mirror of
https://github.com/infiniflow/ragflow.git
synced 2025-11-12 16:14:26 +00:00
246 lines
13 KiB
Plaintext
246 lines
13 KiB
Plaintext
---
|
||
sidebar_position: 2
|
||
slug: /agent_component
|
||
---
|
||
|
||
# Agent component
|
||
|
||
The component equipped with reasoning, tool usage, and multi-agent collaboration capabilities.
|
||
|
||
---
|
||
|
||
An **Agent** component fine-tunes the LLM and sets its prompt. From v0.20.5 onwards, an **Agent** component is able to work independently and with the following capabilities:
|
||
|
||
- Autonomous reasoning with reflection and adjustment based on environmental feedback.
|
||
- Use of tools or subagents to complete tasks.
|
||
|
||
## Scenarios
|
||
|
||
An **Agent** component is essential when you need the LLM to assist with summarizing, translating, or controlling various tasks.
|
||
|
||
## Prerequisites
|
||
|
||
1. Ensure you have a chat model properly configured:
|
||
|
||

|
||
|
||
2. If your Agent involves dataset retrieval, ensure you [have properly configured your target knowledge base(s)](../../dataset/configure_knowledge_base.md).
|
||
|
||
## Quickstart
|
||
|
||
### 1. Click on an **Agent** component to show its configuration panel
|
||
|
||
The corresponding configuration panel appears to the right of the canvas. Use this panel to define and fine-tune the **Agent** component's behavior.
|
||
|
||
### 2. Select your model
|
||
|
||
Click **Model**, and select a chat model from the dropdown menu.
