDF conversions
|
||||
"tika", # Apache Tika (text & metadata extractor)
|
||||
|
||||
# See haystack/nodes/retriever/_embedding_encoder.py, _SentenceTransformersEmbeddingEncoder
|
||||
"sentence-transformers>=2.2.0",
|
||||
|
||||
# for stats in run_classifier
|
||||
"scipy>=1.3.2",
|
||||
"scikit-learn>=1.0.0",
|
||||
|
||||
# Metrics and logging
|
||||
"seqeval",
|
||||
"mlflow",
|
||||
|
||||
# Elasticsearch
|
||||
"elasticsearch>=7.7,<7.11",
|
||||
"elastic-apm",
|
||||
|
||||
# context matching
|
||||
"rapidfuzz>=2.0.15,<3",
|
||||
|
||||
# Schema validation
|
||||
"jsonschema",
|
||||
]
|
||||
|
||||
[project.optional-dependencies]
|
||||
sql = [
|
||||
"sqlalchemy>=1.4.2,<2",
|
||||
"sqlalchemy_utils",
|
||||
"psycopg2-binary; platform_system != 'Windows'",
|
||||
]
|
||||
only-faiss = [
|
||||
"faiss-cpu>=1.6.3,<2",
|
||||
]
|
||||
faiss = [
|
||||
"farm-haystack[sql,only-faiss]",
|
||||
]
|
||||
only-faiss-gpu = [
|
||||
"faiss-gpu>=1.6.3,<2",
|
||||
]
|
||||
faiss-gpu = [
|
||||
"farm-haystack[sql,only-faiss-gpu]",
|
||||
]
|
||||
only-milvus1 = [
|
||||
"pymilvus<2.0.0", # Refer milvus version support matrix at https://github.com/milvus-io/pymilvus#install-pymilvus
|
||||
]
|
||||
milvus1 = [
|
||||
"farm-haystack[sql,only-milvus1]",
|
||||
]
|
||||
only-milvus = [
|
||||
"pymilvus>=2.0.0,<3", # Refer milvus version support matrix at https://github.com/milvus-io/pymilvus#install-pymilvus
|
||||
]
|
||||
milvus = [
|
||||
"farm-haystack[sql,only-milvus]",
|
||||
]
|
||||
weaviate = [
|
||||
"weaviate-client==3.6.0",
|
||||
]
|
||||
only-pinecone = [
|
||||
"pinecone-client",
|
||||
]
|
||||
pinecone = [
|
||||
"farm-haystack[sql,only-pinecone]",
|
||||
]
|
||||
graphdb = [
|
||||
"SPARQLWrapper",
|
||||
]
|
||||
inmemorygraph = [
|
||||
"SPARQLWrapper",
|
||||
]
|
||||
opensearch = [
|
||||
"opensearch-py>=2",
|
||||
]
|
||||
docstores = [
|
||||
"farm-haystack[faiss,milvus,weaviate,graphdb,inmemorygraph,pinecone,opensearch]",
|
||||
]
|
||||
docstores-gpu = [
|
||||
"farm-haystack[faiss-gpu,milvus,weaviate,graphdb,inmemorygraph,pinecone,opensearch]",
|
||||
]
|
||||
audio = [
|
||||
"pyworld<=0.2.12",
|
||||
"espnet",
|
||||
"espnet-model-zoo",
|
||||
"pydub",
|
||||
]
|
||||
beir = [
|
||||
"beir; platform_system != 'Windows'",
|
||||
]
|
||||
crawler = [
|
||||
"selenium>=4.0.0,!=4.1.4", # Avoid 4.1.4 due to https://github.com/SeleniumHQ/selenium/issues/10612
|
||||
"webdriver-manager",
|
||||
]
|
||||
preprocessing = [
|
||||
"beautifulsoup4",
|
||||
"markdown",
|
||||
"python-magic; platform_system != 'Windows'", # Depends on libmagic: https://pypi.org/project/python-magic/
|
||||
"python-magic-bin; platform_system == 'Windows'", # Needs to be installed without python-magic, otherwise Windows CI gets stuck.
