* add time and perf benchmark for es * Add retriever benchmarking * Add Reader benchmarking * add nq to squad conversion * add conversion stats * clean benchmarks * Add link to dataset * Update imports * add first support for neg psgs * Refactor test * set max_seq_len * cleanup benchmark * begin retriever speed benchmarking * Add support for retriever query index benchmarking * improve reader eval, retriever speed benchmarking * improve retriever speed benchmarking * Add retriever accuracy benchmark * Add neg doc shuffling * Add top_n * 3x speedup of SQL. add postgres docker run. make shuffle neg a param. add more logging * Add models to sweep * add option for faiss index type * remove unneeded line * change faiss to faiss_flat * begin automatic benchmark script * remove existing postgres docker for benchmarking * Add data processing scripts * Remove shuffle in script bc data already shuffled * switch hnsw setup from 256 to 128 * change es similarity to dot product by default * Error includes stack trace * Change ES default timeout * remove delete_docs() from timing for indexing * Add support for website export * update website on push to benchmarks * add complete benchmarks results * new json format * removed NaN as is not a valid json token * versioning for docs * unsaved changes * cleaning * cleaning * Edit format of benchmarks data * update also jsons in v0.4.0 Co-authored-by: brandenchan <brandenchan@icloud.com> Co-authored-by: deepset <deepset@Crenolape.localdomain> Co-authored-by: Malte Pietsch <malte.pietsch@deepset.ai>
3.3 KiB
Fine-tuning a Model on Your Own Data
EXECUTABLE VERSION: colab
For many use cases it is sufficient to just use one of the existing public models that were trained on SQuAD or other public QA datasets (e.g. Natural Questions). However, if you have domain-specific questions, fine-tuning your model on custom examples will very likely boost your performance. While this varies by domain, we saw that ~ 2000 examples can easily increase performance by +5-20%.
This tutorial shows you how to fine-tune a pretrained model on your own dataset.
# Install the latest release of Haystack in your own environment
#! pip install farm-haystack
# Install the latest master of Haystack and install the version of torch that works with the colab GPUs
!pip install git+https://github.com/deepset-ai/haystack.git
!pip install torch==1.6.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html
from haystack.reader.farm import FARMReader
Create Training Data
There are two ways to generate training data
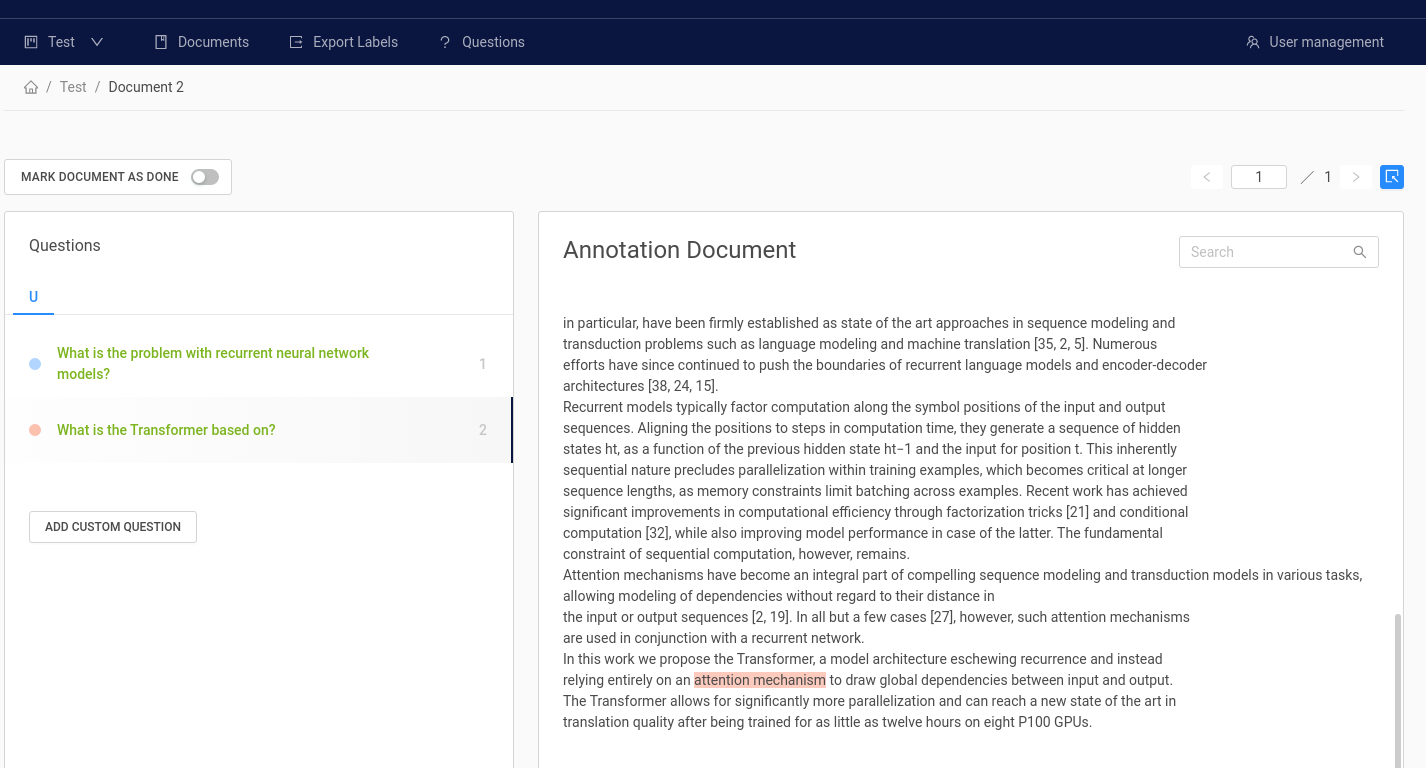
- Annotation: You can use the annotation tool to label your data, i.e. highlighting answers to your questions in a document. The tool supports structuring your workflow with organizations, projects, and users. The labels can be exported in SQuAD format that is compatible for training with Haystack.
- Feedback: For production systems, you can collect training data from direct user feedback via Haystack's REST API interface. This includes a customizable user feedback API for providing feedback on the answer returned by the API. The API provides a feedback export endpoint to obtain the feedback data for fine-tuning your model further.
Fine-tune your model
Once you have collected training data, you can fine-tune your base models. We initialize a reader as a base model and fine-tune it on our own custom dataset (should be in SQuAD-like format). We recommend using a base model that was trained on SQuAD or a similar QA dataset before to benefit from Transfer Learning effects.
Recommendation: Run training on a GPU.
If you are using Colab: Enable this in the menu "Runtime" > "Change Runtime type" > Select "GPU" in dropdown.
Then change the use_gpu arguments below to True
reader = FARMReader(model_name_or_path="distilbert-base-uncased-distilled-squad", use_gpu=True)
train_data = "data/squad20"
# train_data = "PATH/TO_YOUR/TRAIN_DATA"
reader.train(data_dir=train_data, train_filename="dev-v2.0.json", use_gpu=True, n_epochs=1, save_dir="my_model")
# Saving the model happens automatically at the end of training into the `save_dir` you specified
# However, you could also save a reader manually again via:
reader.save(directory="my_model")
# If you want to load it at a later point, just do:
new_reader = FARMReader(model_name_or_path="my_model")