|
||
|
||
:::tip NOTE
|
||
If no model appears, check if your have added a chat model on the **Model providers** page.
|
||
:::
|
||
|
||
### 3. Update system prompt (Optional)
|
||
|
||
The system prompt typically defines your model's role. You can either keep the system prompt as is or customize it to override the default.
|
||
|
||
|
||
### 4. Update user prompt
|
||
|
||
The user prompt typically defines your model's task. You will find the `sys.query` variable auto-populated. Type `/` or click **(x)** to view or add variables.
|
||
|
||
In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents below), then you may also need to specify retrieved chunks using the `formalized_content` variable:
|
||
|
||
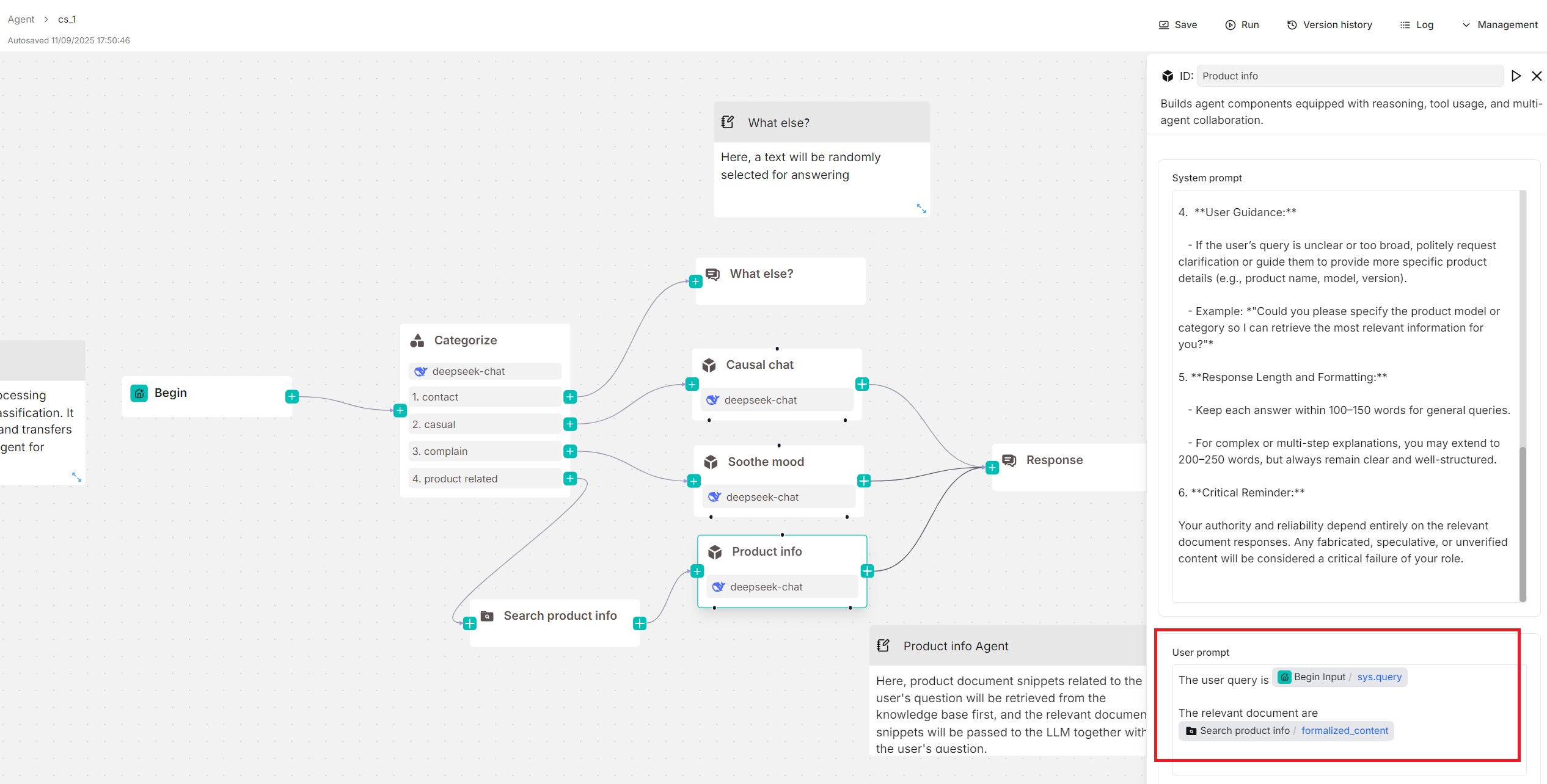
|
||
|
||
### 5. Skip Tools and Agent
|
||
|
||
The **+ Add tools** and **+ Add agent** sections are used *only* when you need to configure your **Agent** component as a planner (with tools or sub-Agents beneath). In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents beneath).
|
||
|
||
### 6. Choose the next component
|
||
|
||
When necessary, click the **+** button on the **Agent** component to choose the next component in the worflow from the dropdown list.
|
||
|
||
## Connect to an MCP server as a client
|
||
|
||
:::danger IMPORTANT
|
||
In this section, we assume your **Agent** will be configured as a planner, with a Tavily tool beneath it.
|
||
:::
|
||
|
||