|
||||
]
|
||||
ocr = [
|
||||
"pytesseract==0.3.7",
|
||||
"pillow",
|
||||
"pdf2image==1.14.0",
|
||||
]
|
||||
onnx = [
|
||||
"onnxruntime",
|
||||
"onnxruntime_tools",
|
||||
]
|
||||
onnx-gpu = [
|
||||
"onnxruntime-gpu",
|
||||
"onnxruntime_tools",
|
||||
]
|
||||
ray = [
|
||||
"ray>=1.9.1,<2; platform_system != 'Windows'",
|
||||
"ray>=1.9.1,<2,!=1.12.0; platform_system == 'Windows'", # Avoid 1.12.0 due to https://github.com/ray-project/ray/issues/24169 (fails on windows)
|
||||
"aiorwlock>=1.3.0,<2",
|
||||
]
|
||||
colab = [
|
||||
"grpcio==1.47.0",
|
||||
"requests>=2.25", # Needed to avoid dependency conflict with crawler https://github.com/deepset-ai/haystack/pull/2921
|
||||
]
|
||||
dev = [
|
||||
"pre-commit",
|
||||
# Type check
|
||||
"mypy",
|
||||
"typing_extensions; python_version < '3.8'",
|
||||
# Test
|
||||
"pytest",
|
||||
"pytest-custom_exit_code", # used in the CI
|
||||
"responses",
|
||||
"tox",
|
||||
"coverage",
|
||||
"python-multipart",
|
||||
"psutil",
|
||||
# Linting
|
||||
"pylint",
|
||||
# Code formatting
|
||||
"black[jupyter]==22.6.0",
|
||||
# Documentation
|
||||
"pydoc-markdown==4.5.1", # FIXME Unpin!
|
||||
# azure-core is a dependency of azure-ai-formrecognizer
|
||||
# In order to stop malicious pip backtracking during pip install farm-haystack[all] documented in https://github.com/deepset-ai/haystack/issues/2280
|
||||
# we have to resolve a dependency version conflict ourself.
|
||||
# azure-core>=1.23 conflicts with pydoc-markdown's dependency on databind>=1.5.0 which itself requires typing-extensions<4.0.0
|
||||
# azure-core>=1.23 needs typing-extensions>=4.0.1
|
||||
# pip unfortunately backtracks into the databind direction ultimately getting lost.
|
||||
"azure-core<1.23",
|
||||
"mkdocs",
|
||||
"jupytercontrib",
|
||||
"watchdog", # ==1.0.2
|
||||
"requests-cache",
|
||||
]
|
||||
test = [
|
||||
"farm-haystack[docstores,audio,crawler,preprocessing,ocr,ray,dev]",
|
||||
]
|
||||
all = [
|
||||
"farm-haystack[docstores,audio,crawler,preprocessing,ocr,ray,dev,onnx,beir]",
|
||||
]
|
||||
all-gpu = [
|
||||
"farm-haystack[docstores-gpu,audio,crawler,preprocessing,ocr,ray,dev,onnx-gpu,beir]",
|
||||
]
|
||||
|
||||
[project.urls]
|
||||
"CI: GitHub" = "https://github.com/deepset-ai/haystack/actions"
|
||||
"Docs: RTD" = "https://haystack.deepset.ai/overview/intro"
|
||||
"GitHub: issues" = "https://github.com/deepset-ai/haystack/issues"
|
||||
"GitHub: repo" = "https://github.com/deepset-ai/haystack"
|
||||
Homepage = "https://github.com/deepset-ai/haystack"
|
||||
|
||||
[tool.hatch.version]
|
||||
path = "VERSION.txt"
|
||||
pattern = "(?P<version>.+)"
|
||||
|
||||
[tool.hatch.build.targets.sdist]
|
||||
include = [
|
||||
"/haystack",
|
||||
"/VERSION.txt",
|
||||
]
|
||||
|
||||
[tool.hatch.build.targets.wheel]
|
||||
packages = [
|
||||
"haystack",
|
||||
]
|
||||
|
||||
[tool.black]
|
||||
line-length = 120
|
||||
@ -89,24 +335,32 @@ min-similarity-lines=6
|
||||
minversion = "6.0"
|
||||
addopts = "--strict-markers"
|
||||
markers = [
|
||||
"integration: integration tests",
|
||||
"unit: unit tests",
|
||||
"integration: integration tests",
|
||||
"unit: unit tests",
|
||||
|
||||
"generator: generator tests",
|
||||
"summarizer: summarizer tests",
|
||||
"embedding_dim: uses a document store with non-default embedding dimension (e.g @pytest.mark.embedding_dim(128))",