### 1. Navigate to the MCP configuration page
|
||
|
||

|
||
|
||
### 2. Configure your Tavily MCP server
|
||
|
||
Update your MCP server's name, URL (including the API key), server type, and other necessary settings. When configured correctly, the available tools will be displayed.
|
||
|
||
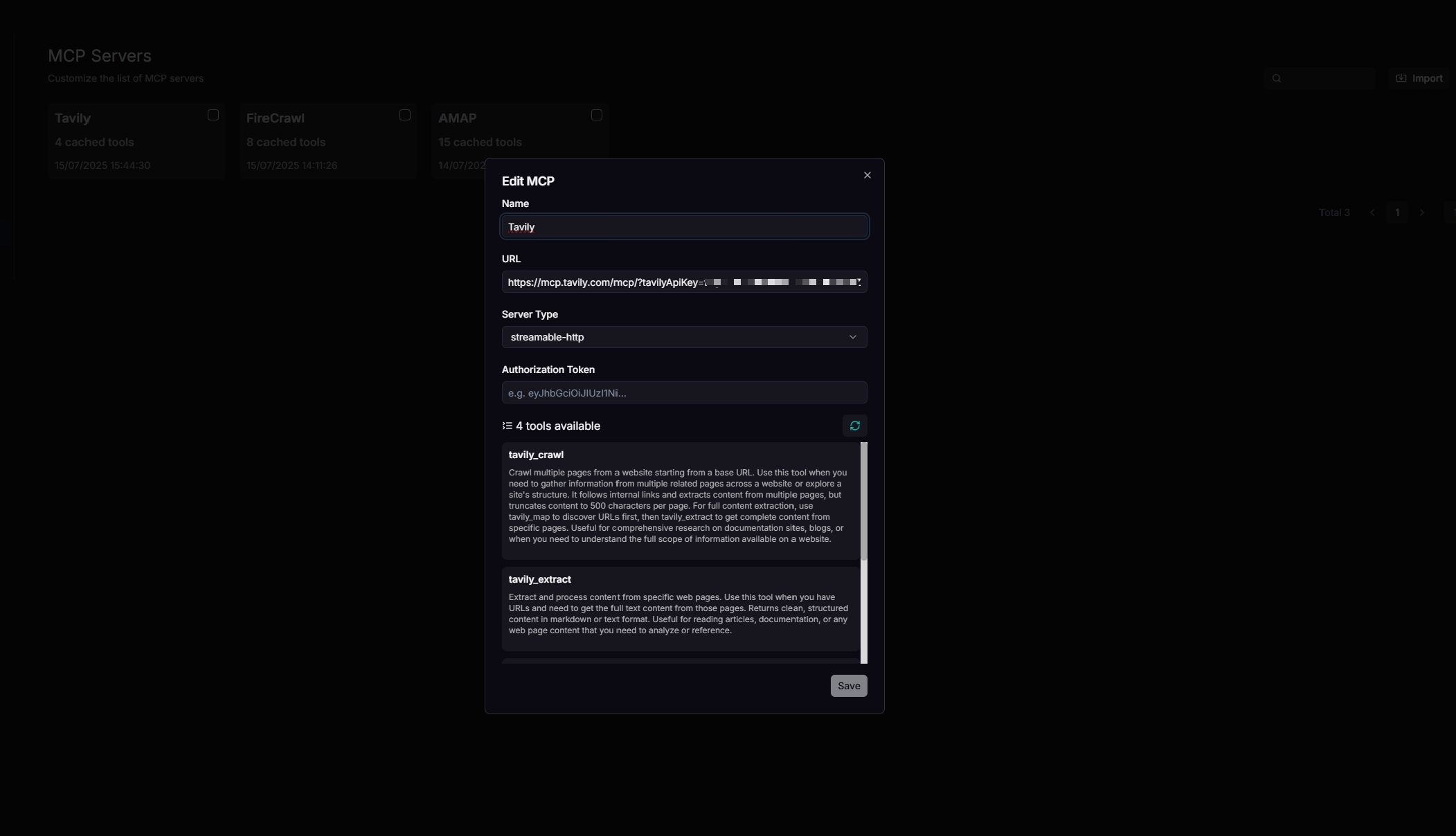
|
||
|
||
### 3. Navigate to your Agent's editing page
|
||
|
||
### 4. Connect to your MCP server
|
||
|
||
1. Click **+ Add tools**:
|
||
|
||
|
||
|
||
2. Click **MCP** to show the available MCP servers.
|
||
|
||
3. Select your MCP server:
|
||
|
||
*The target MCP server appears below your Agent component, and your Agent will autonomously decide when to invoke the available tools it offers.*
|
||
|
||
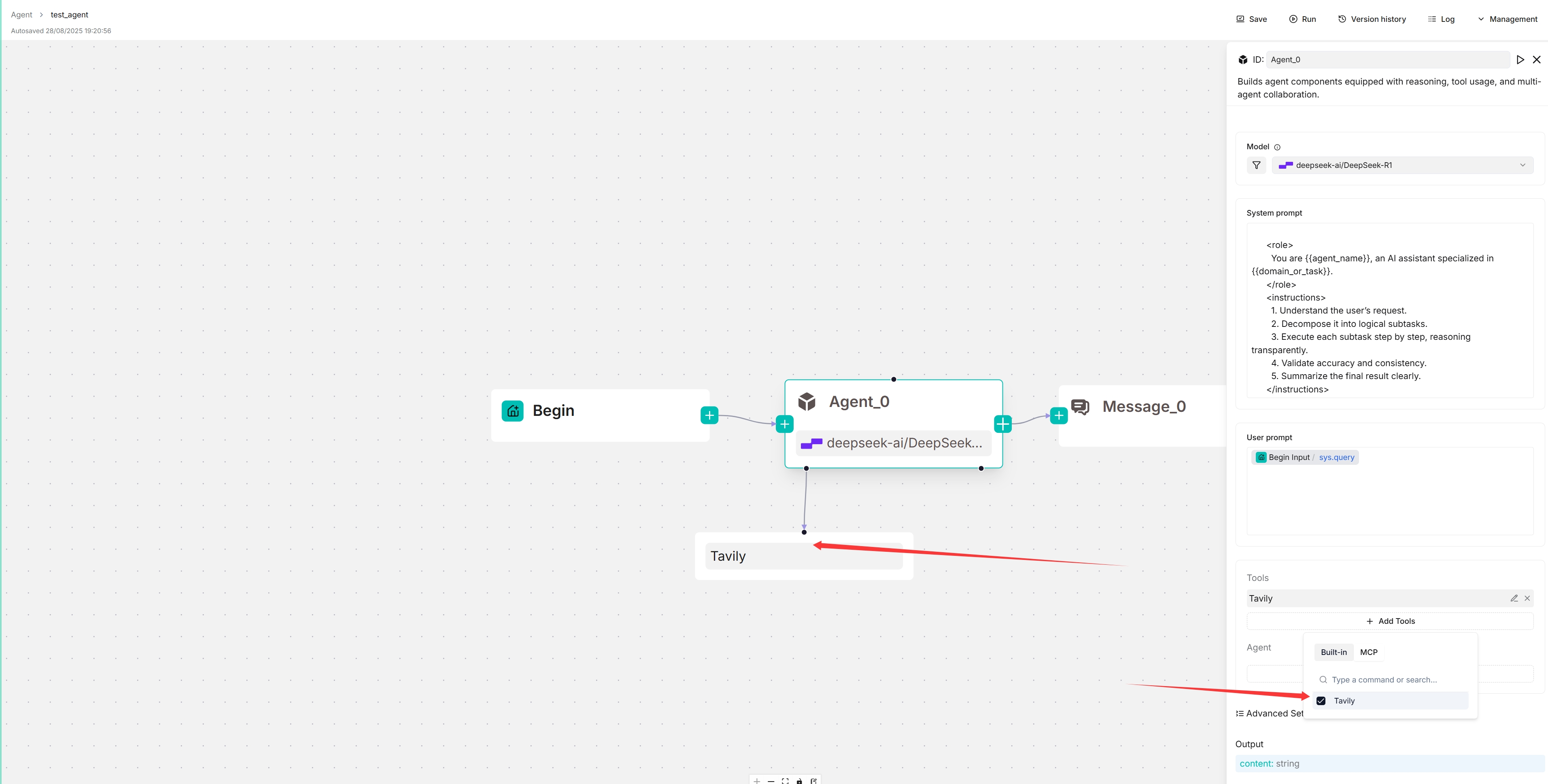
|
||
|
||
### 5. Update system prompt to specify trigger conditions (Optional)
|
||
|
||
To ensure reliable tool calls, you may specify within the system prompt which tasks should trigger each tool call.
|
||
|
||
### 6. View the availabe tools of your MCP server
|
||
|
||
On the canvas, click the newly-populated Tavily server to view and select its available tools:
|
||
|
||
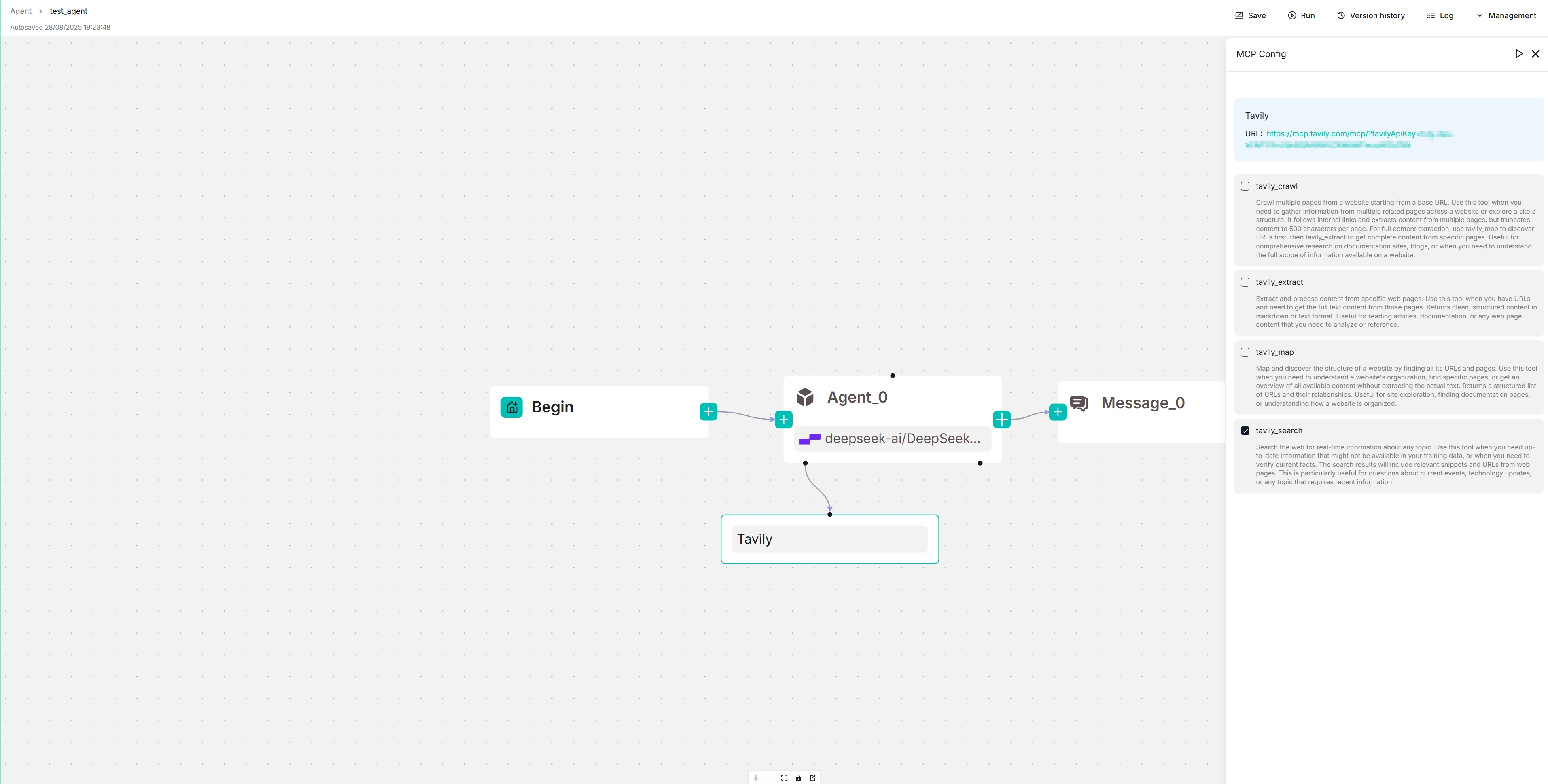
|
||
|
||
|
||
## Configurations
|
||
|
||
### Model
|
||
|
||
Click the dropdown menu of **Model** to show the model configuration window.
|
||
|
||
- **Model**: The chat model to use.
|
||
- Ensure you set the chat model correctly on the **Model providers** page.
|
||
- You can use different models for different components to increase flexibility or improve overall performance.
|
||
- **Freedom**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||
This parameter has three options:
|
||
- **Improvise**: Produces more creative responses.
|
||
- **Precise**: (Default) Produces more conservative responses.
|
||
- **Balance**: A middle ground between **Improvise** and **Precise**.
|
||
- **Temperature**: The randomness level of the model's output.
|
||
Defaults to 0.1.
|
||
- Lower values lead to more deterministic and predictable outputs.
|
||
- Higher values lead to more creative and varied outputs.
|
||
- A temperature of zero results in the same output for the same prompt.
|
||
- **Top P**: Nucleus sampling.
|
||
- Reduces the likelihood of generating repetitive or unnatural text by setting a threshold *P* and restricting the sampling to tokens with a cumulative probability exceeding *P*.
|
||
- Defaults to 0.3.
|
||
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||
- A higher **presence penalty** value results in the model being more likely to generate tokens not yet been included in the generated text.
|
||
- Defaults to 0.4.
|
||
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||
- A higher **frequency penalty** value results in the model being more conservative in its use of repeated tokens.
|
||
- Defaults to 0.7.
|
||
- **Max tokens**:
|
||
|
||
:::tip NOTE
|
||
- It is not necessary to stick with the same model for all components. If a specific model is not performing well for a particular task, consider using a different one.
|
||
- If you are uncertain about the mechanism behind **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**, simply choose one of the three options of **Preset configurations**.
|
||
:::
|
||
|
||
### System prompt
|
||
|
||
Typically, you use the system prompt to describe the task for the LLM, specify how it should respond, and outline other miscellaneous requirements. We do not plan to elaborate on this topic, as it can be as extensive as prompt engineering. However, please be aware that the system prompt is often used in conjunction with keys (variables), which serve as various data inputs for the LLM.
|
||
|
||
An **Agent** component relies on keys (variables) to specify its data inputs. Its immediate upstream component is *not* necessarily its data input, and the arrows in the workflow indicate *only* the processing sequence. Keys in a **Agent** component are used in conjunction with the system prompt to specify data inputs for the LLM. Use a forward slash `/` or the **(x)** button to show the keys to use.
|
||
|
||
#### Advanced usage
|
||
|
||
From v0.20.5 onwards, four framework-level prompt blocks are available in the **System prompt** field, enabling you to customize and *override* prompts at the framework level. Type `/` or click **(x)** to view them; they appear under the **Framework** entry in the dropdown menu.