|
||||
"generator: generator tests",
|
||||
"summarizer: summarizer tests",
|
||||
"embedding_dim: uses a document store with non-default embedding dimension (e.g @pytest.mark.embedding_dim(128))",
|
||||
|
||||
"tika: requires Tika container",
|
||||
"parsr: requires Parsr container",
|
||||
"ocr: requires Tesseract",
|
||||
"tika: requires Tika container",
|
||||
"parsr: requires Parsr container",
|
||||
"ocr: requires Tesseract",
|
||||
|
||||
"elasticsearch: requires Elasticsearch container",
|
||||
"graphdb: requires GraphDB container",
|
||||
"weaviate: requires Weaviate container",
|
||||
"pinecone: requires Pinecone credentials",
|
||||
"faiss: uses FAISS",
|
||||
"milvus: requires a Milvus 2 setup",
|
||||
"milvus1: requires a Milvus 1 container",
|
||||
"opensearch"
|
||||
"elasticsearch: requires Elasticsearch container",
|
||||
"graphdb: requires GraphDB container",
|
||||
"weaviate: requires Weaviate container",
|
||||
"pinecone: requires Pinecone credentials",
|
||||
"faiss: uses FAISS",
|
||||
"milvus: requires a Milvus 2 setup",
|
||||
"milvus1: requires a Milvus 1 container",
|
||||
"opensearch",
|
||||
]
|
||||
log_cli = true
|
||||
|
||||
[tool.mypy]
|
||||
warn_return_any = false
|
||||
warn_unused_configs = true
|
||||
ignore_missing_imports = true
|
||||
plugins = [
|
||||
"pydantic.mypy",
|
||||
]
|
||||
log_cli = true
|
||||
262
setup.cfg
262
setup.cfg
@ -1,262 +0,0 @@
|
||||
[metadata]
|
||||
name = farm-haystack
|
||||
version = file: VERSION.txt
|
||||
url = https://github.com/deepset-ai/haystack
|
||||
project_urls =
|
||||
Docs: RTD = https://haystack.deepset.ai/overview/intro
|
||||
CI: GitHub = https://github.com/deepset-ai/haystack/actions
|
||||
GitHub: issues = https://github.com/deepset-ai/haystack/issues
|
||||
GitHub: repo = https://github.com/deepset-ai/haystack
|
||||
description = Neural Question Answering & Semantic Search at Scale. Use modern transformer based models like BERT to find answers in large document collections
|
||||
long_description = file: README.md
|
||||
long_description_content_type = text/markdown
|
||||
keywords=
|
||||
QA
|
||||
Question-Answering
|
||||
Reader
|
||||
Retriever
|
||||
semantic-search
|
||||
search
|
||||
BERT
|
||||
roberta
|
||||
albert
|
||||
squad
|
||||
mrc
|
||||
transfer-learning
|
||||
language-model
|
||||
transformer
|
||||
author = deepset.ai
|
||||
author_email = malte.pietsch@deepset.ai
|
||||
license = Apache License 2.0
|
||||
license_file = LICENSE
|
||||
platforms = any
|
||||
classifiers =
|
||||
Development Status :: 5 - Production/Stable
|
||||
Intended Audience :: Science/Research
|
||||
License :: Freely Distributable
|
||||
License :: OSI Approved :: Apache Software License
|
||||
Topic :: Scientific/Engineering :: Artificial Intelligence
|
||||
Operating System :: OS Independent
|
||||
Programming Language :: Python
|
||||
Programming Language :: Python :: 3
|
||||
Programming Language :: Python :: 3.7
|
||||
Programming Language :: Python :: 3.8
|
||||
Programming Language :: Python :: 3.9
|
||||
Programming Language :: Python :: 3.10
|
||||
|
||||
[options]
|
||||
use_scm_version = True
|
||||
python_requires = >=3.7, <4
|
||||
packages = find:
|
||||
setup_requires =
|
||||
setuptools
|
||||
wheel
|
||||
install_requires =
|
||||
importlib-metadata; python_version < '3.8'
|
||||
torch>1.9,<1.13