|
||
|
||
- `task_analysis` prompt block
|
||
- This block is responsible for analyzing tasks — either a user task or a task assigned by the lead Agent when the **Agent** component is acting as a Sub-Agent.
|
||
- Reference design: [analyze_task_system.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/analyze_task_system.md) and [analyze_task_user.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/analyze_task_user.md)
|
||
- Available *only* when this **Agent** component is acting as a planner, with either tools or sub-Agents under it.
|
||
- Input variables:
|
||
- `agent_prompt`: The system prompt.
|
||
- `task`: The user prompt for either a lead Agent or a sub-Agent. The lead Agent's user prompt is defined by the user, while a sub-Agent's user prompt is defined by the lead Agent when delegating tasks.
|
||
- `tool_desc`: A description of the tools and sub_Agents that can be called.
|
||
- `context`: The operational context, which stores interactions between the Agent, tools, and sub-agents; initially empty.
|
||
- `plan_generation` prompt block
|
||
- This block creates a plan for the **Agent** component to execute next, based on the task analysis results.
|
||
- Reference design: [next_step.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/next_step.md)
|
||
- Available *only* when this **Agent** component is acting as a planner, with either tools or sub-Agents under it.
|
||
- Input variables:
|
||
- `task_analysis`: The analysis result of the current task.
|
||
- `desc`: A description of the tools or sub-Agents currently being called.
|
||
- `today`: The date of today.
|
||
- `reflection` prompt block
|
||
- This block enables the **Agent** component to reflect, improving task accuracy and efficiency.
|
||
- Reference design: [reflect.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/reflect.md)
|
||
- Available *only* when this **Agent** component is acting as a planner, with either tools or sub-Agents under it.
|
||
- Input variables:
|
||
- `goal`: The goal of the current task. It is the user prompt for either a lead Agent or a sub-Agent. The lead Agent's user prompt is defined by the user, while a sub-Agent's user prompt is defined by the lead Agent.
|
||
- `tool_calls`: The history of tool calling
|
||
- `call.name`:The name of the tool called.
|
||
- `call.result`:The result of tool calling
|
||
- `citation_guidelines` prompt block
|
||
- Reference design: [citation_prompt.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/citation_prompt.md)
|
||
|
||
*The screenshots below show the framework prompt blocks available to an **Agent** component, both as a standalone and as a planner (with a Tavily tool below):*
|
||
|
||
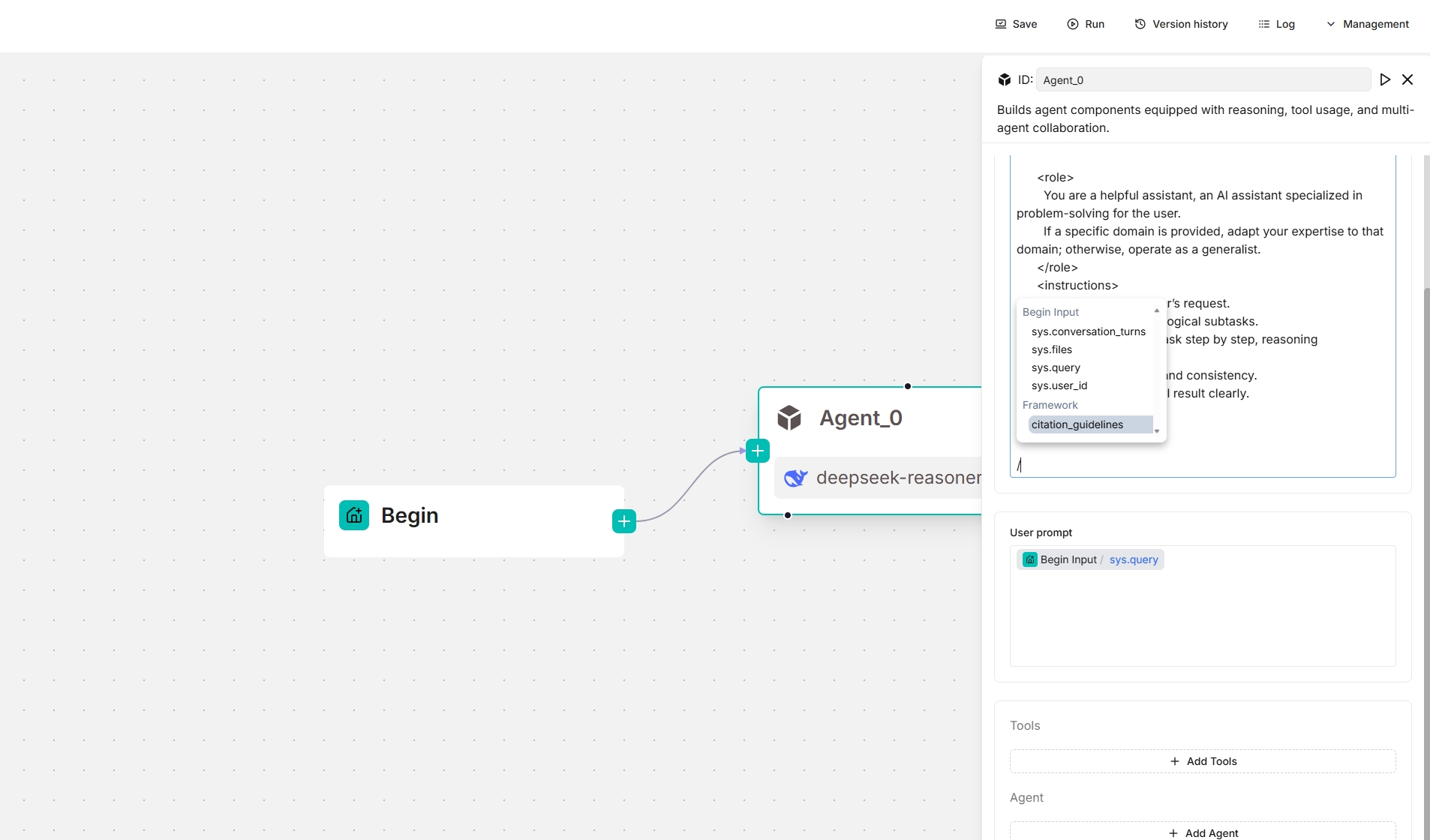
|
||
|
||
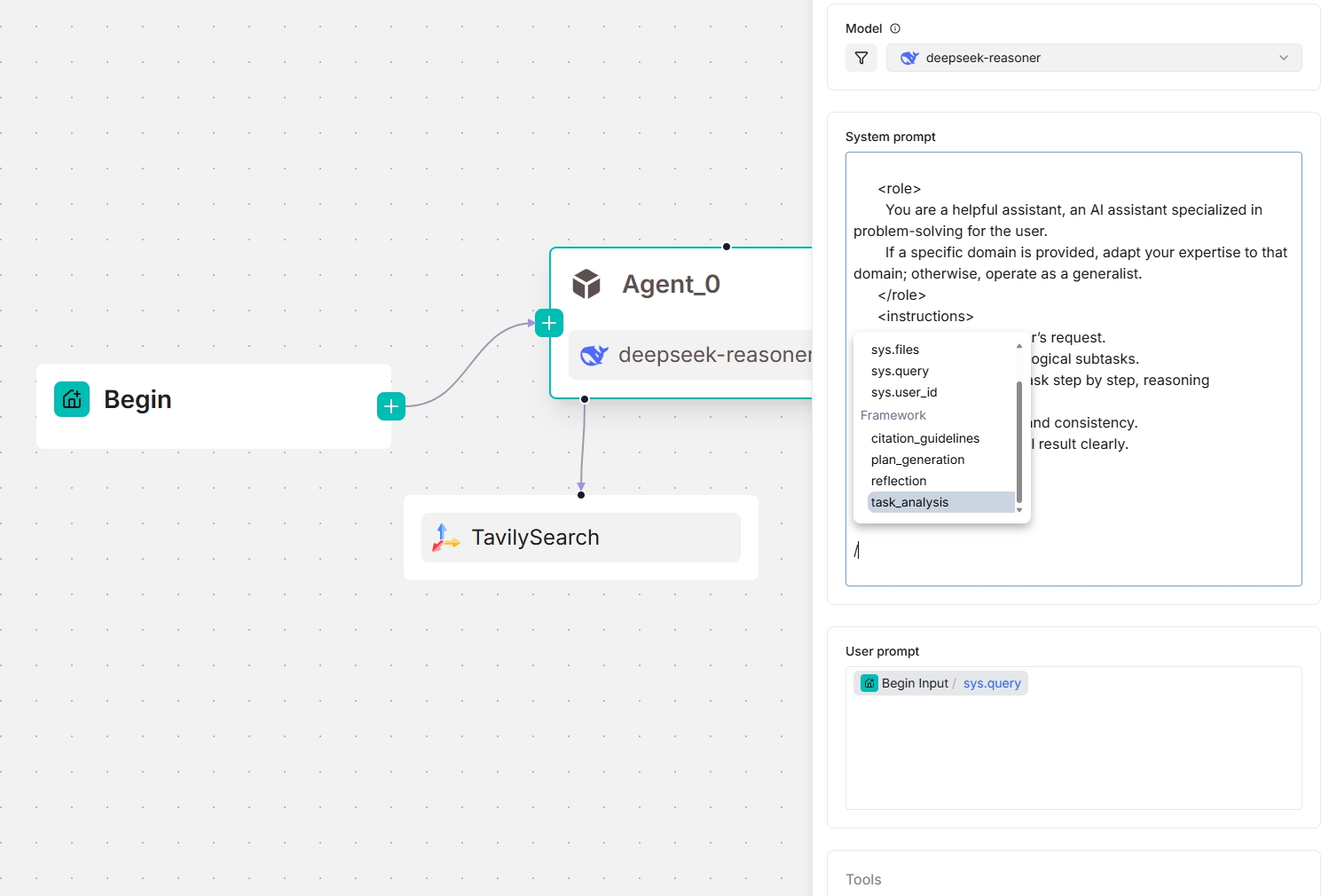
|
||
|
||
### User prompt
|
||
|
||
The user-defined prompt. Defaults to `sys.query`, the user query. As a general rule, when using the **Agent** component as a standalone module (not as a planner), you usually need to specify the corresponding **Retrieval** component’s output variable (`formalized_content`) here as part of the input to the LLM.
|
||
|
||
|
||
### Tools
|
||
|
||
You can use an **Agent** component as a collaborator that reasons and reflects with the aid of other tools; for instance, **Retrieval** can serve as one such tool for an **Agent**.
|
||
|
||
### Agent
|
||
|
||
You use an **Agent** component as a collaborator that reasons and reflects with the aid of subagents or other tools, forming a multi-agent system.
|
||
|
||
### Message window size
|
||
|
||
An integer specifying the number of previous dialogue rounds to input into the LLM. For example, if it is set to 12, the tokens from the last 12 dialogue rounds will be fed to the LLM. This feature consumes additional tokens.
|
||
|
||
:::tip IMPORTANT
|
||
This feature is used for multi-turn dialogue *only*.
|
||
:::
|
||
|
||
### Max retries
|
||
|
||
Defines the maximum number of attempts the agent will make to retry a failed task or operation before stopping or reporting failure.
|
||
|
||
### Delay after error
|
||
|
||