|
||||
requests
|
||||
pydantic
|
||||
transformers==4.20.1
|
||||
nltk
|
||||
pandas
|
||||
|
||||
# Utils
|
||||
dill # pickle extension for (de-)serialization
|
||||
tqdm # progress bars in model download and training scripts
|
||||
networkx # graphs library
|
||||
mmh3 # fast hashing function (murmurhash3)
|
||||
quantulum3 # quantities extraction from text
|
||||
posthog # telemetry
|
||||
azure-ai-formrecognizer==3.2.0b2 # forms reader
|
||||
# audio's espnet-model-zoo requires huggingface-hub version <0.8 while we need >=0.5 to be able to use create_repo in FARMReader
|
||||
huggingface-hub<0.8.0,>=0.5.0
|
||||
|
||||
# Preprocessing
|
||||
more_itertools # for windowing
|
||||
python-docx
|
||||
langdetect # for PDF conversions
|
||||
tika # Apache Tika (text & metadata extractor)
|
||||
|
||||
# See haystack/nodes/retriever/_embedding_encoder.py, _SentenceTransformersEmbeddingEncoder
|
||||
sentence-transformers>=2.2.0
|
||||
|
||||
# for stats in run_classifier
|
||||
scipy>=1.3.2
|
||||
scikit-learn>=1.0.0
|
||||
|
||||
# Metrics and logging
|
||||
seqeval
|
||||
mlflow
|
||||
|
||||
# Elasticsearch
|
||||
elasticsearch>=7.7,<7.11
|
||||
elastic-apm
|
||||
|
||||
# context matching
|
||||
rapidfuzz>=2.0.15,<3
|
||||
|
||||
# Schema validation
|
||||
jsonschema
|
||||
|
||||
|
||||
[options.packages.find]
|
||||
exclude =
|
||||
rest_api*
|
||||
test*
|
||||
tutorials*
|
||||
ui*
|
||||
|
||||
|
||||
[options.package_data]
|
||||
haystack =
|
||||
json-schemas/*.schema.json
|
||||
|
||||
|
||||
[options.extras_require]
|
||||
sql =
|
||||
sqlalchemy>=1.4.2,<2
|
||||
sqlalchemy_utils
|
||||
psycopg2-binary; platform_system != 'Windows'
|
||||
only-faiss =
|
||||
faiss-cpu>=1.6.3,<2
|
||||
faiss =
|
||||
farm-haystack[sql,only-faiss]
|
||||
only-faiss-gpu =
|
||||
faiss-gpu>=1.6.3,<2
|
||||
faiss-gpu =
|
||||
farm-haystack[sql,only-faiss-gpu]
|
||||
only-milvus1 =
|
||||
pymilvus<2.0.0 # Refer milvus version support matrix at https://github.com/milvus-io/pymilvus#install-pymilvus
|
||||
milvus1 =
|
||||
farm-haystack[sql,only-milvus1]
|
||||
only-milvus =
|
||||
pymilvus>=2.0.0,<3 # Refer milvus version support matrix at https://github.com/milvus-io/pymilvus#install-pymilvus
|
||||
milvus =
|
||||
farm-haystack[sql,only-milvus]
|
||||
weaviate =
|
||||
weaviate-client==3.6.0
|
||||
only-pinecone =
|
||||
pinecone-client
|
||||
pinecone =
|
||||
farm-haystack[sql,only-pinecone]
|
||||
graphdb =
|
||||
SPARQLWrapper
|
||||
inmemorygraph =
|
||||
SPARQLWrapper
|
||||
opensearch =
|
||||
opensearch-py>=2
|
||||
docstores =
|
||||
farm-haystack[faiss,milvus,weaviate,graphdb,inmemorygraph,pinecone,opensearch]
|
||||
docstores-gpu =
|
||||
farm-haystack[faiss-gpu,milvus,weaviate,graphdb,inmemorygraph,pinecone,opensearch]
|
||||
|
||||
audio =
|
||||
pyworld<=0.2.12
|
||||
espnet
|
||||
espnet-model-zoo
|
||||
pydub
|
||||
beir =
|
||||
beir; platform_system != 'Windows'
|
||||
crawler =
|
||||
selenium>=4.0.0,!=4.1.4 # Avoid 4.1.4 due to https://github.com/SeleniumHQ/selenium/issues/10612
|
||||
webdriver-manager
|
||||
preprocessing =
|
||||
beautifulsoup4
|
||||
markdown
|
||||
python-magic; platform_system != 'Windows' # Depends on libmagic: https://pypi.org/project/python-magic/
|
||||
python-magic-bin; platform_system == 'Windows' # Needs to be installed without python-magic, otherwise Windows CI gets stuck.
|
||||
ocr =
|
||||
pytesseract==0.3.7
|
||||
pillow
|
||||
pdf2image==1.14.0
|
||||
onnx =
|
||||
onnxruntime
|
||||
onnxruntime_tools
|
||||
onnx-gpu =
|
||||
onnxruntime-gpu
|
||||
onnxruntime_tools
|
||||
ray =
|
||||
ray>=1.9.1,<2; platform_system != 'Windows'
|
||||
ray>=1.9.1,<2,!=1.12.0; platform_system == 'Windows' # Avoid 1.12.0 due to https://github.com/ray-project/ray/issues/24169 (fails on windows)
|
||||
aiorwlock>=1.3.0,<2
|
||||
|
||||
colab =
|
||||
grpcio==1.47.0
|
||||
requests>=2.25 # Needed to avoid dependency conflict with crawler https://github.com/deepset-ai/haystack/pull/2921
|
||||
dev =
|
||||
pre-commit
|
||||
# Type check
|
||||
mypy
|
||||
typing_extensions; python_version < '3.8'
|
||||
# Test
|
||||
pytest
|
||||
pytest-custom_exit_code # used in the CI
|
||||
responses
|
||||
tox
|
||||
coverage
|
||||
python-multipart
|
||||
psutil
|
||||
# Linting
|
||||
pylint
|
||||
# Code formatting
|
||||
black[jupyter]==22.6.0
|
||||
# Documentation
|
||||
pydoc-markdown==4.5.1 # FIXME Unpin!
|
||||
# azure-core is a dependency of azure-ai-formrecognizer
|
||||
# In order to stop malicious pip backtracking during pip install farm-haystack[all] documented in https://github.com/deepset-ai/haystack/issues/2280
|
||||
# we have to resolve a dependency version conflict ourself.
|
||||
# azure-core>=1.23 conflicts with pydoc-markdown's dependency on databind>=1.5.0 which itself requires typing-extensions<4.0.0
|
||||
# azure-core>=1.23 needs typing-extensions>=4.0.1
|
||||
# pip unfortunately backtracks into the databind direction ultimately getting lost.
|
||||
azure-core<1.23
|
||||
mkdocs
|
||||
jupytercontrib
|
||||
watchdog #==1.0.2
|
||||
requests-cache
|
||||
test =
|
||||
farm-haystack[docstores,audio,crawler,preprocessing,ocr,ray,dev]
|
||||
all =
|
||||
farm-haystack[docstores,audio,crawler,preprocessing,ocr,ray,dev,onnx,beir]
|
||||
all-gpu =
|
||||
farm-haystack[docstores-gpu,audio,crawler,preprocessing,ocr,ray,dev,onnx-gpu,beir]
|
||||
|
||||
|
||||
[tool:pytest]
|
||||
testpaths =
|
||||
test
|
||||
rest_api/test
|
||||
ui/test
|
||||
python_files =
|
||||
test_*.py
|
||||
addopts =
|
||||
-vv
|
||||
|
||||
|
||||
[mypy]
|
||||
warn_return_any = false
|
||||
warn_unused_configs = true
|
||||
ignore_missing_imports = true
|
||||
plugins = pydantic.mypy
|
||||
|
||||
|
||||
[tox]
|
||||
requires = tox-venv
|
||||
setuptools >= 30.0.0
|
||||
envlist = py36,py37
|
||||
|
||||
|
||||
[testenv]
|
||||
changedir = test
|
||||
deps =
|
||||
coverage
|
||||
pytest
|
||||
pandas
|
||||
setenv =
|
||||
COVERAGE_FILE = test-reports/.coverage
|
||||
PYTEST_ADDOPTS = --junitxml=test-reports/{envname}/junit.xml -vv
|
||||
commands =
|
||||
coverage run --source haystack --parallel-mode -m pytest {posargs}
|
||||
coverage combine
|
||||
coverage report -m
|
||||
coverage html -d test-reports/coverage-html
|
||||
coverage xml -o test-reports/coverage.xml
|
||||
6
setup.py
6
setup.py
@ -1,6 +0,0 @@
|
||||
# setup.py will still be needed for a while to allow editable installs (pip < 21.1).
|
||||
# Check regularly in the future if this is still the case, or it can be safely removed.
|
||||
from setuptools import setup
|
||||
|
||||
|
||||
setup()
|
||||
18
tox.ini
Normal file
18
tox.ini
Normal file
@ -0,0 +1,18 @@
|
||||
[tox]
|
||||
isolated_build = true
|
||||
envlist = py37
|
||||
|
||||
|
||||
[testenv]
|
||||
changedir = test
|
||||
extras =
|
||||
test
|
||||
setenv =
|
||||
COVERAGE_FILE = test-reports/.coverage
|
||||
PYTEST_ADDOPTS = --junitxml=test-reports/{envname}/junit.xml -vv
|
||||
commands =
|
||||
coverage run --source haystack --parallel-mode -m pytest {posargs}
|
||||
coverage combine
|
||||
coverage report -m
|
||||
coverage html -d test-reports/coverage-html
|
||||
coverage xml -o test-reports/coverage.xml
|
||||
Loading…
x
Reference in New Issue
Block a user