The waiting period in seconds that the agent observes before retrying a failed task, helping to prevent immediate repeated attempts and allowing system conditions to improve. Defaults to 1 second.
|
||
|
||
### Max reflection rounds
|
||
|
||
Defines the maximum number reflection rounds of the selected chat model. Defaults to 1 round.
|
||
|
||
:::tip NOTE
|
||
Increasing this value will significantly extend your agent's response time.
|
||
:::
|
||
|
||
### Output
|
||
|
||
The global variable name for the output of the **Agent** component, which can be referenced by other components in the workflow.
|
||
|
||
## Frequently asked questions
|
||
|
||
### Why does it take so long for my Agent to respond?
|
||
|
||
An Agent’s response time generally depends on two key factors: the LLM’s capabilities and the prompt, the latter reflecting task complexity. When using an Agent, you should always balance task demands with the LLM’s ability. See [How to balance task complexity with an Agent's performance and speed?](#how-to-balance-task-complexity-with-an-agents-performance-and-speed) for details.
|
||
|
||
## Best practices
|
||
|
||
### How to balance task complexity with an Agent’s performance and speed?
|
||
|
||
- For simple tasks, such as retrieval, rewriting, formatting, or structured data extraction, use concise prompts, remove planning or reasoning instructions, enforce output length limits, and select smaller or Turbo-class models. This significantly reduces latency and cost with minimal impact on quality.
|
||
|
||
- For complex tasks, like multi-step reasoning, cross-document synthesis, or tool-based workflows, maintain or enhance prompts that include planning, reflection, and verification steps.
|
||
|
||
- In multi-Agent orchestration systems, delegate simple subtasks to sub-Agents using smaller, faster models, and reserve more powerful models for the lead Agent to handle complexity and uncertainty.
|
||
|
||
:::tip KEY INSIGHT
|
||
Focus on minimizing output tokens — through summarization, bullet points, or explicit length limits — as this has far greater impact on reducing latency than optimizing input size.
|
||
::: |